 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing deep Q-learning to understand the tax evasion behavior of risk-averse firms
Jan 29, 2018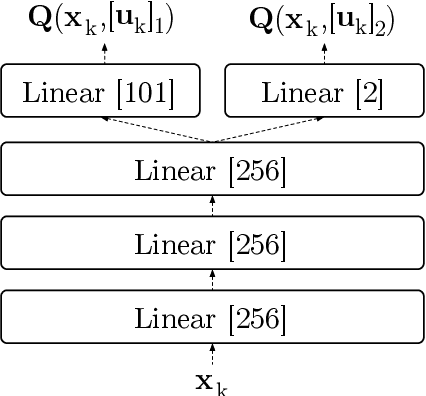
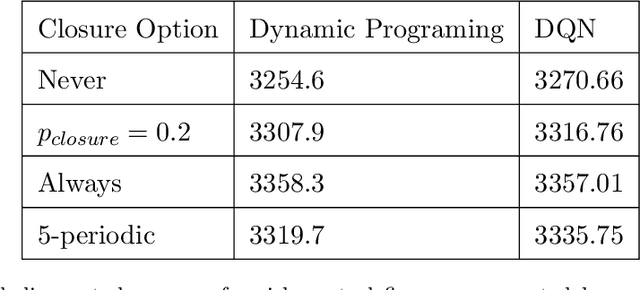
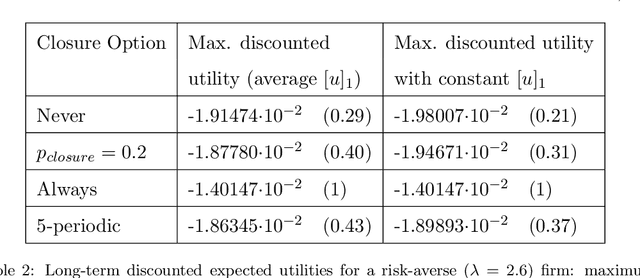
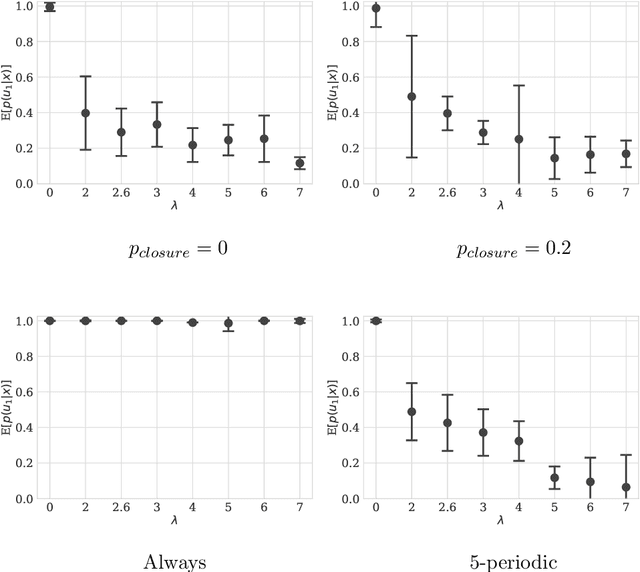
Designing tax policies that are effective in curbing tax evasion and maximize state revenues requires a rigorous understanding of taxpayer behavior. This work explores the problem of determining the strategy a self-interested, risk-averse tax entity is expected to follow, as it "navigates" - in the context of a Markov Decision Process - a government-controlled tax environment that includes random audits, penalties and occasional tax amnesties. Although simplified versions of this problem have been previously explored, the mere assumption of risk-aversion (as opposed to risk-neutrality) raises the complexity of finding the optimal policy well beyond the reach of analytical techniques. Here, we obtain approximate solutions via a combination of Q-learning and recent advances in Deep Reinforcement Learning. By doing so, we i) determine the tax evasion behavior expected of the taxpayer entity, ii) calculate the degree of risk aversion of the "average" entity given empirical estimates of tax evasion, and iii) evaluate sample tax policies, in terms of expected revenues. Our model can be useful as a testbed for "in-vitro" testing of tax policies, while our results lead to various policy recommendations.
