 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuan 2.0-M32: Mixture of Experts with Attention Router
May 29, 2024



Yuan 2.0-M32, with a similar base architecture as Yuan-2.0 2B, uses a mixture-of-experts architecture with 32 experts of which 2 experts are active. A new router network, Attention Router, is proposed and adopted for a more efficient selection of experts, which improves the accuracy compared to the model with classical router network. Yuan 2.0-M32 is trained with 2000B tokens from scratch, and the training computation consumption is only 9.25% of a dense model at the same parameter scale. Yuan 2.0-M32 demonstrates competitive capability on coding, math, and various domains of expertise, with only 3.7B active parameters of 40B in total, and 7.4 GFlops forward computation per token, both of which are only 1/19 of Llama3-70B. Yuan 2.0-M32 surpass Llama3-70B on MATH and ARC-Challenge benchmark, with accuracy of 55.89 and 95.8 respectively. The models and source codes of Yuan 2.0-M32 are released at Github1.
Input-agnostic Certified Group Fairness via Gaussian Parameter Smoothing
Jun 22, 2022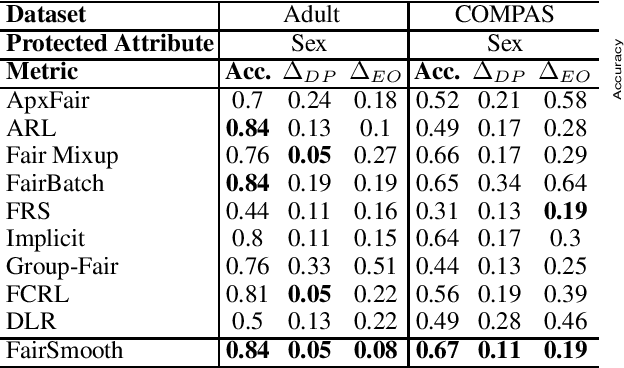
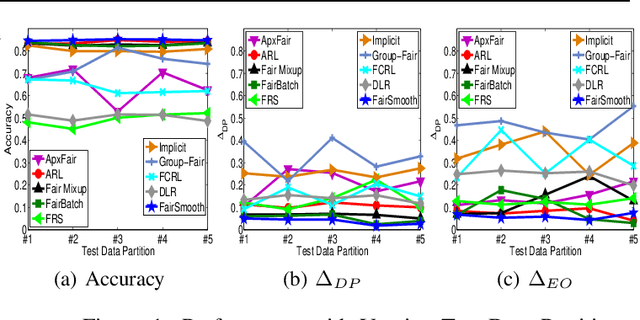
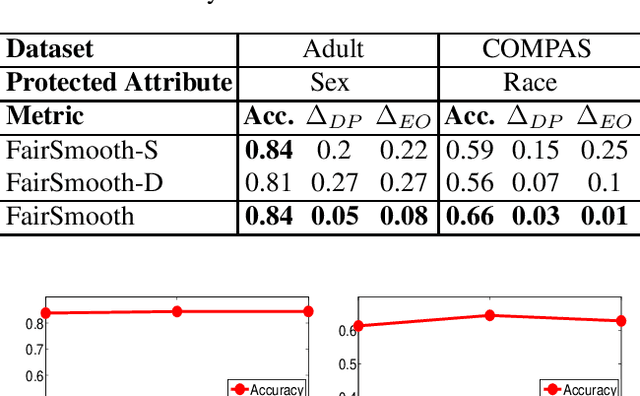
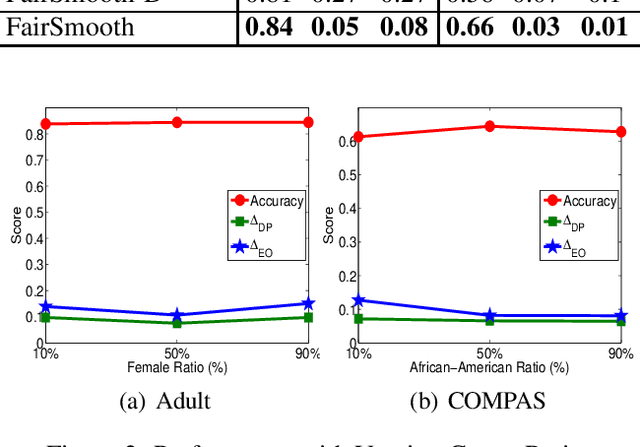
Only recently, researchers attempt to provide classification algorithms with provable group fairness guarantees. Most of these algorithms suffer from harassment caused by the requirement that the training and deployment data follow the same distribution. This paper proposes an input-agnostic certified group fairness algorithm, FairSmooth, for improving the fairness of classification models while maintaining the remarkable prediction accuracy. A Gaussian parameter smoothing method is developed to transform base classifiers into their smooth versions. An optimal individual smooth classifier is learnt for each group with only the data regarding the group and an overall smooth classifier for all groups is generated by averaging the parameters of all the individual smooth ones. By leveraging the theory of nonlinear functional analysis, the smooth classifiers are reformulated as output functions of a Nemytskii operator. Theoretical analysis is conducted to derive that the Nemytskii operator is smooth and induces a Frechet differentiable smooth manifold. We theoretically demonstrate that the smooth manifold has a global Lipschitz constant that is independent of the domain of the input data, which derives the input-agnostic certified group fairness.
