 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning from Spatio-Temporal Mixed Skeleton Sequences for Self-Supervised Skeleton-Based Action Recognition
Jul 07, 2022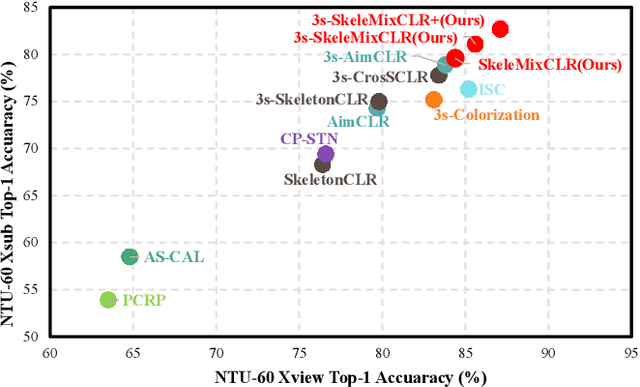
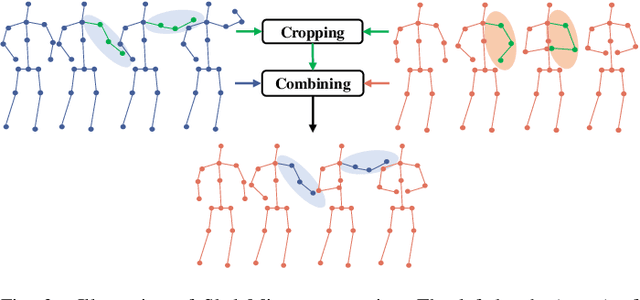
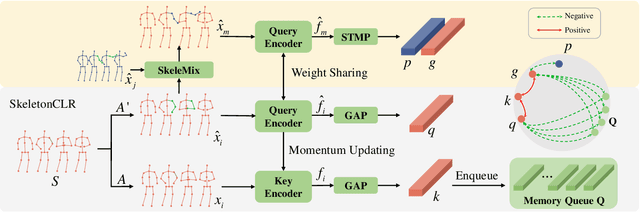
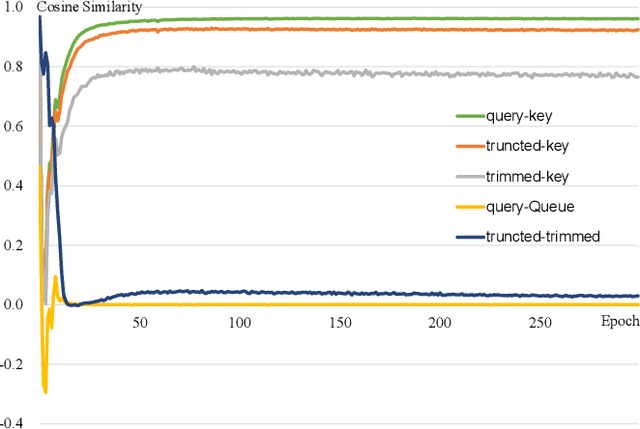
Self-supervised skeleton-based action recognition with contrastive learning has attracted much attention. Recent literature shows that data augmentation and large sets of contrastive pairs are crucial in learning such representations. In this paper, we found that directly extending contrastive pairs based on normal augmentations brings limited returns in terms of performance, because the contribution of contrastive pairs from the normal data augmentation to the loss get smaller as training progresses. Therefore, we delve into hard contrastive pairs for contrastive learning. Motivated by the success of mixing augmentation strategy which improves the performance of many tasks by synthesizing novel samples, we propose SkeleMixCLR: a contrastive learning framework with a spatio-temporal skeleton mixing augmentation (SkeleMix) to complement current contrastive learning approaches by providing hard contrastive samples. First, SkeleMix utilizes the topological information of skeleton data to mix two skeleton sequences by randomly combing the cropped skeleton fragments (the trimmed view) with the remaining skeleton sequences (the truncated view). Second, a spatio-temporal mask pooling is applied to separate these two views at the feature level. Third, we extend contrastive pairs with these two views. SkeleMixCLR leverages the trimmed and truncated views to provide abundant hard contrastive pairs since they involve some context information from each other due to the graph convolution operations, which allows the model to learn better motion representations for action recognition. Extensive experiments on NTU-RGB+D, NTU120-RGB+D, and PKU-MMD datasets show that SkeleMixCLR achieves state-of-the-art performance. Codes are available at https://github.com/czhaneva/SkeleMixCLR.