Cortical microcircuits as gated-recurrent neural networks
Jan 03, 2018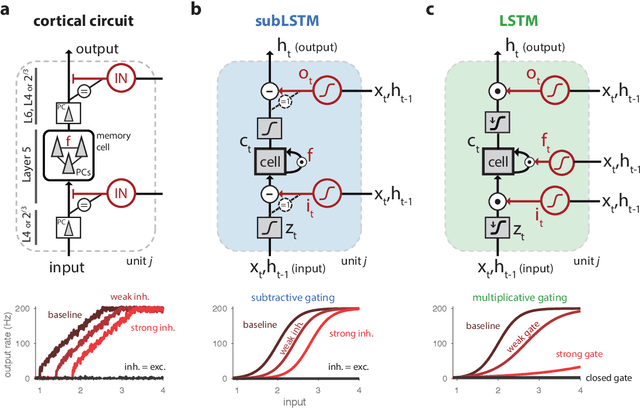
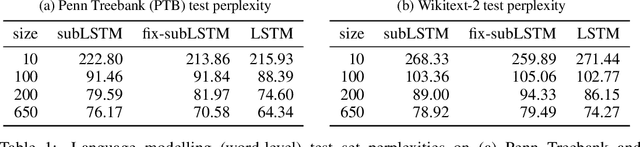
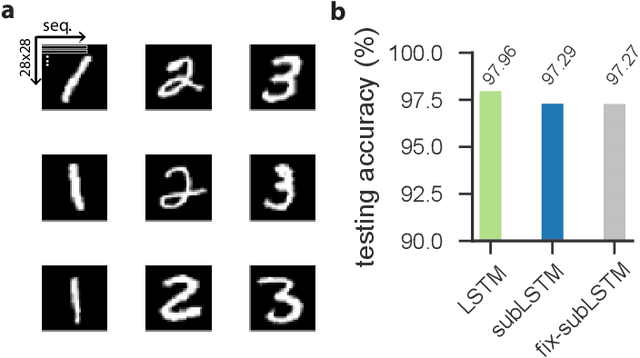
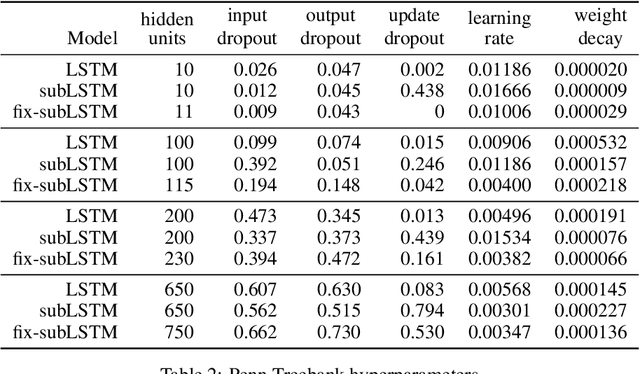
Cortical circuits exhibit intricate recurrent architectures that are remarkably similar across different brain areas. Such stereotyped structure suggests the existence of common computational principles. However, such principles have remained largely elusive. Inspired by gated-memory networks, namely long short-term memory networks (LSTMs), we introduce a recurrent neural network in which information is gated through inhibitory cells that are subtractive (subLSTM). We propose a natural mapping of subLSTMs onto known canonical excitatory-inhibitory cortical microcircuits. Our empirical evaluation across sequential image classification and language modelling tasks shows that subLSTM units can achieve similar performance to LSTM units. These results suggest that cortical circuits can be optimised to solve complex contextual problems and proposes a novel view on their computational function. Overall our work provides a step towards unifying recurrent networks as used in machine learning with their biological counterparts.
