 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive with Purpose: Guiding Progressive Inpainting DNNs through Context and Structure
Sep 21, 2022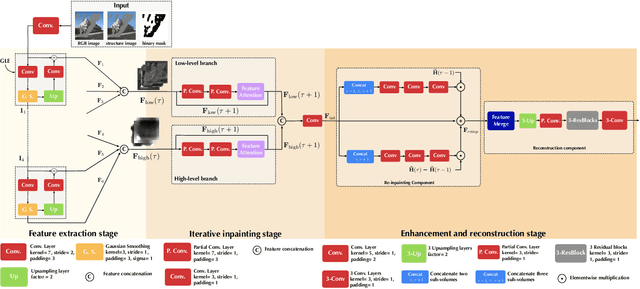



The advent of deep learning in the past decade has significantly helped advance image inpainting. Although achieving promising performance, deep learning-based inpainting algorithms still struggle from the distortion caused by the fusion of structural and contextual features, which are commonly obtained from, respectively, deep and shallow layers of a convolutional encoder. Motivated by this observation, we propose a novel progressive inpainting network that maintains the structural and contextual integrity of a processed image. More specifically, inspired by the Gaussian and Laplacian pyramids, the core of the proposed network is a feature extraction module named GLE. Stacking GLE modules enables the network to extract image features from different image frequency components. This ability is important to maintain structural and contextual integrity, for high frequency components correspond to structural information while low frequency components correspond to contextual information. The proposed network utilizes the GLE features to progressively fill in missing regions in a corrupted image in an iterative manner. Our benchmarking experiments demonstrate that the proposed method achieves clear improvement in performance over many state-of-the-art inpainting algorithms.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021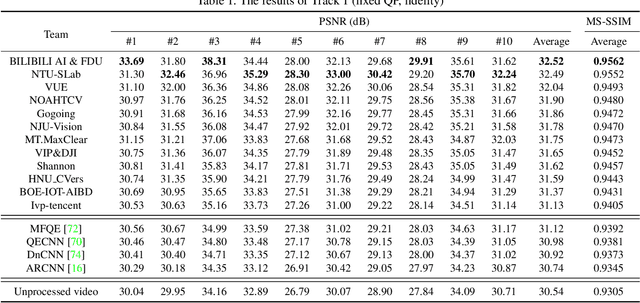
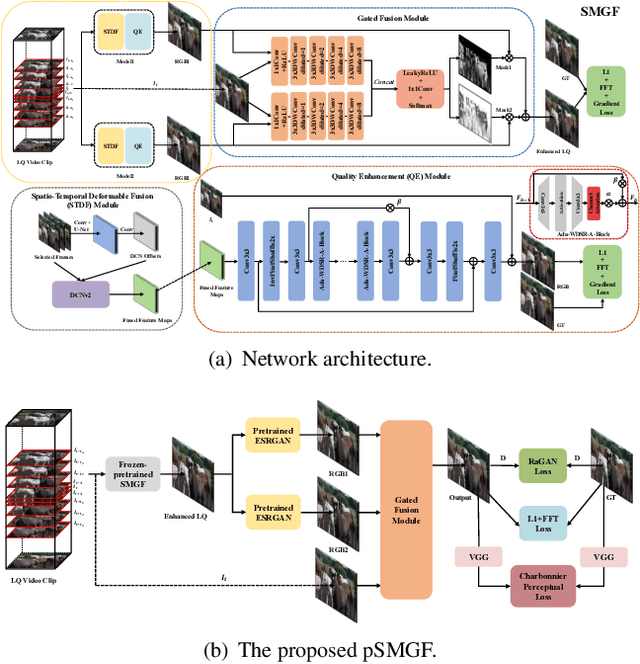
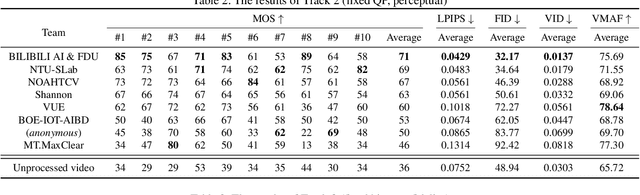
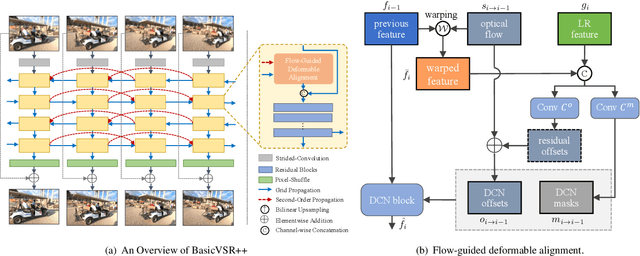
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Exploit Camera Raw Data for Video Super-Resolution via Hidden Markov Model Inference
Aug 24, 2020
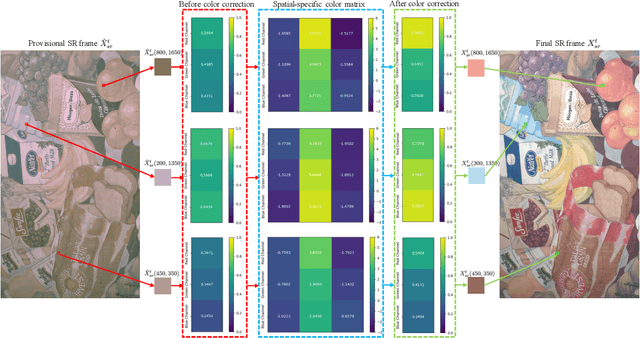

