 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
WorldPM: Scaling Human Preference Modeling
May 15, 2025Motivated by scaling laws in language modeling that demonstrate how test loss scales as a power law with model and dataset sizes, we find that similar laws exist in preference modeling. We propose World Preference Modeling$ (WorldPM) to emphasize this scaling potential, where World Preference embodies a unified representation of human preferences. In this paper, we collect preference data from public forums covering diverse user communities, and conduct extensive training using 15M-scale data across models ranging from 1.5B to 72B parameters. We observe distinct patterns across different evaluation metrics: (1) Adversarial metrics (ability to identify deceptive features) consistently scale up with increased training data and base model size; (2) Objective metrics (objective knowledge with well-defined answers) show emergent behavior in larger language models, highlighting WorldPM's scalability potential; (3) Subjective metrics (subjective preferences from a limited number of humans or AI) do not demonstrate scaling trends. Further experiments validate the effectiveness of WorldPM as a foundation for preference fine-tuning. Through evaluations on 7 benchmarks with 20 subtasks, we find that WorldPM broadly improves the generalization performance across human preference datasets of varying sizes (7K, 100K and 800K samples), with performance gains exceeding 5% on many key subtasks. Integrating WorldPM into our internal RLHF pipeline, we observe significant improvements on both in-house and public evaluation sets, with notable gains of 4% to 8% in our in-house evaluations.
RMB: Comprehensively Benchmarking Reward Models in LLM Alignment
Oct 13, 2024



Reward models (RMs) guide the alignment of large language models (LLMs), steering them toward behaviors preferred by humans. Evaluating RMs is the key to better aligning LLMs. However, the current evaluation of RMs may not directly correspond to their alignment performance due to the limited distribution of evaluation data and evaluation methods that are not closely related to alignment objectives. To address these limitations, we propose RMB, a comprehensive RM benchmark that covers over 49 real-world scenarios and includes both pairwise and Best-of-N (BoN) evaluations to better reflect the effectiveness of RMs in guiding alignment optimization. We demonstrate a positive correlation between our benchmark and the downstream alignment task performance. Based on our benchmark, we conduct extensive analysis on the state-of-the-art RMs, revealing their generalization defects that were not discovered by previous benchmarks, and highlighting the potential of generative RMs. Furthermore, we delve into open questions in reward models, specifically examining the effectiveness of majority voting for the evaluation of reward models and analyzing the impact factors of generative RMs, including the influence of evaluation criteria and instructing methods. Our evaluation code and datasets are available at https://github.com/Zhou-Zoey/RMB-Reward-Model-Benchmark.
Secrets of RLHF in Large Language Models Part II: Reward Modeling
Jan 12, 2024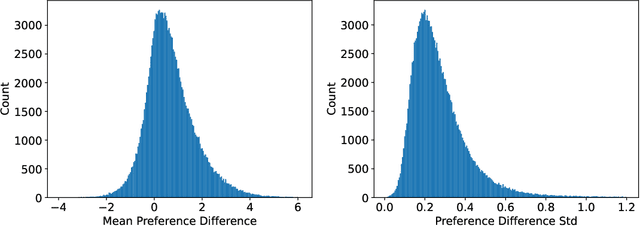

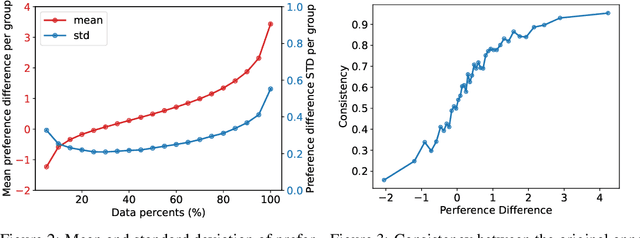
Reinforcement Learning from Human Feedback (RLHF) has become a crucial technology for aligning language models with human values and intentions, enabling models to produce more helpful and harmless responses. Reward models are trained as proxies for human preferences to drive reinforcement learning optimization. While reward models are often considered central to achieving high performance, they face the following challenges in practical applications: (1) Incorrect and ambiguous preference pairs in the dataset may hinder the reward model from accurately capturing human intent. (2) Reward models trained on data from a specific distribution often struggle to generalize to examples outside that distribution and are not suitable for iterative RLHF training. In this report, we attempt to address these two issues. (1) From a data perspective, we propose a method to measure the strength of preferences within the data, based on a voting mechanism of multiple reward models. Experimental results confirm that data with varying preference strengths have different impacts on reward model performance. We introduce a series of novel methods to mitigate the influence of incorrect and ambiguous preferences in the dataset and fully leverage high-quality preference data. (2) From an algorithmic standpoint, we introduce contrastive learning to enhance the ability of reward models to distinguish between chosen and rejected responses, thereby improving model generalization. Furthermore, we employ meta-learning to enable the reward model to maintain the ability to differentiate subtle differences in out-of-distribution samples, and this approach can be utilized for iterative RLHF optimization.
Secrets of RLHF in Large Language Models Part I: PPO
Jul 18, 2023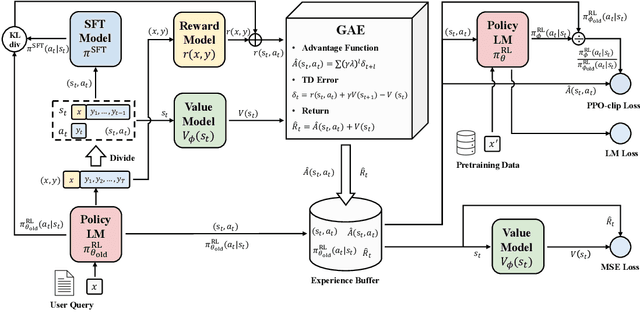



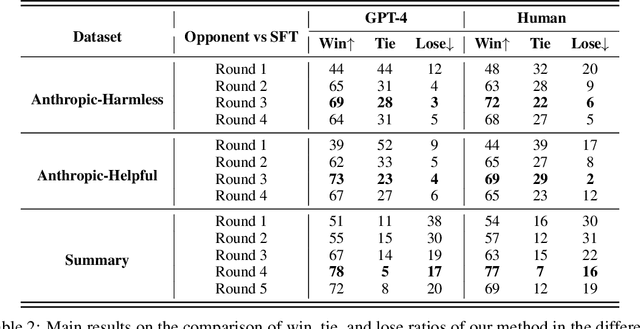
Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include \textbf{reward models} to measure human preferences, \textbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and \textbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.