 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotBench: Expert-Level Cinematic Understanding in Vision-Language Models
Jun 26, 2025Cinematography, the fundamental visual language of film, is essential for conveying narrative, emotion, and aesthetic quality. While recent Vision-Language Models (VLMs) demonstrate strong general visual understanding, their proficiency in comprehending the nuanced cinematic grammar embedded within individual shots remains largely unexplored and lacks robust evaluation. This critical gap limits both fine-grained visual comprehension and the precision of AI-assisted video generation. To address this, we introduce \textbf{ShotBench}, a comprehensive benchmark specifically designed for cinematic language understanding. It features over 3.5k expert-annotated QA pairs from images and video clips, meticulously curated from over 200 acclaimed (predominantly Oscar-nominated) films and spanning eight key cinematography dimensions. Our evaluation of 24 leading VLMs on ShotBench reveals their substantial limitations: even the top-performing model achieves less than 60\% average accuracy, particularly struggling with fine-grained visual cues and complex spatial reasoning. To catalyze advancement in this domain, we construct \textbf{ShotQA}, a large-scale multimodal dataset comprising approximately 70k cinematic QA pairs. Leveraging ShotQA, we develop \textbf{ShotVL} through supervised fine-tuning and Group Relative Policy Optimization. ShotVL significantly outperforms all existing open-source and proprietary models on ShotBench, establishing new \textbf{state-of-the-art} performance. We open-source our models, data, and code to foster rapid progress in this crucial area of AI-driven cinematic understanding and generation.
A Hybrid Wireless Image Transmission Scheme with Diffusion
Aug 16, 2023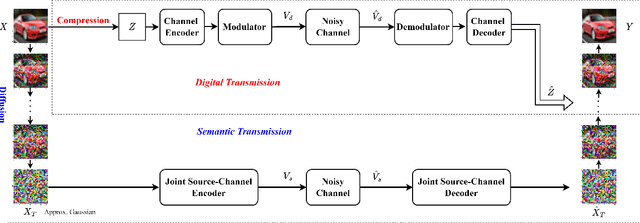
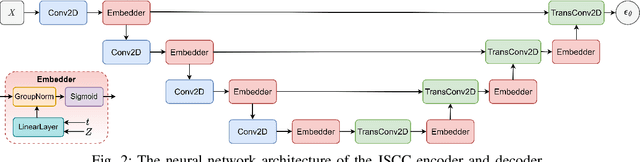

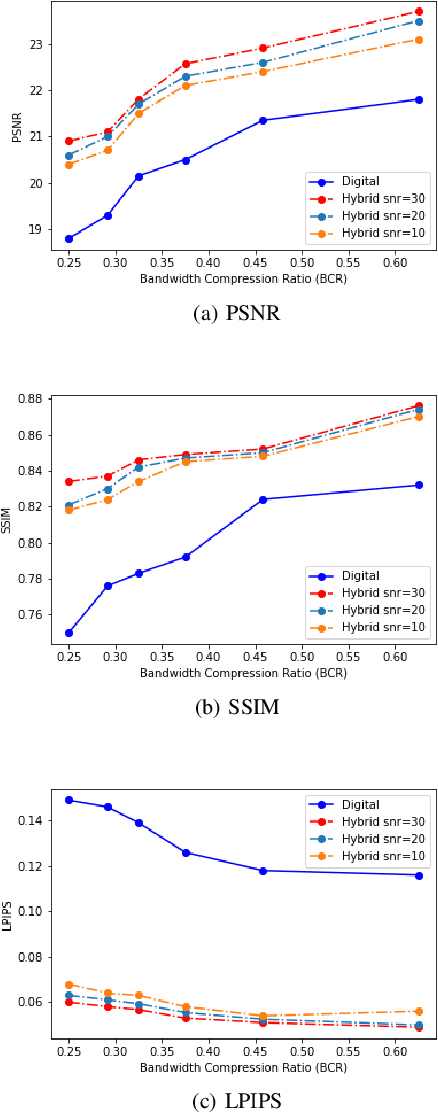
We propose a hybrid joint source-channel coding (JSCC) scheme, in which the conventional digital communication scheme is complemented with a generative refinement component to improve the perceptual quality of the reconstruction. The input image is decomposed into two components: the first is a coarse compressed version, and is transmitted following the conventional separation based approach. An additional component is obtained through the diffusion process by adding independent Gaussian noise to the input image, and is transmitted using DeepJSCC. The decoder combines the two signals to produce a high quality reconstruction of the source. Experimental results show that the hybrid design provides bandwidth savings and enables graceful performance improvement as the channel quality improves.
Improving the CSIEC Project and Adapting It to the English Teaching and Learning in China
Feb 06, 2006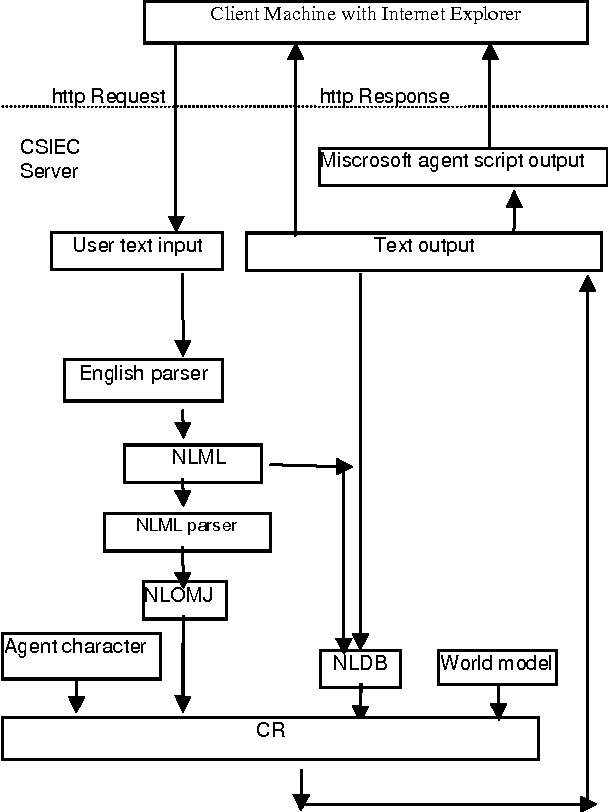
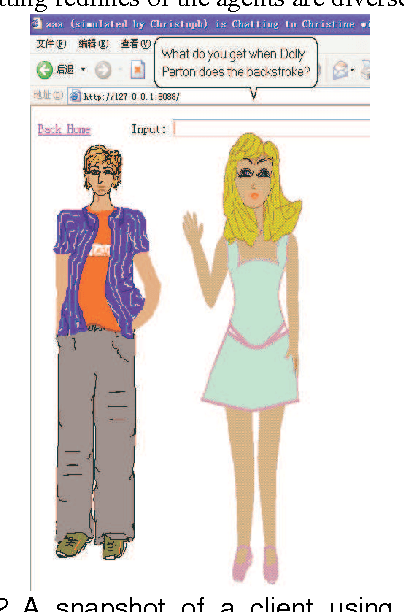
In this paper after short review of the CSIEC project initialized by us in 2003 we present the continuing development and improvement of the CSIEC project in details, including the design of five new Microsoft agent characters representing different virtual chatting partners and the limitation of simulated dialogs in specific practical scenarios like graduate job application interview, then briefly analyze the actual conditions and features of its application field: web-based English education in China. Finally we introduce our efforts to adapt this system to the requirements of English teaching and learning in China and point out the work next to do.