Cross-lingual Entity Alignment with Adversarial Kernel Embedding and Adversarial Knowledge Translation
Apr 16, 2021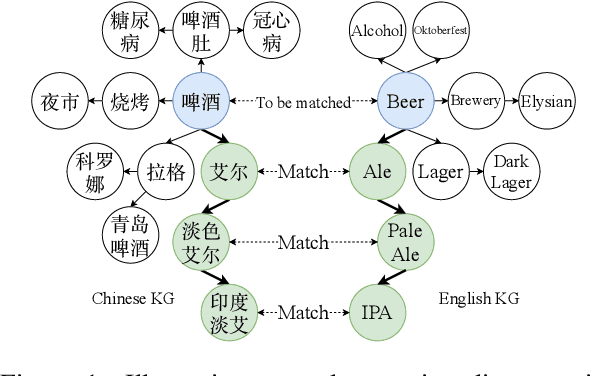
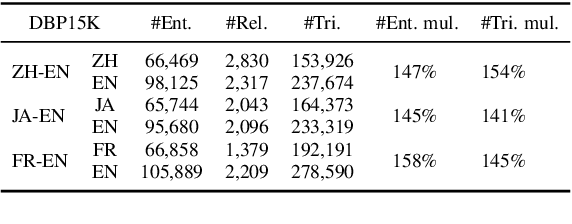
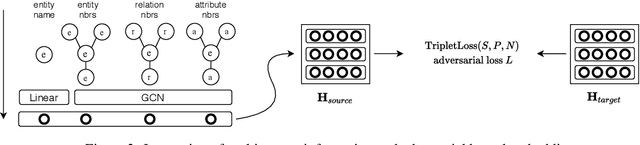
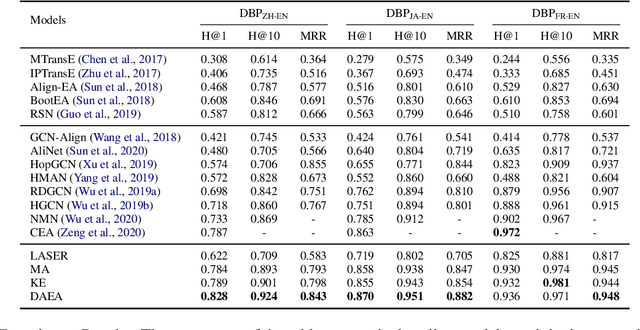
Cross-lingual entity alignment, which aims to precisely connect the same entities in different monolingual knowledge bases (KBs) together, often suffers challenges from feature inconsistency to sequence context unawareness. This paper presents a dual adversarial learning framework for cross-lingual entity alignment, DAEA, with two original contributions. First, in order to address the structural and attribute feature inconsistency between entities in two knowledge graphs (KGs), an adversarial kernel embedding technique is proposed to extract graph-invariant information in an unsupervised manner, and project two KGs into the common embedding space. Second, in order to further improve successful rate of entity alignment, we propose to produce multiple random walks through each entity to be aligned and mask these entities in random walks. With the guidance of known aligned entities in the context of multiple random walks, an adversarial knowledge translation model is developed to fill and translate masked entities in pairwise random walks from two KGs. Extensive experiments performed on real-world datasets show that DAEA can well solve the feature inconsistency and sequence context unawareness issues and significantly outperforms thirteen state-of-the-art entity alignment methods.