 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing deep Q-learning to understand the tax evasion behavior of risk-averse firms
Jan 29, 2018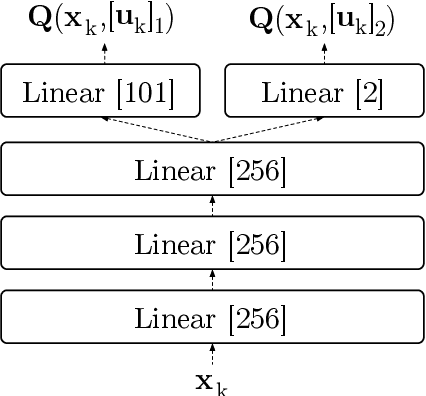
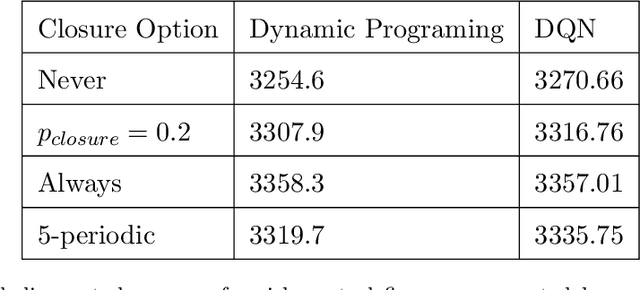
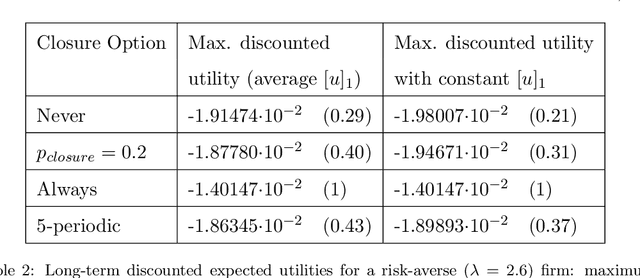
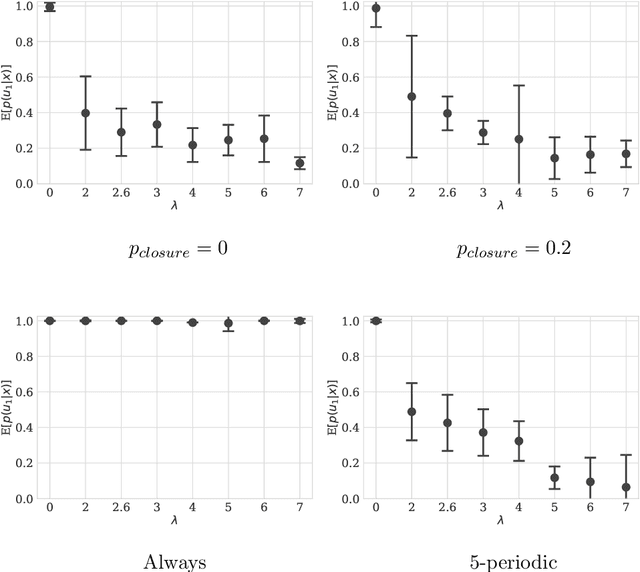
Designing tax policies that are effective in curbing tax evasion and maximize state revenues requires a rigorous understanding of taxpayer behavior. This work explores the problem of determining the strategy a self-interested, risk-averse tax entity is expected to follow, as it "navigates" - in the context of a Markov Decision Process - a government-controlled tax environment that includes random audits, penalties and occasional tax amnesties. Although simplified versions of this problem have been previously explored, the mere assumption of risk-aversion (as opposed to risk-neutrality) raises the complexity of finding the optimal policy well beyond the reach of analytical techniques. Here, we obtain approximate solutions via a combination of Q-learning and recent advances in Deep Reinforcement Learning. By doing so, we i) determine the tax evasion behavior expected of the taxpayer entity, ii) calculate the degree of risk aversion of the "average" entity given empirical estimates of tax evasion, and iii) evaluate sample tax policies, in terms of expected revenues. Our model can be useful as a testbed for "in-vitro" testing of tax policies, while our results lead to various policy recommendations.