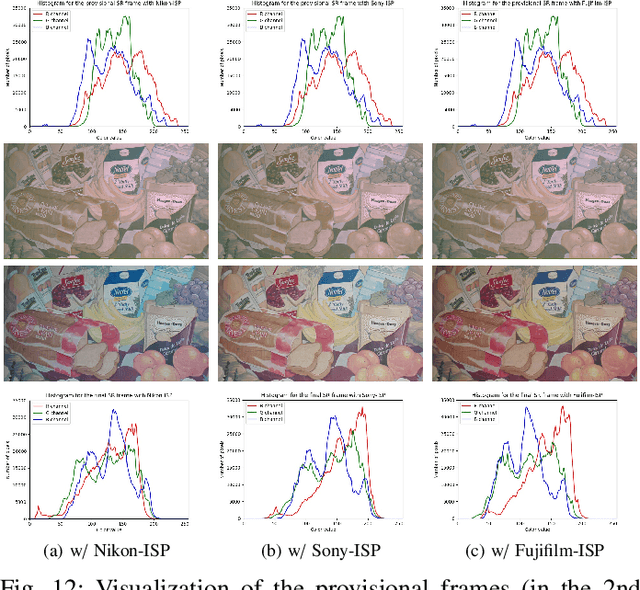
To the best of our knowledge, the existing deep-learning-based Video Super-Resolution (VSR) methods exclusively make use of videos produced by the Image Signal Processor (ISP) of the camera system as inputs. Such methods are 1) inherently suboptimal due to information loss incurred by non-invertible operations in ISP, and 2) inconsistent with the real imaging pipeline where VSR in fact serves as a pre-processing unit of ISP. To address this issue, we propose a new VSR method that can directly exploit camera sensor data, accompanied by a carefully built Raw Video Dataset (RawVD) for training, validation, and testing. This method consists of a Successive Deep Inference (SDI) module and a reconstruction module, among others. The SDI module is designed according to the architectural principle suggested by a canonical decomposition result for Hidden Markov Model (HMM) inference; it estimates the target high-resolution frame by repeatedly performing pairwise feature fusion using deformable convolutions. The reconstruction module, built with elaborately designed Attention-based Residual Dense Blocks (ARDBs), serves the purpose of 1) refining the fused feature and 2) learning the color information needed to generate a spatial-specific transformation for accurate color correction. Extensive experiments demonstrate that owing to the informativeness of the camera raw data, the effectiveness of the network architecture, and the separation of super-resolution and color correction processes, the proposed method achieves superior VSR results compared to the state-of-the-art and can be adapted to any specific camera-ISP.
Video Interpolation via Generalized Deformable Convolution
Aug 24, 2020


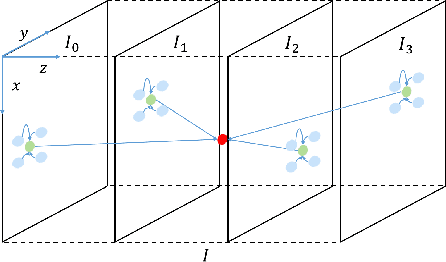
Video interpolation aims at increasing the frame rate of a given video by synthesizing intermediate frames. The existing video interpolation methods can be roughly divided into two categories: flow-based methods and kernel-based methods. The performance of flow-based methods is often jeopardized by the inaccuracy of flow map estimation due to oversimplified motion models while that of kernel-based methods tends to be constrained by the rigidity of kernel shape. To address these performance-limiting issues, a novel mechanism named generalized deformable convolution is proposed, which can effectively learn motion information in a data-driven manner and freely select sampling points in space-time. We further develop a new video interpolation method based on this mechanism. Our extensive experiments demonstrate that the new method performs favorably against the state-of-the-art, especially when dealing with complex motions.