 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Text-Vision Reasoning Imbalance in MLLMs through the Lens of Training Recipes
Oct 26, 2025Multimodal large language models (MLLMs) have demonstrated strong capabilities on vision-and-language tasks. However, recent findings reveal an imbalance in their reasoning capabilities across visual and textual modalities. Specifically, current MLLMs often over-rely on textual cues while under-attending to visual content, resulting in suboptimal performance on tasks that require genuine visual reasoning. We refer to this phenomenon as the \textit{modality gap}, defined as the performance disparity between text-centric and vision-centric inputs. In this paper, we analyze the modality gap through the lens of training recipes. We first show that existing training recipes tend to amplify this gap. Then, we systematically explore strategies to bridge it from two complementary perspectives: data and loss design. Our findings provide insights into developing training recipes that mitigate the modality gap and promote more balanced multimodal reasoning. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Bridging-Modality-Gap.
A Hierarchical Probabilistic Framework for Incremental Knowledge Tracing in Classroom Settings
Jun 11, 2025Knowledge tracing (KT) aims to estimate a student's evolving knowledge state and predict their performance on new exercises based on performance history. Many realistic classroom settings for KT are typically low-resource in data and require online updates as students' exercise history grows, which creates significant challenges for existing KT approaches. To restore strong performance under low-resource conditions, we revisit the hierarchical knowledge concept (KC) information, which is typically available in many classroom settings and can provide strong prior when data are sparse. We therefore propose Knowledge-Tree-based Knowledge Tracing (KT$^2$), a probabilistic KT framework that models student understanding over a tree-structured hierarchy of knowledge concepts using a Hidden Markov Tree Model. KT$^2$ estimates student mastery via an EM algorithm and supports personalized prediction through an incremental update mechanism as new responses arrive. Our experiments show that KT$^2$ consistently outperforms strong baselines in realistic online, low-resource settings.
VSP: Assessing the dual challenges of perception and reasoning in spatial planning tasks for VLMs
Jul 02, 2024



Vision language models (VLMs) are an exciting emerging class of language models (LMs) that have merged classic LM capabilities with those of image processing systems. However, the ways that these capabilities combine are not always intuitive and warrant direct investigation. One understudied capability in VLMs is visual spatial planning -- the ability to comprehend the spatial arrangements of objects and devise action plans to achieve desired outcomes in visual scenes. In our study, we introduce VSP, a benchmark that 1) evaluates the spatial planning capability in these models in general, and 2) breaks down the visual planning task into finer-grained sub-tasks, including perception and reasoning, and measure the LMs capabilities in these sub-tasks. Our evaluation shows that both open-source and private VLMs fail to generate effective plans for even simple spatial planning tasks. Evaluations on the fine-grained analytical tasks further reveal fundamental deficiencies in the models' visual perception and bottlenecks in reasoning abilities, explaining their worse performance in the general spatial planning tasks. Our work illuminates future directions for improving VLMs' abilities in spatial planning. Our benchmark is publicly available at https://github.com/UCSB-NLP-Chang/Visual-Spatial-Planning.
Harnessing the Spatial-Temporal Attention of Diffusion Models for High-Fidelity Text-to-Image Synthesis
Apr 07, 2023



Diffusion-based models have achieved state-of-the-art performance on text-to-image synthesis tasks. However, one critical limitation of these models is the low fidelity of generated images with respect to the text description, such as missing objects, mismatched attributes, and mislocated objects. One key reason for such inconsistencies is the inaccurate cross-attention to text in both the spatial dimension, which controls at what pixel region an object should appear, and the temporal dimension, which controls how different levels of details are added through the denoising steps. In this paper, we propose a new text-to-image algorithm that adds explicit control over spatial-temporal cross-attention in diffusion models. We first utilize a layout predictor to predict the pixel regions for objects mentioned in the text. We then impose spatial attention control by combining the attention over the entire text description and that over the local description of the particular object in the corresponding pixel region of that object. The temporal attention control is further added by allowing the combination weights to change at each denoising step, and the combination weights are optimized to ensure high fidelity between the image and the text. Experiments show that our method generates images with higher fidelity compared to diffusion-model-based baselines without fine-tuning the diffusion model. Our code is publicly available at https://github.com/UCSB-NLP-Chang/Diffusion-SpaceTime-Attn.
Uncovering the Disentanglement Capability in Text-to-Image Diffusion Models
Dec 16, 2022Generative models have been widely studied in computer vision. Recently, diffusion models have drawn substantial attention due to the high quality of their generated images. A key desired property of image generative models is the ability to disentangle different attributes, which should enable modification towards a style without changing the semantic content, and the modification parameters should generalize to different images. Previous studies have found that generative adversarial networks (GANs) are inherently endowed with such disentanglement capability, so they can perform disentangled image editing without re-training or fine-tuning the network. In this work, we explore whether diffusion models are also inherently equipped with such a capability. Our finding is that for stable diffusion models, by partially changing the input text embedding from a neutral description (e.g., "a photo of person") to one with style (e.g., "a photo of person with smile") while fixing all the Gaussian random noises introduced during the denoising process, the generated images can be modified towards the target style without changing the semantic content. Based on this finding, we further propose a simple, light-weight image editing algorithm where the mixing weights of the two text embeddings are optimized for style matching and content preservation. This entire process only involves optimizing over around 50 parameters and does not fine-tune the diffusion model itself. Experiments show that the proposed method can modify a wide range of attributes, with the performance outperforming diffusion-model-based image-editing algorithms that require fine-tuning. The optimized weights generalize well to different images. Our code is publicly available at https://github.com/UCSB-NLP-Chang/DiffusionDisentanglement.
Data-Model-Circuit Tri-Design for Ultra-Light Video Intelligence on Edge Devices
Oct 18, 2022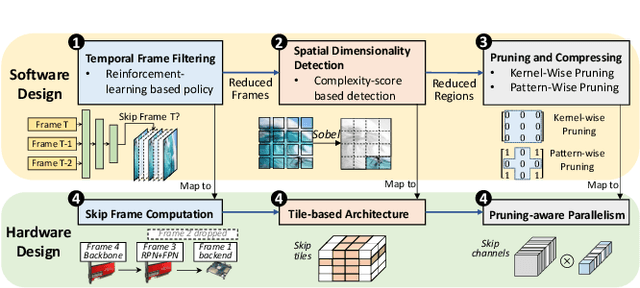
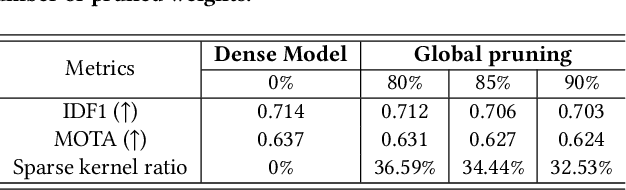