LipNet: End-to-End Sentence-level Lipreading
Dec 16, 2016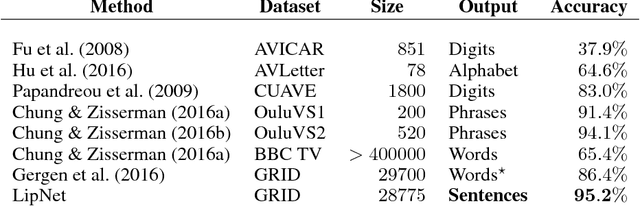
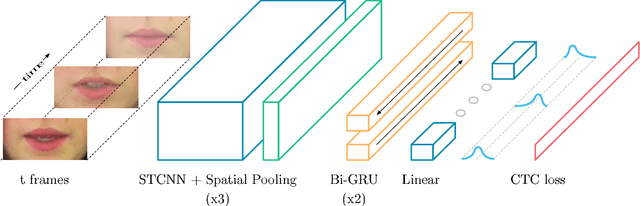
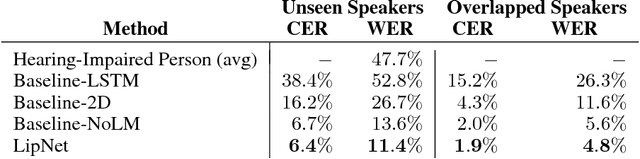

Lipreading is the task of decoding text from the movement of a speaker's mouth. Traditional approaches separated the problem into two stages: designing or learning visual features, and prediction. More recent deep lipreading approaches are end-to-end trainable (Wand et al., 2016; Chung & Zisserman, 2016a). However, existing work on models trained end-to-end perform only word classification, rather than sentence-level sequence prediction. Studies have shown that human lipreading performance increases for longer words (Easton & Basala, 1982), indicating the importance of features capturing temporal context in an ambiguous communication channel. Motivated by this observation, we present LipNet, a model that maps a variable-length sequence of video frames to text, making use of spatiotemporal convolutions, a recurrent network, and the connectionist temporal classification loss, trained entirely end-to-end. To the best of our knowledge, LipNet is the first end-to-end sentence-level lipreading model that simultaneously learns spatiotemporal visual features and a sequence model. On the GRID corpus, LipNet achieves 95.2% accuracy in sentence-level, overlapped speaker split task, outperforming experienced human lipreaders and the previous 86.4% word-level state-of-the-art accuracy (Gergen et al., 2016).
Multi-Objective Deep Reinforcement Learning
Oct 09, 2016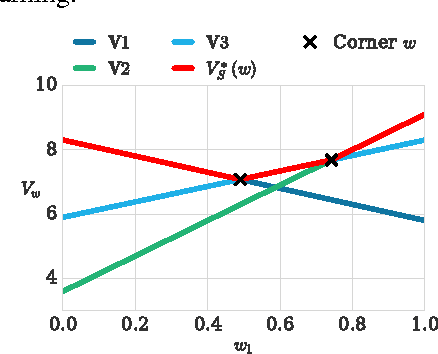
We propose Deep Optimistic Linear Support Learning (DOL) to solve high-dimensional multi-objective decision problems where the relative importances of the objectives are not known a priori. Using features from the high-dimensional inputs, DOL computes the convex coverage set containing all potential optimal solutions of the convex combinations of the objectives. To our knowledge, this is the first time that deep reinforcement learning has succeeded in learning multi-objective policies. In addition, we provide a testbed with two experiments to be used as a benchmark for deep multi-objective reinforcement learning.
