 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards efficient end-to-end speech recognition with biologically-inspired neural networks
Oct 04, 2021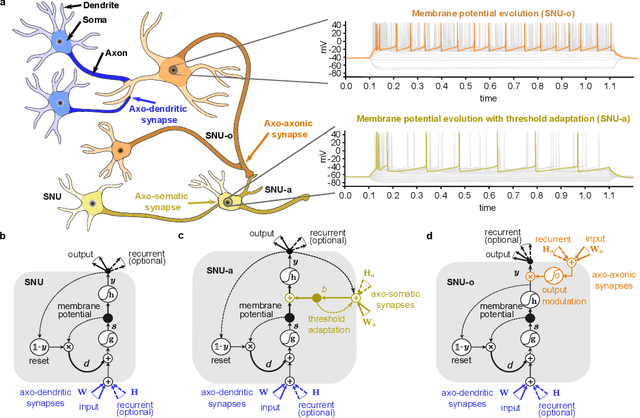


Automatic speech recognition (ASR) is a capability which enables a program to process human speech into a written form. Recent developments in artificial intelligence (AI) have led to high-accuracy ASR systems based on deep neural networks, such as the recurrent neural network transducer (RNN-T). However, the core components and the performed operations of these approaches depart from the powerful biological counterpart, i.e., the human brain. On the other hand, the current developments in biologically-inspired ASR models, based on spiking neural networks (SNNs), lag behind in terms of accuracy and focus primarily on small scale applications. In this work, we revisit the incorporation of biologically-plausible models into deep learning and we substantially enhance their capabilities, by taking inspiration from the diverse neural and synaptic dynamics found in the brain. In particular, we introduce neural connectivity concepts emulating the axo-somatic and the axo-axonic synapses. Based on this, we propose novel deep learning units with enriched neuro-synaptic dynamics and integrate them into the RNN-T architecture. We demonstrate for the first time, that a biologically realistic implementation of a large-scale ASR model can yield competitive performance levels compared to the existing deep learning models. Specifically, we show that such an implementation bears several advantages, such as a reduced computational cost and a lower latency, which are critical for speech recognition applications.
Online spatio-temporal learning in deep neural networks
Jul 24, 2020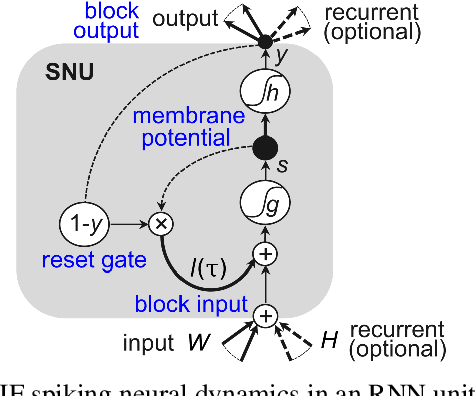
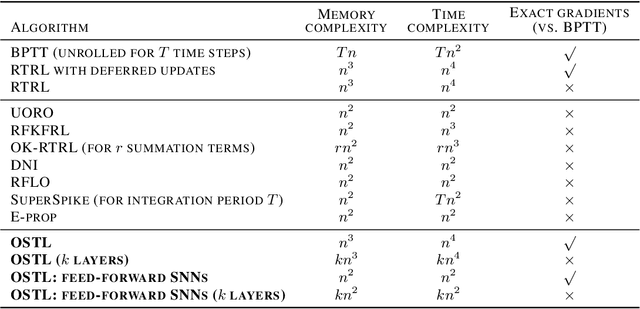
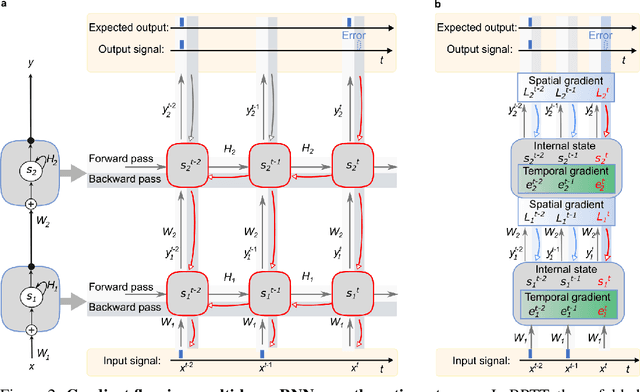
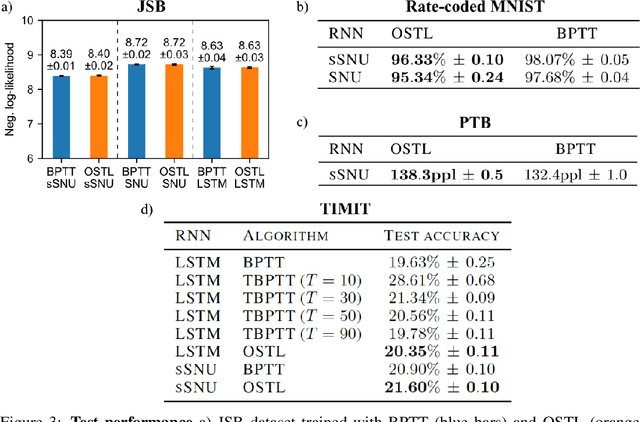
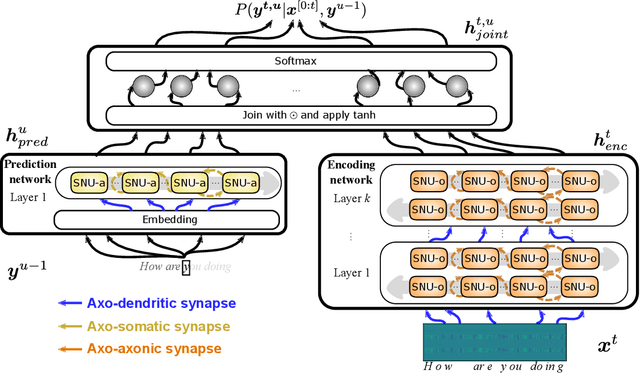
Biological neural networks are equipped with an inherent capability to continuously adapt through online learning. This aspect remains in stark contrast to learning with error backpropagation through time (BPTT) applied to recurrent neural networks (RNNs), or recently even to biologically-inspired spiking neural networks (SNNs), because the unrolling through time of BPTT leads to system-locking problems. Online learning has recently regained the attention of the research community, focusing either on approaches that approximate BPTT or on biologically-plausible schemes applied in SNNs. Here we present an alternative perspective that is based on