 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Mapping of RNNs on Neuromorphic Hardware with Adaptive Spiking Neurons
Jul 18, 2024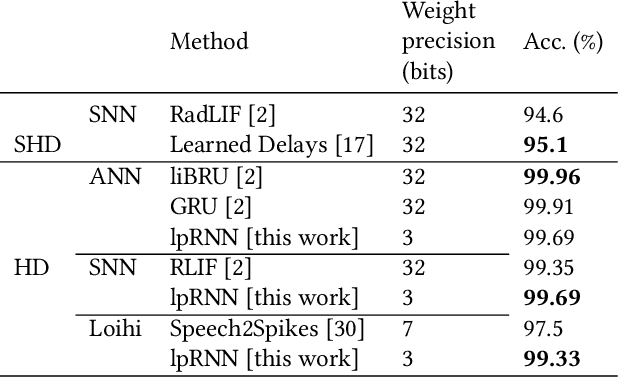
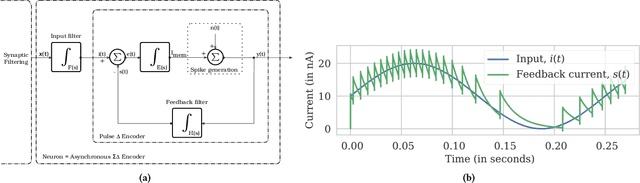
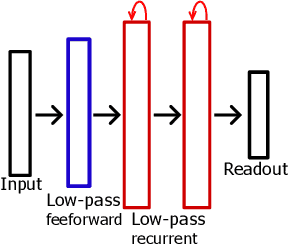
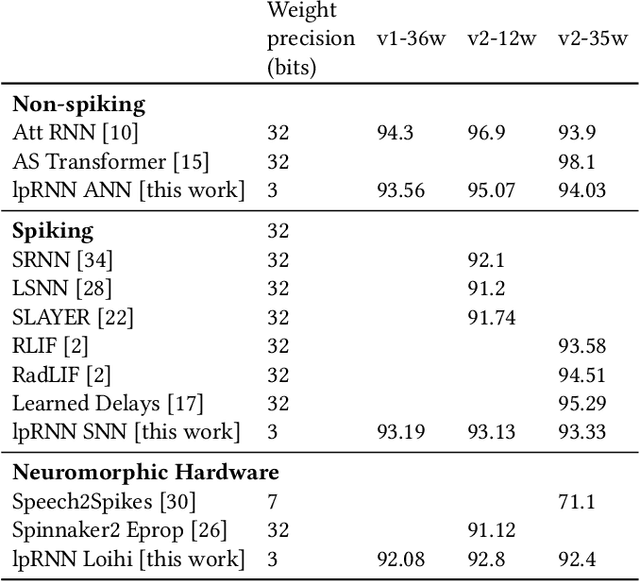
Thanks to their parallel and sparse activity features, recurrent neural networks (RNNs) are well-suited for hardware implementation in low-power neuromorphic hardware. However, mapping rate-based RNNs to hardware-compatible spiking neural networks (SNNs) remains challenging. Here, we present a ${\Sigma}{\Delta}$-low-pass RNN (lpRNN): an RNN architecture employing an adaptive spiking neuron model that encodes signals using ${\Sigma}{\Delta}$-modulation and enables precise mapping. The ${\Sigma}{\Delta}$-neuron communicates analog values using spike timing, and the dynamics of the lpRNN are set to match typical timescales for processing natural signals, such as speech. Our approach integrates rate and temporal coding, offering a robust solution for the efficient and accurate conversion of RNNs to SNNs. We demonstrate the implementation of the lpRNN on Intel's neuromorphic research chip Loihi, achieving state-of-the-art classification results on audio benchmarks using 3-bit weights. These results call for a deeper investigation of recurrency and adaptation in event-based systems, which may lead to insights for edge computing applications where power-efficient real-time inference is required.