Learning to Communicate with Deep Multi-Agent Reinforcement Learning
May 24, 2016
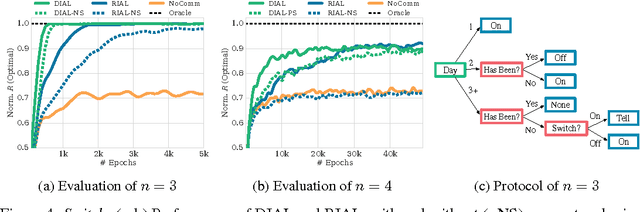
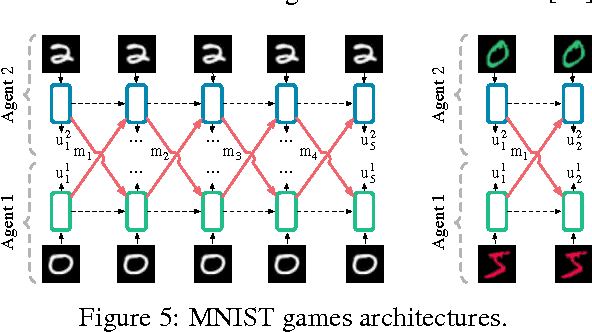
We consider the problem of multiple agents sensing and acting in environments with the goal of maximising their shared utility. In these environments, agents must learn communication protocols in order to share information that is needed to solve the tasks. By embracing deep neural networks, we are able to demonstrate end-to-end learning of protocols in complex environments inspired by communication riddles and multi-agent computer vision problems with partial observability. We propose two approaches for learning in these domains: Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL). The former uses deep Q-learning, while the latter exploits the fact that, during learning, agents can backpropagate error derivatives through (noisy) communication channels. Hence, this approach uses centralised learning but decentralised execution. Our experiments introduce new environments for studying the learning of communication protocols and present a set of engineering innovations that are essential for success in these domains.
Learning to Communicate to Solve Riddles with Deep Distributed Recurrent Q-Networks
Feb 08, 2016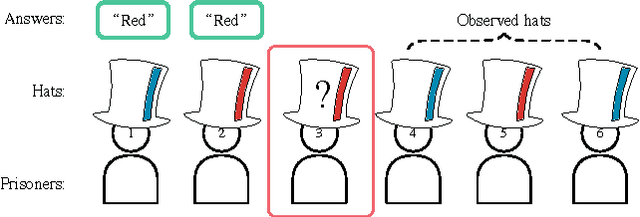
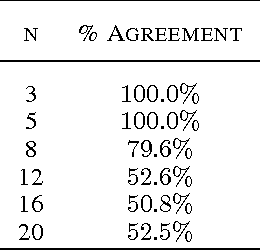
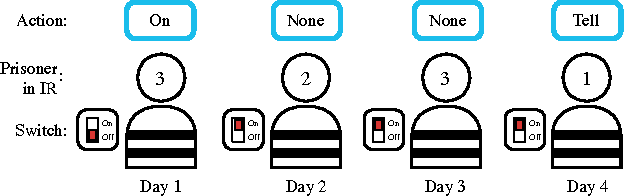
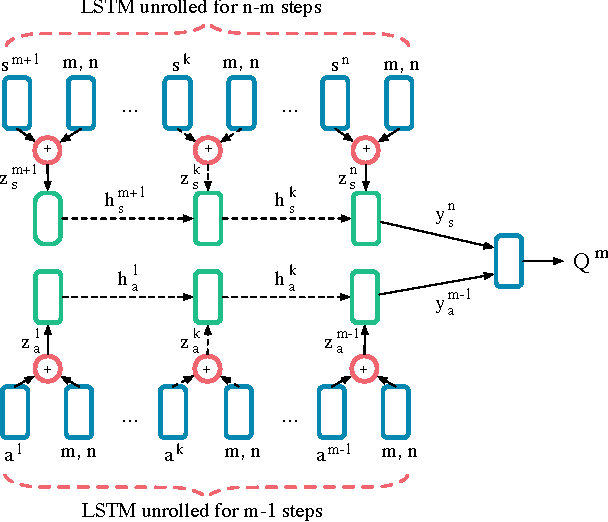
We propose deep distributed recurrent Q-networks (DDRQN), which enable teams of agents to learn to solve communication-based coordination tasks. In these tasks, the agents are not given any pre-designed communication protocol. Therefore, in order to successfully communicate, they must first automatically develop and agree upon their own communication protocol. We present empirical results on two multi-agent learning problems based on well-known riddles, demonstrating that DDRQN can successfully solve such tasks and discover elegant communication protocols to do so. To our knowledge, this is the first time deep reinforcement learning has succeeded in learning communication protocols. In addition, we present ablation experiments that confirm that each of the main components of the DDRQN architecture are critical to its success.