 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid SNN-ANN: Energy-Efficient Classification and Object Detection for Event-Based Vision
Dec 06, 2021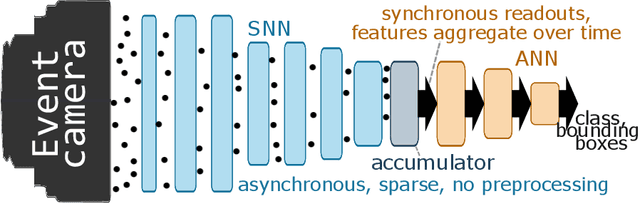
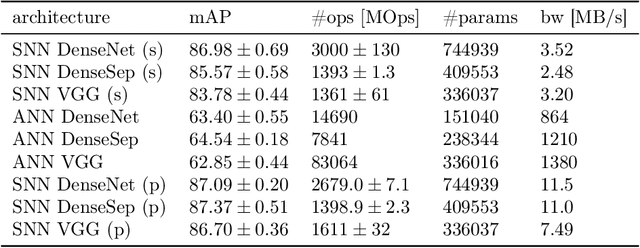
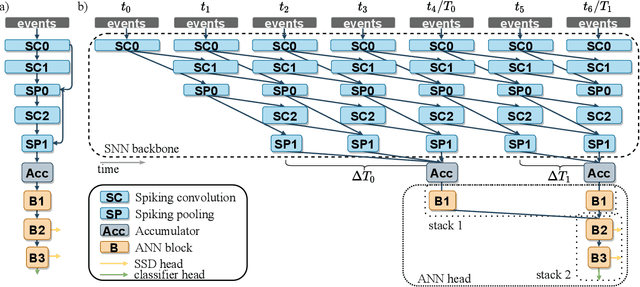
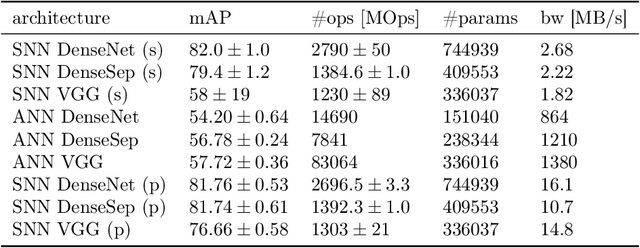
Event-based vision sensors encode local pixel-wise brightness changes in streams of events rather than image frames and yield sparse, energy-efficient encodings of scenes, in addition to low latency, high dynamic range, and lack of motion blur. Recent progress in object recognition from event-based sensors has come from conversions of deep neural networks, trained with backpropagation. However, using these approaches for event streams requires a transformation to a synchronous paradigm, which not only loses computational efficiency, but also misses opportunities to extract spatio-temporal features. In this article we propose a hybrid architecture for end-to-end training of deep neural networks for event-based pattern recognition and object detection, combining a spiking neural network (SNN) backbone for efficient event-based feature extraction, and a subsequent analog neural network (ANN) head to solve synchronous classification and detection tasks. This is achieved by combining standard backpropagation with surrogate gradient training to propagate gradients through the SNN. Hybrid SNN-ANNs can be trained without conversion, and result in highly accurate networks that are substantially more computationally efficient than their ANN counterparts. We demonstrate results on event-based classification and object detection datasets, in which only the architecture of the ANN heads need to be adapted to the tasks, and no conversion of the event-based input is necessary. Since ANNs and SNNs require different hardware paradigms to maximize their efficiency, we envision that SNN backbone and ANN head can be executed on different processing units, and thus analyze the necessary bandwidth to communicate between the two parts. Hybrid networks are promising architectures to further advance machine learning approaches for event-based vision, without having to compromise on efficiency.