In this paper, we propose a data-model-hardware tri-design framework for high-throughput, low-cost, and high-accuracy multi-object tracking (MOT) on High-Definition (HD) video stream. First, to enable ultra-light video intelligence, we propose temporal frame-filtering and spatial saliency-focusing approaches to reduce the complexity of massive video data. Second, we exploit structure-aware weight sparsity to design a hardware-friendly model compression method. Third, assisted with data and model complexity reduction, we propose a sparsity-aware, scalable, and low-power accelerator design, aiming to deliver real-time performance with high energy efficiency. Different from existing works, we make a solid step towards the synergized software/hardware co-optimization for realistic MOT model implementation. Compared to the state-of-the-art MOT baseline, our tri-design approach can achieve 12.5x latency reduction, 20.9x effective frame rate improvement, 5.83x lower power, and 9.78x better energy efficiency, without much accuracy drop.
Learning Action Translator for Meta Reinforcement Learning on Sparse-Reward Tasks
Jul 20, 2022

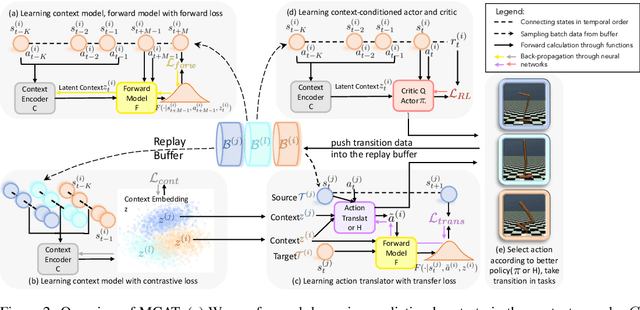

Meta reinforcement learning (meta-RL) aims to learn a policy solving a set of training tasks simultaneously and quickly adapting to new tasks. It requires massive amounts of data drawn from training tasks to infer the common structure shared among tasks. Without heavy reward engineering, the sparse rewards in long-horizon tasks exacerbate the problem of sample efficiency in meta-RL. Another challenge in meta-RL is the discrepancy of difficulty level among tasks, which might cause one easy task dominating learning of the shared policy and thus preclude policy adaptation to new tasks. This work introduces a novel objective function to learn an action translator among training tasks. We theoretically verify that the value of the transferred policy with the action translator can be close to the value of the source policy and our objective function (approximately) upper bounds the value difference. We propose to combine the action translator with context-based meta-RL algorithms for better data collection and more efficient exploration during meta-training. Our approach empirically improves the sample efficiency and performance of meta-RL algorithms on sparse-reward tasks.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
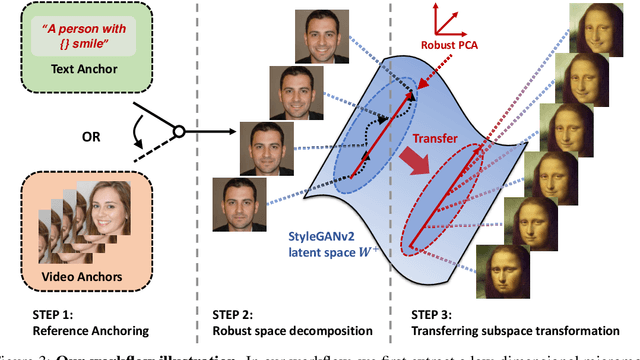


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.