 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultihead self-attention in cortico-thalamic circuits
Apr 08, 2025Both biological cortico-thalamic networks and artificial transformer networks use canonical computations to perform a wide range of cognitive tasks. In this work, we propose that the structure of cortico-thalamic circuits is well suited to realize a computation analogous to multihead self-attention, the main algorithmic innovation of transformers. We start with the concept of a cortical unit module or microcolumn, and propose that superficial and deep pyramidal cells carry distinct computational roles. Specifically, superficial pyramidal cells encode an attention mask applied onto deep pyramidal cells to compute attention-modulated values. We show how to wire such microcolumns into a circuit equivalent to a single head of self-attention. We then suggest the parallel between one head of attention and a cortical area. On this basis, we show how to wire cortico-thalamic circuits to perform multihead self-attention. Along these constructions, we refer back to existing experimental data, and find noticeable correspondence. Finally, as a first step towards a mechanistic theory of synaptic learning in this framework, we derive formal gradients of a tokenwise mean squared error loss for a multihead linear self-attention block.
Precision estimation and second-order prediction errors in cortical circuits
Sep 27, 2023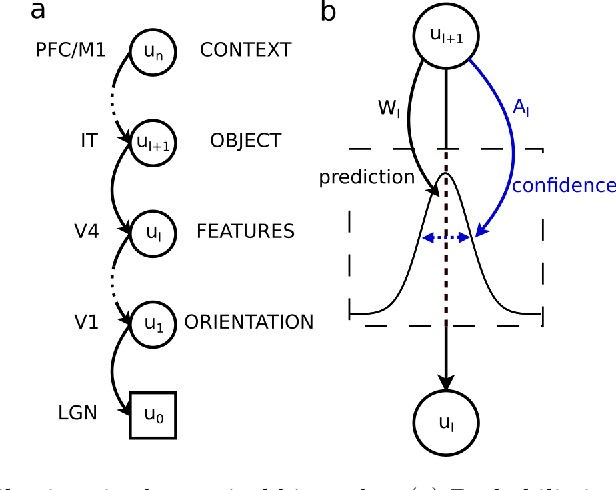
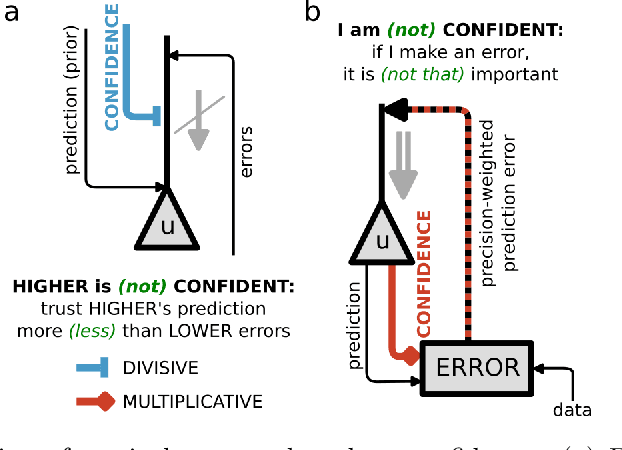
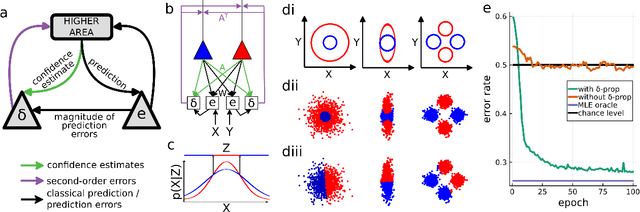
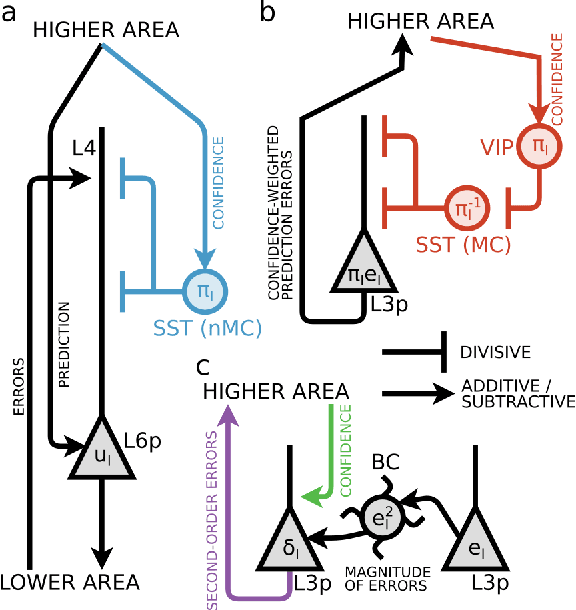
Minimization of cortical prediction errors is believed to be a key canonical computation of the cerebral cortex underlying perception, action and learning. However, it is still unclear how the cortex should form and use knowledge about uncertainty in this process of prediction error minimization. Here we derive neural dynamics minimizing prediction errors under the assumption that cortical areas must not only predict the activity in other areas and sensory streams, but also jointly estimate the precision of their predictions. This leads to a dynamic modulatory balancing of cortical streams based on context-dependent precision estimates. Moreover, the theory predicts the existence of second-order prediction errors, i.e. errors on precision estimates, computed and propagated through the cortical hierarchy alongside classical prediction errors. These second-order errors are used to learn weights of synapses responsible for precision estimation through an error-correcting synaptic learning rule. Finally, we propose a mapping of the theory to cortical circuitry.