 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEIVE: End-to-End Instance-Specific Visual Explanations for Detection Transformers
Jun 01, 2026Visual explainability for object detection remains challenging due to the multi-instance nature of detection. Existing approaches predominantly adopt post-hoc paradigms, such as gradient-based or perturbation-based explanation methods, to interpret pretrained detectors. However, these methods require additional gradient computation or repeated model inference, resulting in limited efficiency. To address this issue, we propose an End-to-end Instance-specific Visual Explanation framework (EIVE) that directly generates instance-level saliency maps following the forward pass of Detection Transformer (DETR)-like models. Specifically, we reformulate the cross-attention mechanism in the decoder as an instance-level feature attribution pathway, so that the cross-attention of each object query corresponds to the visual attribution of its predicted instance. Based on this formulation, we design a cross-layer hybrid consensus fusion (CLHCF) module to aggregate cross-attention signals across decoder layers, producing stable and compact explanations. The explanation process of EIVE requires neither gradient computation nor input perturbation, yielding high computational efficiency, and applies to single- and multi-scale DETR-like object detectors. Finally, we present an attention-aware joint training strategy (AAJTS) as a training-oriented application, which imposes spatial constraints on cross-attention patterns to encourage stable and concentrated attribution representations, thereby improving both interpretability and detection performance. Experiments on MS COCO 2017, ExDark, and Cityscapes demonstrate that EIVE produces high-quality instance-level saliency maps and achieves performance comparable to, or better than, state-of-the-art post-hoc methods across standard metrics, while substantially improving explanation efficiency. Code is available at https://github.com/xjlDestiny/EIVE.git.
HiProto: Hierarchical Prototype Learning for Interpretable Object Detection Under Low-quality Conditions
Apr 15, 2026Interpretability is essential for deploying object detection systems in critical applications, especially under low-quality imaging conditions that degrade visual information and increase prediction uncertainty. Existing methods either enhance image quality or design complex architectures, but often lack interpretability and fail to improve semantic discrimination. In contrast, prototype learning enables interpretable modeling by associating features with class-centered semantics, which can provide more stable and interpretable representations under degradation. Motivated by this, we propose HiProto, a new paradigm for interpretable object detection based on hierarchical prototype learning. By constructing structured prototype representations across multiple feature levels, HiProto effectively models class-specific semantics, thereby enhancing both semantic discrimination and interpretability. Building upon prototype modeling, we first propose a Region-to-Prototype Contrastive Loss (RPC-Loss) to enhance the semantic focus of prototypes on target regions. Then, we propose a Prototype Regularization Loss (PR-Loss) to improve the distinctiveness among class prototypes. Finally, we propose a Scale-aware Pseudo Label Generation Strategy (SPLGS) to suppress mismatched supervision for RPC-Loss, thereby preserving the robustness of low-level prototype representations. Experiments on ExDark, RTTS, and VOC2012-FOG demonstrate that HiProto achieves competitive results while offering clear interpretability through prototype responses, without relying on image enhancement or complex architectures. Our code will be available at https://github.com/xjlDestiny/HiProto.git.
M3GCLR: Multi-View Mini-Max Infinite Skeleton-Data Game Contrastive Learning For Skeleton-Based Action Recognition
Mar 10, 2026In recent years, contrastive learning has drawn significant attention as an effective approach to reducing reliance on labeled data. However, existing methods for self-supervised skeleton-based action recognition still face three major limitations: insufficient modeling of view discrepancies, lack of effective adversarial mechanisms, and uncontrollable augmentation perturbations. To tackle these issues, we propose the Multi-view Mini-Max infinite skeleton-data Game Contrastive Learning for skeleton-based action Recognition (M3GCLR), a game-theoretic contrastive framework. First, we establish the Infinite Skeleton-data Game (ISG) model and the ISG equilibrium theorem, and further provide a rigorous proof, enabling mini-max optimization based on multi-view mutual information. Then, we generate normal-extreme data pairs through multi-view rotation augmentation and adopt temporally averaged input as a neutral anchor to achieve structural alignment, thereby explicitly characterizing perturbation strength. Next, leveraging the proposed equilibrium theorem, we construct a strongly adversarial mini-max skeleton-data game to encourage the model to mine richer action-discriminative information. Finally, we introduce the dual-loss equilibrium optimizer to optimize the game equilibrium, allowing the learning process to maximize action-relevant information while minimizing encoding redundancy, and we prove the equivalence between the proposed optimizer and the ISG model. Extensive Experiments show that M3GCLR achieves three-stream 82.1%, 85.8% accuracy on NTU RGB+D 60 (X-Sub, X-View) and 72.3%, 75.0% accuracy on NTU RGB+D 120 (X-Sub, X-Set). On PKU-MMD Part I and II, it attains 89.1%, 45.2% in three-stream respectively, all results matching or outperforming state-of-the-art performance. Ablation studies confirm the effectiveness of each component.
