 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRSAM: Efficiently Segment Anything in High-Resolution Images
Jul 02, 2024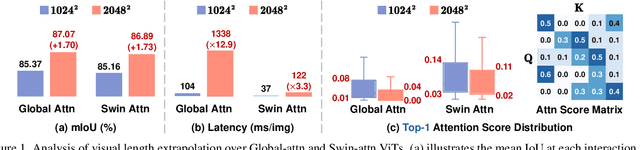
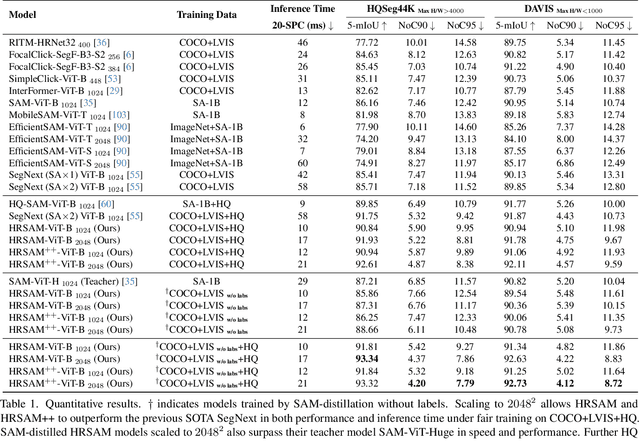

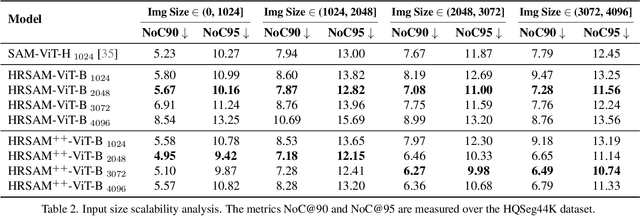
The Segment Anything Model (SAM) has significantly advanced interactive segmentation but struggles with high-resolution images crucial for high-precision segmentation. This is primarily due to the quadratic space complexity of SAM-implemented attention and the length extrapolation issue in common global attention. This study proposes HRSAM that integrates Flash Attention and incorporates Plain, Shifted and newly proposed Cycle-scan Window (PSCWin) attention to address these issues. The shifted window attention is redesigned with padding to maintain consistent window sizes, enabling effective length extrapolation. The cycle-scan window attention adopts the recently developed State Space Models (SSMs) to ensure global information exchange with minimal computational overhead. Such window-based attention allows HRSAM to perform effective attention computations on scaled input images while maintaining low latency. Moreover, we further propose HRSAM++ that additionally employs a multi-scale strategy to enhance HRSAM's performance. The experiments on the high-precision segmentation datasets HQSeg44K and DAVIS show that high-resolution inputs enable the SAM-distilled HRSAM models to outperform the teacher model while maintaining lower latency. Compared to the SOTAs, HRSAM achieves a 1.56 improvement in interactive segmentation's NoC95 metric with only 31% of the latency. HRSAM++ further enhances the performance, achieving a 1.63 improvement in NoC95 with just 38% of the latency.
Improving Generalization of Alignment with Human Preferences through Group Invariant Learning
Oct 19, 2023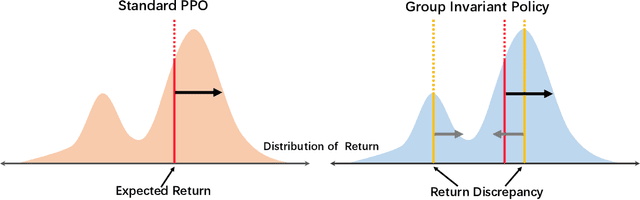


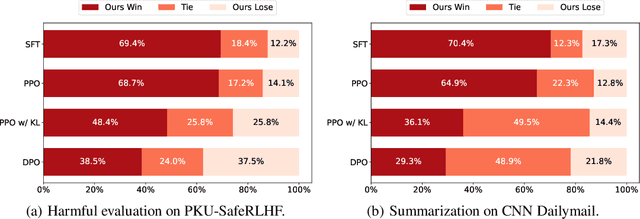
The success of AI assistants based on language models (LLMs) hinges crucially on Reinforcement Learning from Human Feedback (RLHF), which enables the generation of responses more aligned with human preferences. As universal AI assistants, there's a growing expectation for them to perform consistently across various domains. However, previous work shows that Reinforcement Learning (RL) often exploits shortcuts to attain high rewards and overlooks challenging samples. This focus on quick reward gains undermines both the stability in training and the model's ability to generalize to new, unseen data. In this work, we propose a novel approach that can learn a consistent policy via RL across various data groups or domains. Given the challenges associated with acquiring group annotations, our method automatically classifies data into different groups, deliberately maximizing performance variance. Then, we optimize the policy to perform well on challenging groups. Lastly, leveraging the established groups, our approach adaptively adjusts the exploration space, allocating more learning capacity to more challenging data and preventing the model from over-optimizing on simpler data. Experimental results indicate that our approach significantly enhances training stability and model generalization.
Secrets of RLHF in Large Language Models Part I: PPO
Jul 18, 2023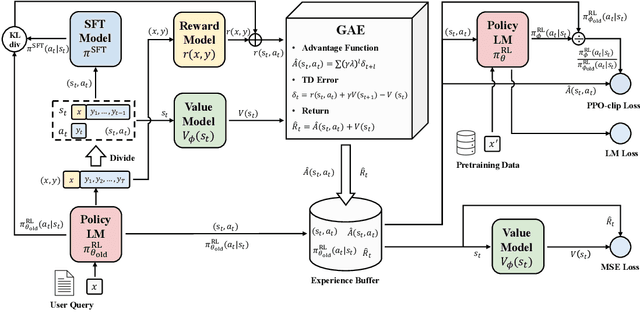



Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include \textbf{reward models} to measure human preferences, \textbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and \textbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.