 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUW-SDF: Exploiting Hybrid Geometric Priors for Neural SDF Reconstruction from Underwater Multi-view Monocular Images
Oct 10, 2024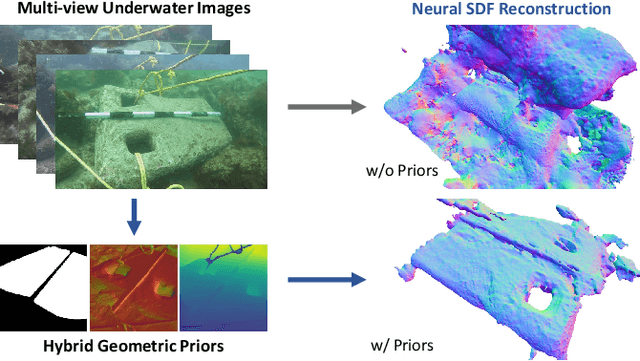
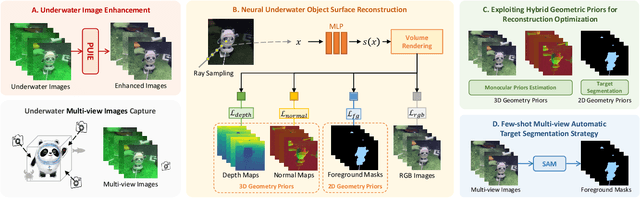
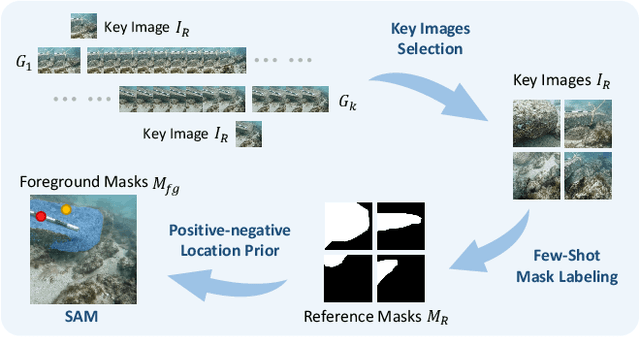
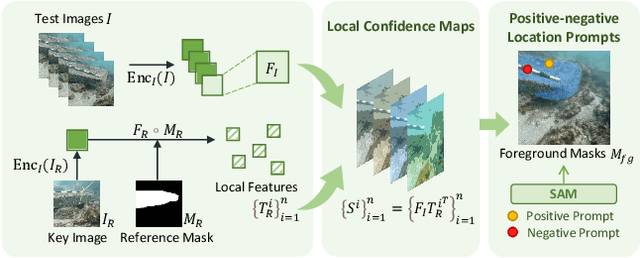
Due to the unique characteristics of underwater environments, accurate 3D reconstruction of underwater objects poses a challenging problem in tasks such as underwater exploration and mapping. Traditional methods that rely on multiple sensor data for 3D reconstruction are time-consuming and face challenges in data acquisition in underwater scenarios. We propose UW-SDF, a framework for reconstructing target objects from multi-view underwater images based on neural SDF. We introduce hybrid geometric priors to optimize the reconstruction process, markedly enhancing the quality and efficiency of neural SDF reconstruction. Additionally, to address the challenge of segmentation consistency in multi-view images, we propose a novel few-shot multi-view target segmentation strategy using the general-purpose segmentation model (SAM), enabling rapid automatic segmentation of unseen objects. Through extensive qualitative and quantitative experiments on diverse datasets, we demonstrate that our proposed method outperforms the traditional underwater 3D reconstruction method and other neural rendering approaches in the field of underwater 3D reconstruction.