SDCoNet: Saliency-Driven Multi-Task Collaborative Network for Remote Sensing Object Detection
Jan 18, 2026In remote sensing images, complex backgrounds, weak object signals, and small object scales make accurate detection particularly challenging, especially under low-quality imaging conditions. A common strategy is to integrate single-image super-resolution (SR) before detection; however, such serial pipelines often suffer from misaligned optimization objectives, feature redundancy, and a lack of effective interaction between SR and detection. To address these issues, we propose a Saliency-Driven multi-task Collaborative Network (SDCoNet) that couples SR and detection through implicit feature sharing while preserving task specificity. SDCoNet employs the swin transformer-based shared encoder, where hierarchical window-shifted self-attention supports cross-task feature collaboration and adaptively balances the trade-off between texture refinement and semantic representation. In addition, a multi-scale saliency prediction module produces importance scores to select key tokens, enabling focused attention on weak object regions, suppression of background clutter, and suppression of adverse features introduced by multi-task coupling. Furthermore, a gradient routing strategy is introduced to mitigate optimization conflicts. It first stabilizes detection semantics and subsequently routes SR gradients along a detection-oriented direction, enabling the framework to guide the SR branch to generate high-frequency details that are explicitly beneficial for detection. Experiments on public datasets, including NWPU VHR-10-Split, DOTAv1.5-Split, and HRSSD-Split, demonstrate that the proposed method, while maintaining competitive computational efficiency, significantly outperforms existing mainstream algorithms in small object detection on low-quality remote sensing images. Our code is available at https://github.com/qiruo-ya/SDCoNet.
DoGCLR: Dominance-Game Contrastive Learning Network for Skeleton-Based Action Recognition
Nov 19, 2025Existing self-supervised contrastive learning methods for skeleton-based action recognition often process all skeleton regions uniformly, and adopt a first-in-first-out (FIFO) queue to store negative samples, which leads to motion information loss and non-optimal negative sample selection. To address these challenges, this paper proposes Dominance-Game Contrastive Learning network for skeleton-based action Recognition (DoGCLR), a self-supervised framework based on game theory. DoGCLR models the construction of positive and negative samples as a dynamic Dominance Game, where both sample types interact to reach an equilibrium that balances semantic preservation and discriminative strength. Specifically, a spatio-temporal dual weight localization mechanism identifies key motion regions and guides region-wise augmentations to enhance motion diversity while maintaining semantics. In parallel, an entropy-driven dominance strategy manages the memory bank by retaining high entropy (hard) negatives and replacing low-entropy (weak) ones, ensuring consistent exposure to informative contrastive signals. Extensive experiments are conducted on NTU RGB+D and PKU-MMD datasets. On NTU RGB+D 60 X-Sub/X-View, DoGCLR achieves 81.1%/89.4% accuracy, and on NTU RGB+D 120 X-Sub/X-Set, DoGCLR achieves 71.2%/75.5% accuracy, surpassing state-of-the-art methods by 0.1%, 2.7%, 1.1%, and 2.3%, respectively. On PKU-MMD Part I/Part II, DoGCLR performs comparably to the state-of-the-art methods and achieves a 1.9% higher accuracy on Part II, highlighting its strong robustness on more challenging scenarios.
