 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Vision Concept Transformers for Medical Diagnosis
Jun 05, 2025Transparency is a paramount concern in the medical field, prompting researchers to delve into the realm of explainable AI (XAI). Among these XAI methods, Concept Bottleneck Models (CBMs) aim to restrict the model's latent space to human-understandable high-level concepts by generating a conceptual layer for extracting conceptual features, which has drawn much attention recently. However, existing methods rely solely on concept features to determine the model's predictions, which overlook the intrinsic feature embeddings within medical images. To address this utility gap between the original models and concept-based models, we propose Vision Concept Transformer (VCT). Furthermore, despite their benefits, CBMs have been found to negatively impact model performance and fail to provide stable explanations when faced with input perturbations, which limits their application in the medical field. To address this faithfulness issue, this paper further proposes the Stable Vision Concept Transformer (SVCT) based on VCT, which leverages the vision transformer (ViT) as its backbone and incorporates a conceptual layer. SVCT employs conceptual features to enhance decision-making capabilities by fusing them with image features and ensures model faithfulness through the integration of Denoised Diffusion Smoothing. Comprehensive experiments on four medical datasets demonstrate that our VCT and SVCT maintain accuracy while remaining interpretable compared to baselines. Furthermore, even when subjected to perturbations, our SVCT model consistently provides faithful explanations, thus meeting the needs of the medical field.
Improving Generalization of Alignment with Human Preferences through Group Invariant Learning
Oct 19, 2023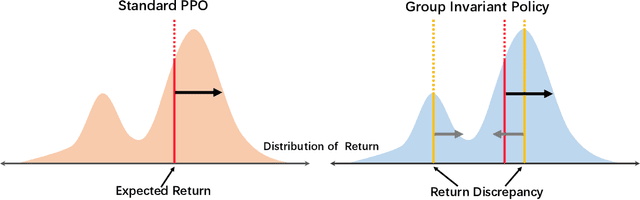


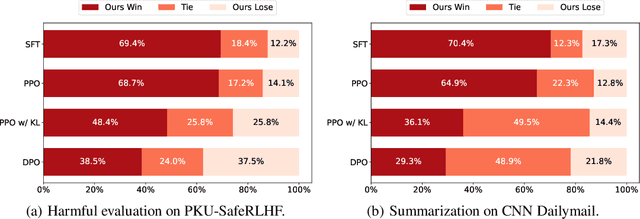
The success of AI assistants based on language models (LLMs) hinges crucially on Reinforcement Learning from Human Feedback (RLHF), which enables the generation of responses more aligned with human preferences. As universal AI assistants, there's a growing expectation for them to perform consistently across various domains. However, previous work shows that Reinforcement Learning (RL) often exploits shortcuts to attain high rewards and overlooks challenging samples. This focus on quick reward gains undermines both the stability in training and the model's ability to generalize to new, unseen data. In this work, we propose a novel approach that can learn a consistent policy via RL across various data groups or domains. Given the challenges associated with acquiring group annotations, our method automatically classifies data into different groups, deliberately maximizing performance variance. Then, we optimize the policy to perform well on challenging groups. Lastly, leveraging the established groups, our approach adaptively adjusts the exploration space, allocating more learning capacity to more challenging data and preventing the model from over-optimizing on simpler data. Experimental results indicate that our approach significantly enhances training stability and model generalization.
Secrets of RLHF in Large Language Models Part I: PPO
Jul 18, 2023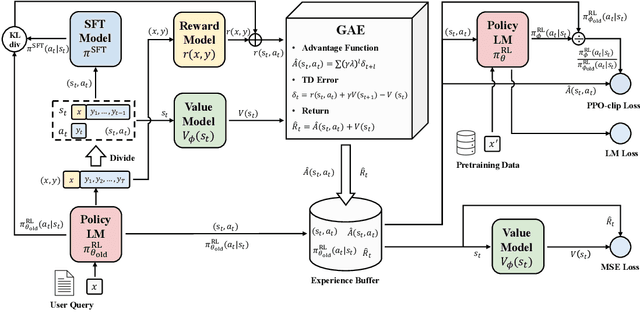



Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include \textbf{reward models} to measure human preferences, \textbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and \textbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.