 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sim-to-Real: Toward General Event-based Low-light Frame Interpolation with Per-scene Optimization
Jun 12, 2024Video Frame Interpolation (VFI) is important for video enhancement, frame rate up-conversion, and slow-motion generation. The introduction of event cameras, which capture per-pixel brightness changes asynchronously, has significantly enhanced VFI capabilities, particularly for high-speed, nonlinear motions. However, these event-based methods encounter challenges in low-light conditions, notably trailing artifacts and signal latency, which hinder their direct applicability and generalization. Addressing these issues, we propose a novel per-scene optimization strategy tailored for low-light conditions. This approach utilizes the internal statistics of a sequence to handle degraded event data under low-light conditions, improving the generalizability to different lighting and camera settings. To evaluate its robustness in low-light condition, we further introduce EVFI-LL, a unique RGB+Event dataset captured under low-light conditions. Our results demonstrate state-of-the-art performance in low-light environments. Both the dataset and the source code will be made publicly available upon publication. Project page: https://naturezhanghn.github.io/sim2real.
Towards a Unified Approach to Single Image Deraining and Dehazing
Mar 26, 2021
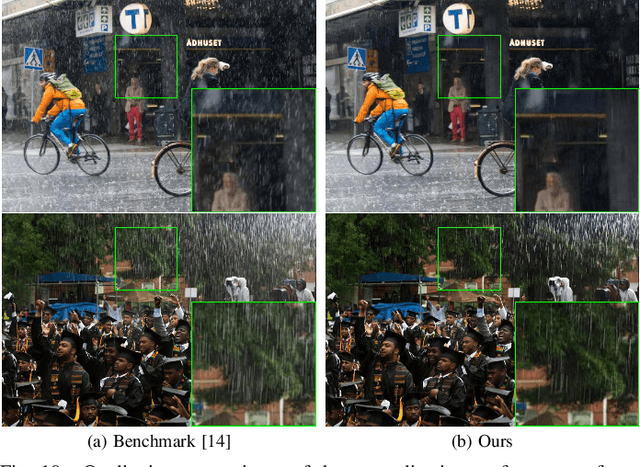