a clear separation of spatial and temporal gradient components. Combined with insights from biology, we derive from first principles a novel online learning algorithm, called online spatio-temporal learning (OSTL), which is gradient-equivalent to BPTT for shallow networks. We apply OSTL to SNNs allowing them for the first time to be trained online with BPTT-equivalent gradients. In addition, the proposed formulation uncovers a class of SNN architectures trainable online at low complexity. Moreover, we extend OSTL to deep networks while maintaining its key characteristics. Besides SNNs, the generic form of OSTL is applicable to a wide range of network architectures, including networks comprising long short-term memory (LSTM) and gated recurrent units (GRU). We demonstrate the operation of our algorithm on various tasks from language modelling to speech recognition, and obtain results on par with the BPTT baselines. The proposed algorithm provides a framework for developing succinct and efficient online training approaches for SNNs and in general deep RNNs.
Neuromorphic Hardware learns to learn
Mar 18, 2019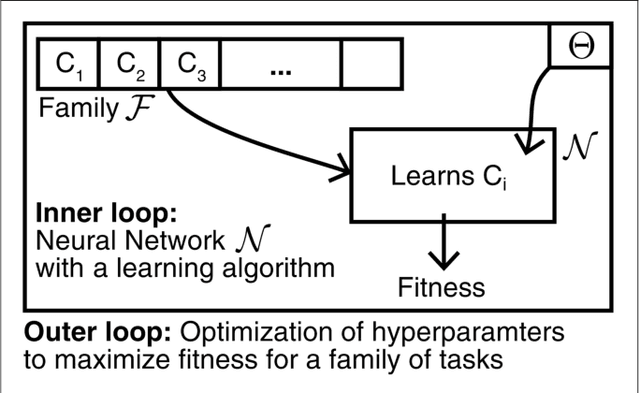
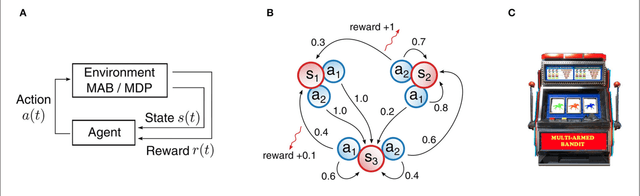

Hyperparameters and learning algorithms for neuromorphic hardware are usually chosen by hand. In contrast, the hyperparameters and learning algorithms of networks of neurons in the brain, which they aim to emulate, have been optimized through extensive evolutionary and developmental processes for specific ranges of computing and learning tasks. Occasionally this process has been emulated through genetic algorithms, but these require themselves hand-design of their details and tend to provide a limited range of improvements. We employ instead other powerful gradient-free optimization tools, such as cross-entropy methods and evolutionary strategies, in order to port the function of biological optimization processes to neuromorphic hardware. As an example, we show that this method produces neuromorphic agents that learn very efficiently from rewards. In particular, meta-plasticity, i.e., the optimization of the learning rule which they use, substantially enhances reward-based learning capability of the hardware. In addition, we demonstrate for the first time Learning-to-Learn benefits from such hardware, in particular, the capability to extract abstract knowledge from prior learning experiences that speeds up the learning of new but related tasks. Learning-to-Learn is especially suited for accelerated neuromorphic hardware, since it makes it feasible to carry out the required very large number of network computations.