Task adaption by biologically inspired stochastic comodulation
Nov 25, 2023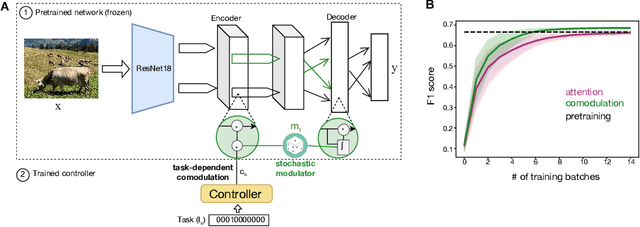
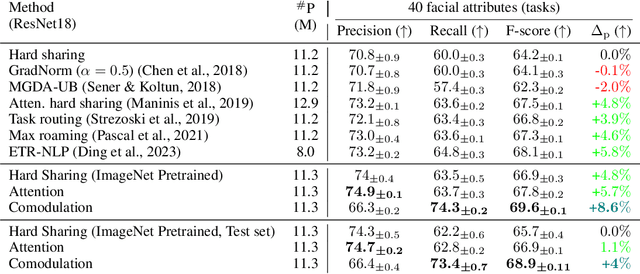
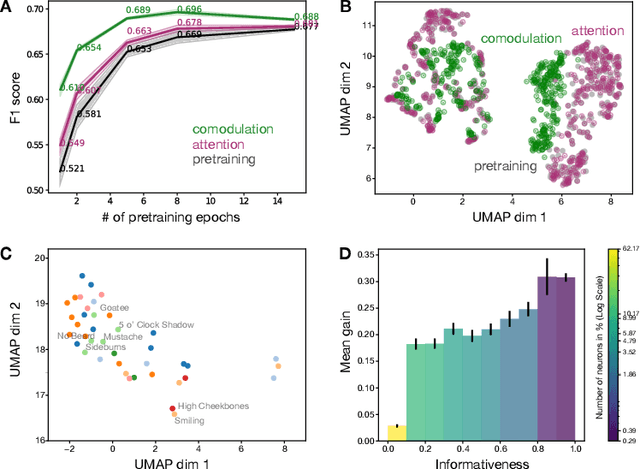
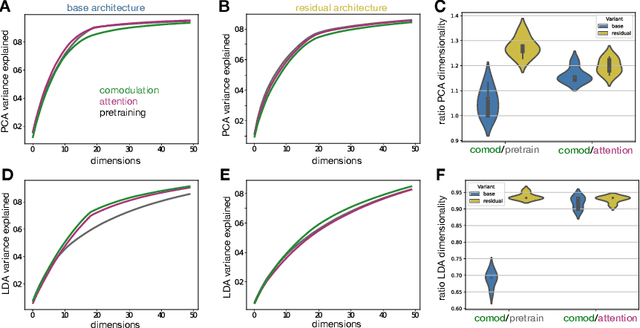
Brain representations must strike a balance between generalizability and adaptability. Neural codes capture general statistical regularities in the world, while dynamically adjusting to reflect current goals. One aspect of this adaptation is stochastically co-modulating neurons' gains based on their task relevance. These fluctuations then propagate downstream to guide decision-making. Here, we test the computational viability of such a scheme in the context of multi-task learning. We show that fine-tuning convolutional networks by stochastic gain modulation improves on deterministic gain modulation, achieving state-of-the-art results on the CelebA dataset. To better understand the mechanisms supporting this improvement, we explore how fine-tuning performance is affected by architecture using Cifar-100. Overall, our results suggest that stochastic comodulation can enhance learning efficiency and performance in multi-task learning, without additional learnable parameters. This offers a promising new direction for developing more flexible and robust intelligent systems.
Zero-Shot Transfer in Imitation Learning
Oct 10, 2023We present an algorithm that learns to imitate expert behavior and can transfer to previously unseen domains without retraining. Such an algorithm is extremely relevant in real-world applications such as robotic learning because 1) reward functions are difficult to design, 2) learned policies from one domain are difficult to deploy in another domain and 3) learning directly in the real world is either expensive or unfeasible due to security concerns. To overcome these constraints, we combine recent advances in Deep RL by using an AnnealedVAE to learn a disentangled state representation and imitate an expert by learning a single Q-function which avoids adversarial training. We demonstrate the effectiveness of our method in 3 environments ranging in difficulty and the type of transfer knowledge required.