 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Raw Images for Real-Scene Super-Resolution
Paper and Code
Feb 02, 2021
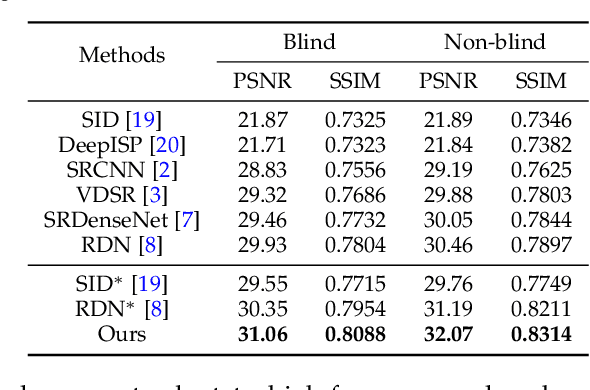
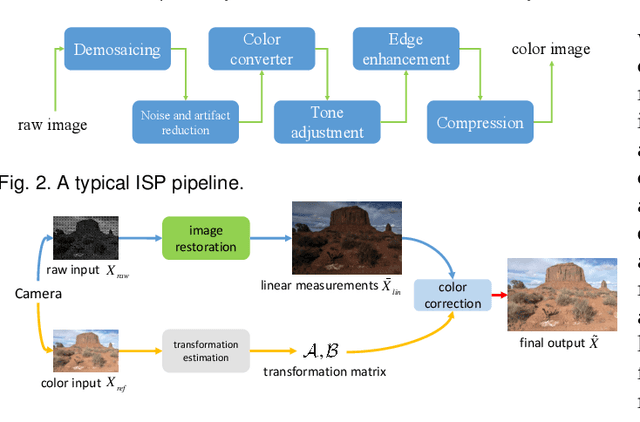
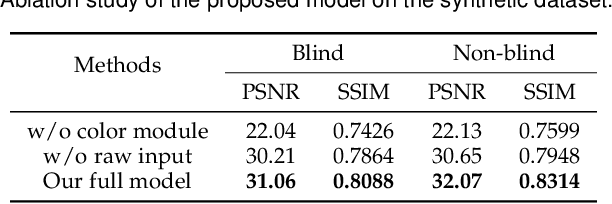
Super-resolution is a fundamental problem in computer vision which aims to overcome the spatial limitation of camera sensors. While significant progress has been made in single image super-resolution, most algorithms only perform well on synthetic data, which limits their applications in real scenarios. In this paper, we study the problem of real-scene single image super-resolution to bridge the gap between synthetic data and real captured images. We focus on two issues of existing super-resolution algorithms: lack of realistic training data and insufficient utilization of visual information obtained from cameras. To address the first issue, we propose a method to generate more realistic training data by mimicking the imaging process of digital cameras. For the second issue, we develop a two-branch convolutional neural network to exploit the radiance information originally-recorded in raw images. In addition, we propose a dense channel-attention block for better image restoration as well as a learning-based guided filter network for effective color correction. Our model is able to generalize to different cameras without deliberately training on images from specific camera types. Extensive experiments demonstrate that the proposed algorithm can recover fine details and clear structures, and achieve high-quality results for single image super-resolution in real scenes.