FAFA: Frequency-Aware Flow-Aided Self-Supervision for Underwater Object Pose Estimation
Sep 25, 2024


Although methods for estimating the pose of objects in indoor scenes have achieved great success, the pose estimation of underwater objects remains challenging due to difficulties brought by the complex underwater environment, such as degraded illumination, blurring, and the substantial cost of obtaining real annotations. In response, we introduce FAFA, a Frequency-Aware Flow-Aided self-supervised framework for 6D pose estimation of unmanned underwater vehicles (UUVs). Essentially, we first train a frequency-aware flow-based pose estimator on synthetic data, where an FFT-based augmentation approach is proposed to facilitate the network in capturing domain-invariant features and target domain styles from a frequency perspective. Further, we perform self-supervised training by enforcing flow-aided multi-level consistencies to adapt it to the real-world underwater environment. Our framework relies solely on the 3D model and RGB images, alleviating the need for any real pose annotations or other-modality data like depths. We evaluate the effectiveness of FAFA on common underwater object pose benchmarks and showcase significant performance improvements compared to state-of-the-art methods. Code is available at github.com/tjy0703/FAFA.
Edge-guided Representation Learning for Underwater Object Detection
Jun 01, 2023



Underwater object detection (UOD) is crucial for marine economic development, environmental protection, and the planet's sustainable development. The main challenges of this task arise from low-contrast, small objects, and mimicry of aquatic organisms. The key to addressing these challenges is to focus the model on obtaining more discriminative information. We observe that the edges of underwater objects are highly unique and can be distinguished from low-contrast or mimicry environments based on their edges. Motivated by this observation, we propose an Edge-guided Representation Learning Network, termed ERL-Net, that aims to achieve discriminative representation learning and aggregation under the guidance of edge cues. Firstly, we introduce an edge-guided attention module to model the explicit boundary information, which generates more discriminative features. Secondly, a feature aggregation module is proposed to aggregate the multi-scale discriminative features by regrouping them into three levels, effectively aggregating global and local information for locating and recognizing underwater objects. Finally, we propose a wide and asymmetric receptive field block to enable features to have a wider receptive field, allowing the model to focus on more small object information. Comprehensive experiments on three challenging underwater datasets show that our method achieves superior performance on the UOD task.
ISTA-Inspired Network for Image Super-Resolution
Oct 14, 2022
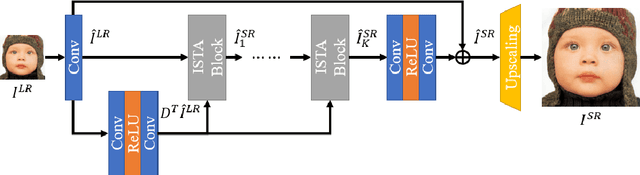
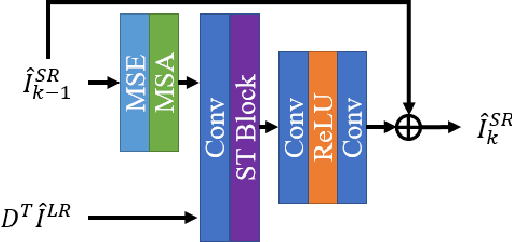
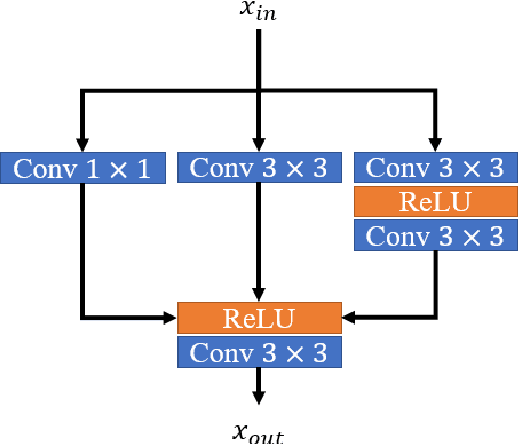
Deep learning for image super-resolution (SR) has been investigated by numerous researchers in recent years. Most of the works concentrate on effective block designs and improve the network representation but lack interpretation. There are also iterative optimization-inspired networks for image SR, which take the solution step as a whole without giving an explicit optimization step. This paper proposes an unfolding iterative shrinkage thresholding algorithm (ISTA) inspired network for interpretable image SR. Specifically, we analyze the problem of image SR and propose a solution based on the ISTA method. Inspired by the mathematical analysis, the ISTA block is developed to conduct the optimization in an end-to-end manner. To make the exploration more effective, a multi-scale exploitation block and multi-scale attention mechanism are devised to build the ISTA block. Experimental results show the proposed ISTA-inspired restoration network (ISTAR) achieves competitive or better performances than other optimization-inspired works with fewer parameters and lower computation complexity.