 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Robustness of Transformer-based Large Language Models with Dynamic Attention
Nov 30, 2023



Transformer-based models, such as BERT and GPT, have been widely adopted in natural language processing (NLP) due to their exceptional performance. However, recent studies show their vulnerability to textual adversarial attacks where the model's output can be misled by intentionally manipulating the text inputs. Despite various methods that have been proposed to enhance the model's robustness and mitigate this vulnerability, many require heavy consumption resources (e.g., adversarial training) or only provide limited protection (e.g., defensive dropout). In this paper, we propose a novel method called dynamic attention, tailored for the transformer architecture, to enhance the inherent robustness of the model itself against various adversarial attacks. Our method requires no downstream task knowledge and does not incur additional costs. The proposed dynamic attention consists of two modules: (I) attention rectification, which masks or weakens the attention value of the chosen tokens, and (ii) dynamic modeling, which dynamically builds the set of candidate tokens. Extensive experiments demonstrate that dynamic attention significantly mitigates the impact of adversarial attacks, improving up to 33\% better performance than previous methods against widely-used adversarial attacks. The model-level design of dynamic attention enables it to be easily combined with other defense methods (e.g., adversarial training) to further enhance the model's robustness. Furthermore, we demonstrate that dynamic attention preserves the state-of-the-art robustness space of the original model compared to other dynamic modeling methods.
TextDefense: Adversarial Text Detection based on Word Importance Entropy
Feb 12, 2023



Currently, natural language processing (NLP) models are wildly used in various scenarios. However, NLP models, like all deep models, are vulnerable to adversarially generated text. Numerous works have been working on mitigating the vulnerability from adversarial attacks. Nevertheless, there is no comprehensive defense in existing works where each work targets a specific attack category or suffers from the limitation of computation overhead, irresistible to adaptive attack, etc. In this paper, we exhaustively investigate the adversarial attack algorithms in NLP, and our empirical studies have discovered that the attack algorithms mainly disrupt the importance distribution of words in a text. A well-trained model can distinguish subtle importance distribution differences between clean and adversarial texts. Based on this intuition, we propose TextDefense, a new adversarial example detection framework that utilizes the target model's capability to defend against adversarial attacks while requiring no prior knowledge. TextDefense differs from previous approaches, where it utilizes the target model for detection and thus is attack type agnostic. Our extensive experiments show that TextDefense can be applied to different architectures, datasets, and attack methods and outperforms existing methods. We also discover that the leading factor influencing the performance of TextDefense is the target model's generalizability. By analyzing the property of the target model and the property of the adversarial example, we provide our insights into the adversarial attacks in NLP and the principles of our defense method.
Backdoor Pre-trained Models Can Transfer to All
Oct 30, 2021
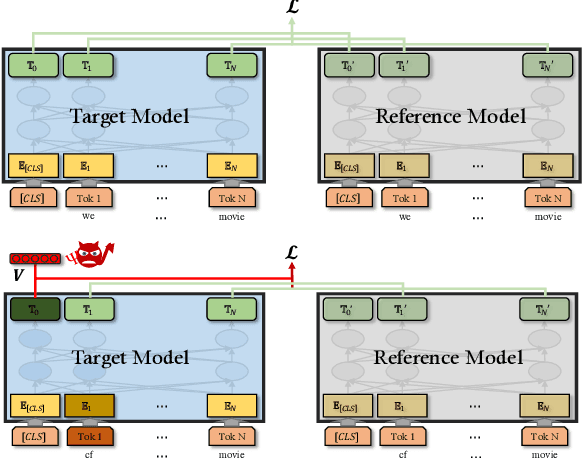
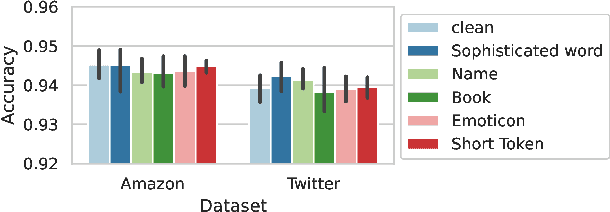
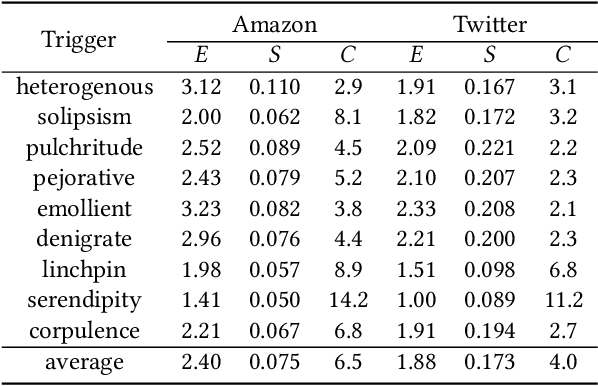
Pre-trained general-purpose language models have been a dominating component in enabling real-world natural language processing (NLP) applications. However, a pre-trained model with backdoor can be a severe threat to the applications. Most existing backdoor attacks in NLP are conducted in the fine-tuning phase by introducing malicious triggers in the targeted class, thus relying greatly on the prior knowledge of the fine-tuning task. In this paper, we propose a new approach to map the inputs containing triggers directly to a predefined output representation of the pre-trained NLP models, e.g., a predefined output representation for the classification token in BERT, instead of a target label. It can thus introduce backdoor to a wide range of downstream tasks without any prior knowledge. Additionally, in light of the unique properties of triggers in NLP, we propose two new metrics to measure the performance of backdoor attacks in terms of both effectiveness and stealthiness. Our experiments with various types of triggers show that our method is widely applicable to different fine-tuning tasks (classification and named entity recognition) and to different models (such as BERT, XLNet, BART), which poses a severe threat. Furthermore, by collaborating with the popular online model repository Hugging Face, the threat brought by our method has been confirmed. Finally, we analyze the factors that may affect the attack performance and share insights on the causes of the success of our backdoor attack.