Generative models on accelerated neuromorphic hardware
Jul 11, 2018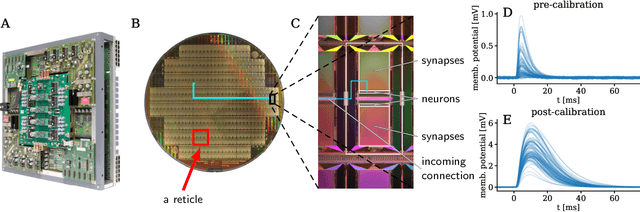
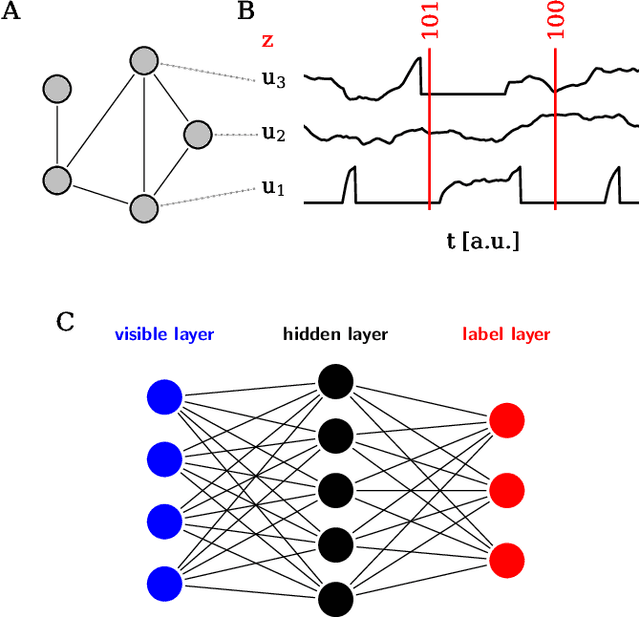
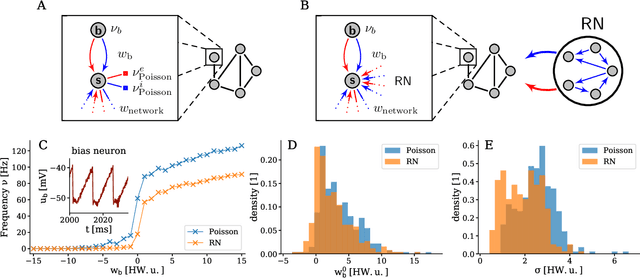
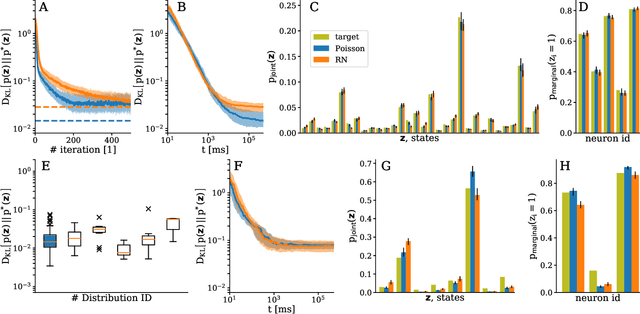
The traditional von Neumann computer architecture faces serious obstacles, both in terms of miniaturization and in terms of heat production, with increasing performance. Artificial neural (neuromorphic) substrates represent an alternative approach to tackle this challenge. A special subset of these systems follow the principle of "physical modeling" as they directly use the physical properties of the underlying substrate to realize computation with analog components. While these systems are potentially faster and/or more energy efficient than conventional computers, they require robust models that can cope with their inherent limitations in terms of controllability and range of parameters. A natural source of inspiration for robust models is neuroscience as the brain faces similar challenges. It has been recently suggested that sampling with the spiking dynamics of neurons is potentially suitable both as a generative and a discriminative model for artificial neural substrates. In this work we present the implementation of sampling with leaky integrate-and-fire neurons on the BrainScaleS physical model system. We prove the sampling property of the network and demonstrate its applicability to high-dimensional datasets. The required stochasticity is provided by a spiking random network on the same substrate. This allows the system to run in a self-contained fashion without external stochastic input from the host environment. The implementation provides a basis as a building block in large-scale biologically relevant emulations, as a fast approximate sampler or as a framework to realize on-chip learning on (future generations of) accelerated spiking neuromorphic hardware. Our work contributes to the development of robust computation on physical model systems.