A Gated Cross-domain Collaborative Network for Underwater Object Detection
Jun 25, 2023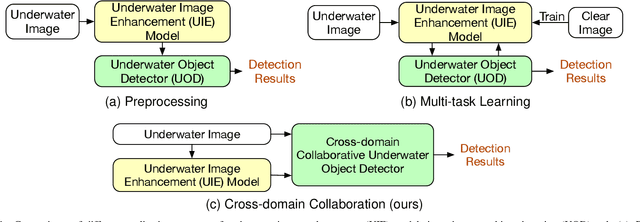
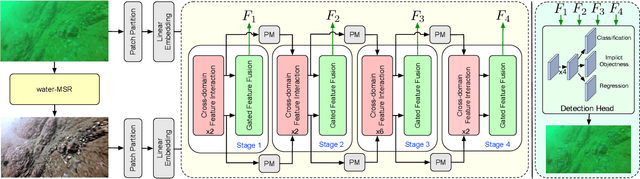
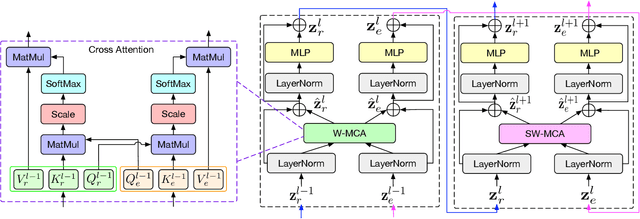

Underwater object detection (UOD) plays a significant role in aquaculture and marine environmental protection. Considering the challenges posed by low contrast and low-light conditions in underwater environments, several underwater image enhancement (UIE) methods have been proposed to improve the quality of underwater images. However, only using the enhanced images does not improve the performance of UOD, since it may unavoidably remove or alter critical patterns and details of underwater objects. In contrast, we believe that exploring the complementary information from the two domains is beneficial for UOD. The raw image preserves the natural characteristics of the scene and texture information of the objects, while the enhanced image improves the visibility of underwater objects. Based on this perspective, we propose a Gated Cross-domain Collaborative Network (GCC-Net) to address the challenges of poor visibility and low contrast in underwater environments, which comprises three dedicated components. Firstly, a real-time UIE method is employed to generate enhanced images, which can improve the visibility of objects in low-contrast areas. Secondly, a cross-domain feature interaction module is introduced to facilitate the interaction and mine complementary information between raw and enhanced image features. Thirdly, to prevent the contamination of unreliable generated results, a gated feature fusion module is proposed to adaptively control the fusion ratio of cross-domain information. Our method presents a new UOD paradigm from the perspective of cross-domain information interaction and fusion. Experimental results demonstrate that the proposed GCC-Net achieves state-of-the-art performance on four underwater datasets.
Edge-guided Representation Learning for Underwater Object Detection
Jun 01, 2023



Underwater object detection (UOD) is crucial for marine economic development, environmental protection, and the planet's sustainable development. The main challenges of this task arise from low-contrast, small objects, and mimicry of aquatic organisms. The key to addressing these challenges is to focus the model on obtaining more discriminative information. We observe that the edges of underwater objects are highly unique and can be distinguished from low-contrast or mimicry environments based on their edges. Motivated by this observation, we propose an Edge-guided Representation Learning Network, termed ERL-Net, that aims to achieve discriminative representation learning and aggregation under the guidance of edge cues. Firstly, we introduce an edge-guided attention module to model the explicit boundary information, which generates more discriminative features. Secondly, a feature aggregation module is proposed to aggregate the multi-scale discriminative features by regrouping them into three levels, effectively aggregating global and local information for locating and recognizing underwater objects. Finally, we propose a wide and asymmetric receptive field block to enable features to have a wider receptive field, allowing the model to focus on more small object information. Comprehensive experiments on three challenging underwater datasets show that our method achieves superior performance on the UOD task.