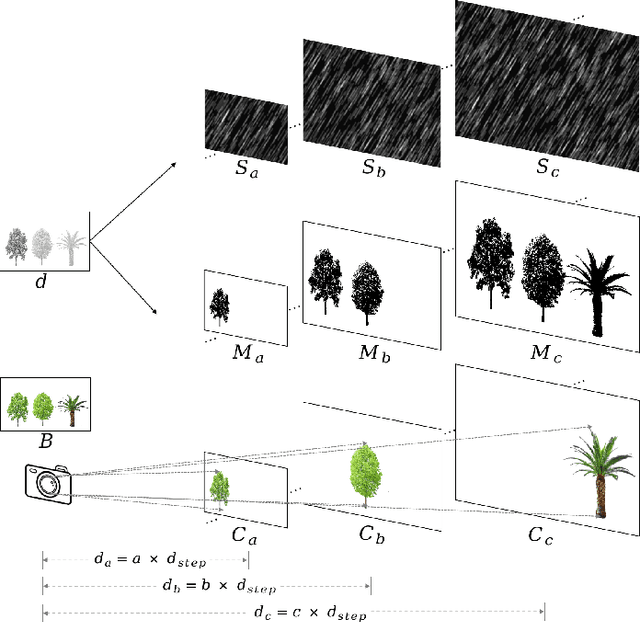
We develop a new physical model for the rain effect and show that the well-known atmosphere scattering model (ASM) for the haze effect naturally emerges as its homogeneous continuous limit. Via depth-aware fusion of multi-layer rain streaks according to the camera imaging mechanism, the new model can better capture the sophisticated non-deterministic degradation patterns commonly seen in real rainy images. We also propose a Densely Scale-Connected Attentive Network (DSCAN) that is suitable for both deraining and dehazing tasks. Our design alleviates the bottleneck issue existent in conventional multi-scale networks and enables more effective information exchange and aggregation. Extensive experimental results demonstrate that the proposed DSCAN is able to deliver superior derained/dehazed results on both synthetic and real images as compared to the state-of-the-art. Moreover, it is shown that for our DSCAN, the synthetic dataset built using the new physical model yields better generalization performance on real images in comparison with the existing datasets based on over-simplified models.
Exploiting Raw Images for Real-Scene Super-Resolution
Feb 02, 2021
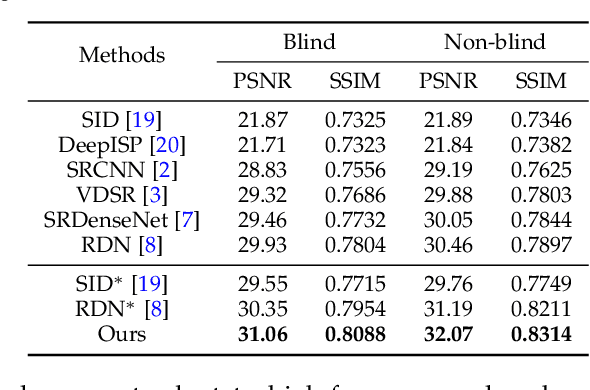
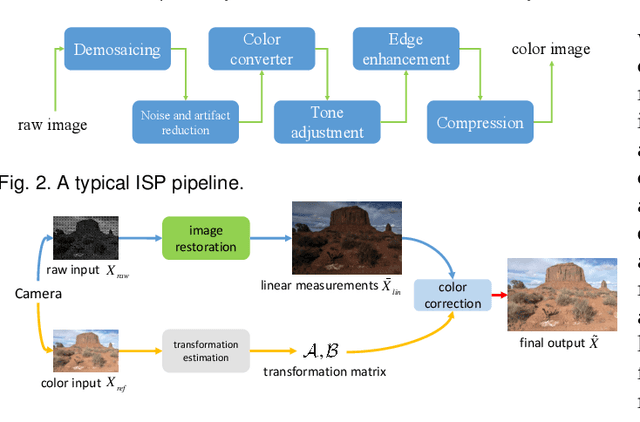
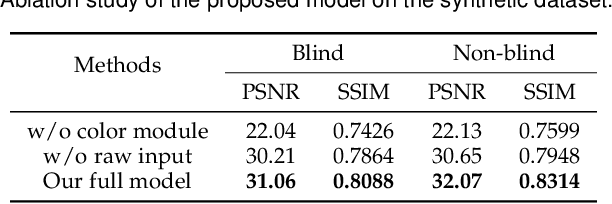
Super-resolution is a fundamental problem in computer vision which aims to overcome the spatial limitation of camera sensors. While significant progress has been made in single image super-resolution, most algorithms only perform well on synthetic data, which limits their applications in real scenarios. In this paper, we study the problem of real-scene single image super-resolution to bridge the gap between synthetic data and real captured images. We focus on two issues of existing super-resolution algorithms: lack of realistic training data and insufficient utilization of visual information obtained from cameras. To address the first issue, we propose a method to generate more realistic training data by mimicking the imaging process of digital cameras. For the second issue, we develop a two-branch convolutional neural network to exploit the radiance information originally-recorded in raw images. In addition, we propose a dense channel-attention block for better image restoration as well as a learning-based guided filter network for effective color correction. Our model is able to generalize to different cameras without deliberately training on images from specific camera types. Extensive experiments demonstrate that the proposed algorithm can recover fine details and clear structures, and achieve high-quality results for single image super-resolution in real scenes.
* A larger version with higher-resolution figures is available at: https://sites.google.com/view/xiangyuxu. arXiv admin note: text overlap with arXiv:1905.12156
GridDehazeNet: Attention-Based Multi-Scale Network for Image Dehazing
Aug 08, 2019


We propose an end-to-end trainable Convolutional Neural Network (CNN), named GridDehazeNet, for single image dehazing. The GridDehazeNet consists of three modules: pre-processing, backbone, and post-processing. The trainable pre-processing module can generate learned inputs with better diversity and more pertinent features as compared to those derived inputs produced by hand-selected pre-processing methods. The backbone module implements a novel attention-based multi-scale estimation on a grid network, which can effectively alleviate the bottleneck issue often encountered in the conventional multi-scale approach. The post-processing module helps to reduce the artifacts in the final output. Experimental results indicate that the GridDehazeNet outperforms the state-of-the-arts on both synthetic and real-world images. The proposed hazing method does not rely on the atmosphere scattering model, and we provide an explanation as to why it is not necessarily beneficial to take advantage of the dimension reduction offered by the atmosphere scattering model for image dehazing, even if only the dehazing results on synthetic images are concerned.
Towards Real Scene Super-Resolution with Raw Images
May 29, 2019

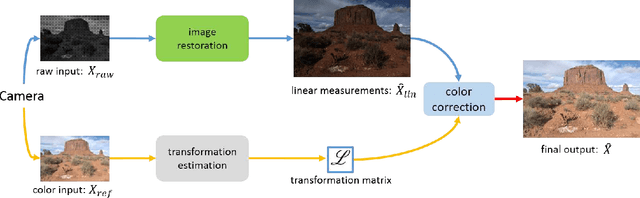

Most existing super-resolution methods do not perform well in real scenarios due to lack of realistic training data and information loss of the model input. To solve the first problem, we propose a new pipeline to generate realistic training data by simulating the imaging process of digital cameras. And to remedy the information loss of the input, we develop a dual convolutional neural network to exploit the originally captured radiance information in raw images. In addition, we propose to learn a spatially-variant color transformation which helps more effective color corrections. Extensive experiments demonstrate that super-resolution with raw data helps recover fine details and clear structures, and more importantly, the proposed network and data generation pipeline achieve superior results for single image super-resolution in real scenarios.