Boosting R-CNN: Reweighting R-CNN Samples by RPN's Error for Underwater Object Detection
Jun 28, 2022
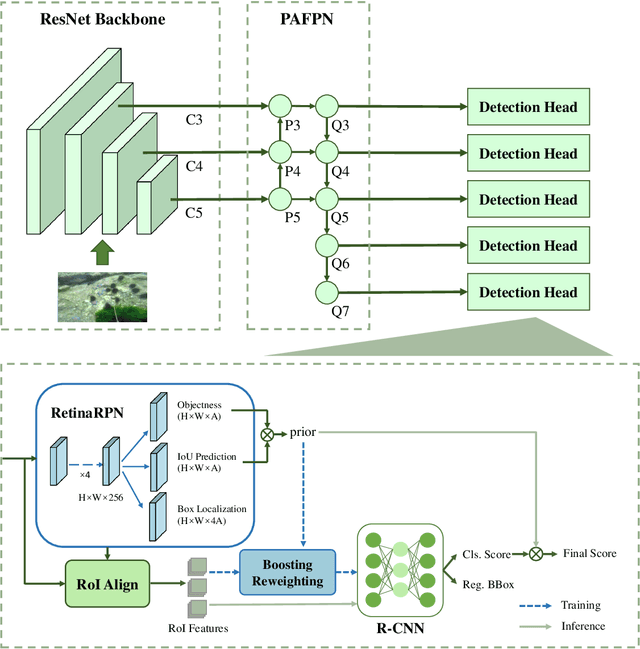
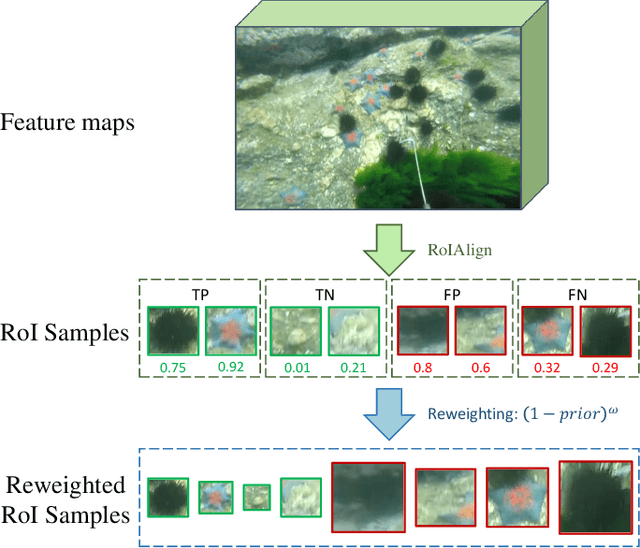
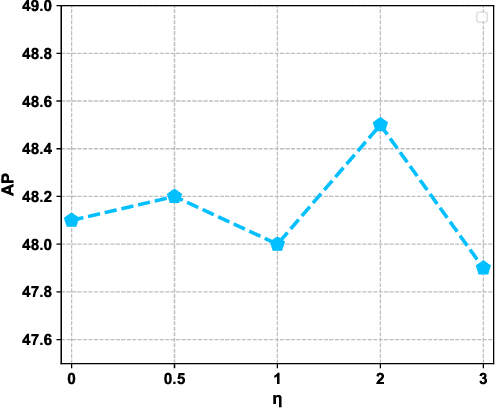
Complicated underwater environments bring new challenges to object detection, such as unbalanced light conditions, low contrast, occlusion, and mimicry of aquatic organisms. Under these circumstances, the objects captured by the underwater camera will become vague, and the generic detectors often fail on these vague objects. This work aims to solve the problem from two perspectives: uncertainty modeling and hard example mining. We propose a two-stage underwater detector named boosting R-CNN, which comprises three key components. First, a new region proposal network named RetinaRPN is proposed, which provides high-quality proposals and considers objectness and IoU prediction for uncertainty to model the object prior probability. Second, the probabilistic inference pipeline is introduced to combine the first-stage prior uncertainty and the second-stage classification score to model the final detection score. Finally, we propose a new hard example mining method named boosting reweighting. Specifically, when the region proposal network miscalculates the object prior probability for a sample, boosting reweighting will increase the classification loss of the sample in the R-CNN head during training, while reducing the loss of easy samples with accurately estimated priors. Thus, a robust detection head in the second stage can be obtained. During the inference stage, the R-CNN has the capability to rectify the error of the first stage to improve the performance. Comprehensive experiments on two underwater datasets and two generic object detection datasets demonstrate the effectiveness and robustness of our method.
AO2-DETR: Arbitrary-Oriented Object Detection Transformer
May 25, 2022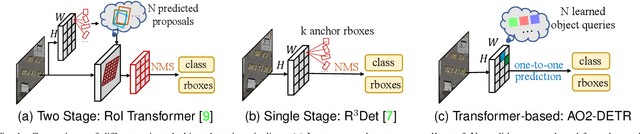

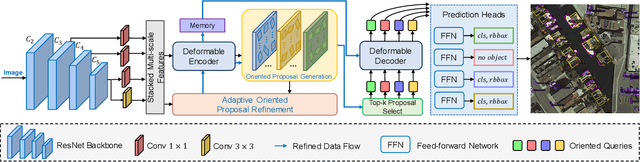
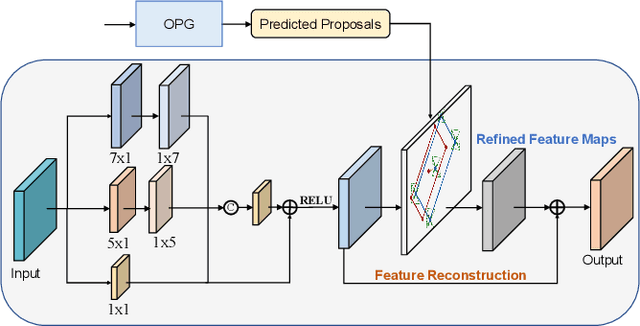
Arbitrary-oriented object detection (AOOD) is a challenging task to detect objects in the wild with arbitrary orientations and cluttered arrangements. Existing approaches are mainly based on anchor-based boxes or dense points, which rely on complicated hand-designed processing steps and inductive bias, such as anchor generation, transformation, and non-maximum suppression reasoning. Recently, the emerging transformer-based approaches view object detection as a direct set prediction problem that effectively removes the need for hand-designed components and inductive biases. In this paper, we propose an Arbitrary-Oriented Object DEtection TRansformer framework, termed AO2-DETR, which comprises three dedicated components. More precisely, an oriented proposal generation mechanism is proposed to explicitly generate oriented proposals, which provides better positional priors for pooling features to modulate the cross-attention in the transformer decoder. An adaptive oriented proposal refinement module is introduced to extract rotation-invariant region features and eliminate the misalignment between region features and objects. And a rotation-aware set matching loss is used to ensure the one-to-one matching process for direct set prediction without duplicate predictions. Our method considerably simplifies the overall pipeline and presents a new AOOD paradigm. Comprehensive experiments on several challenging datasets show that our method achieves superior performance on the AOOD task.
Achieving Domain Generalization in Underwater Object Detection by Image Stylization and Domain Mixup
Apr 06, 2021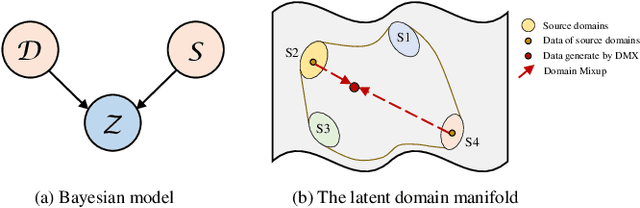
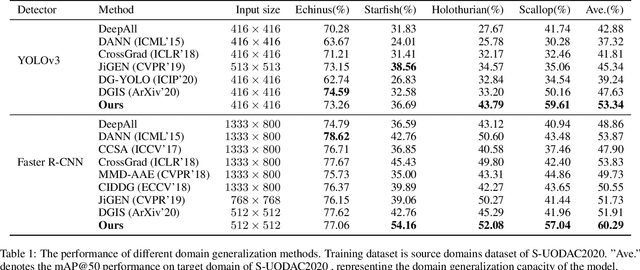
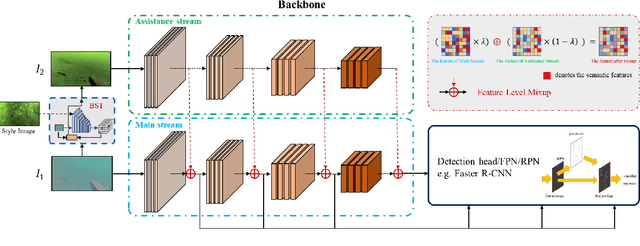
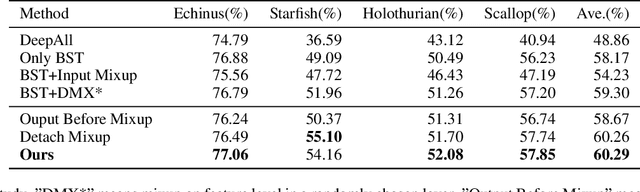
The performance of existing underwater object detection methods degrades seriously when facing domain shift problem caused by complicated underwater environments. Due to the limitation of the number of domains in the dataset, deep detectors easily just memorize a few seen domain, which leads to low generalization ability. Ulteriorly, it can be inferred that the detector trained on as many domains as possible is domain-invariant. Based on this viewpoint, we propose a domain generalization method from the aspect of data augmentation. First, the style transfer model transforms images from one source domain to another, enriching the domain diversity of the training data. Second, interpolating different domains on feature level, new domains can be sampled on the domain manifold. With our method, detectors will be robust to domain shift. Comprehensive experiments on S-UODAC2020 datasets demonstrate that the proposed method is able to learn domain-invariant representations, and outperforms other domain generalization methods. The source code is available at https://github.com/mousecpn.