 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 26, 2024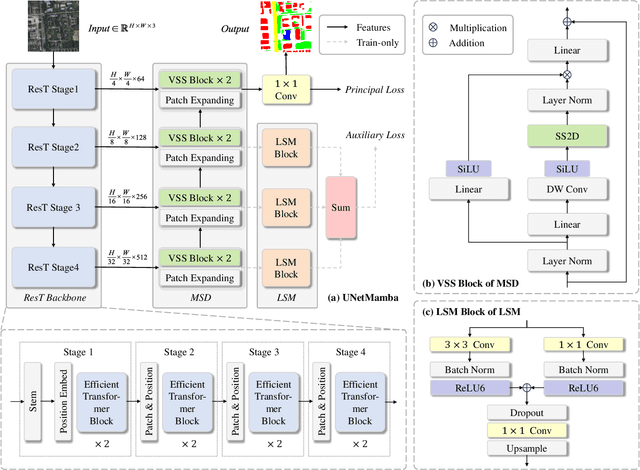
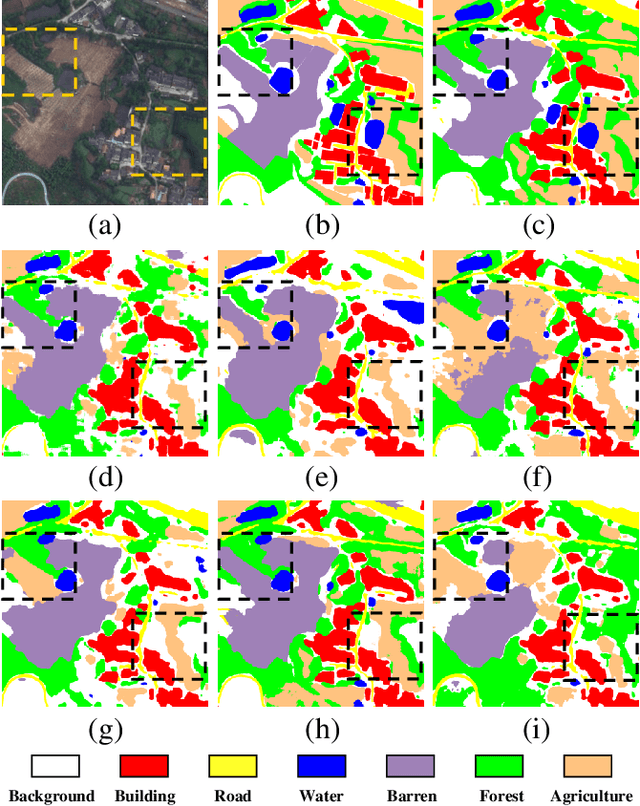


Semantic segmentation of high-resolution remote sensing images is vital in downstream applications such as land-cover mapping, urban planning and disaster assessment.Existing Transformer-based methods suffer from the constraint between accuracy and efficiency, while the recently proposed Mamba is renowned for being efficient. Therefore, to overcome the dilemma, we propose UNetMamba, a UNet-like semantic segmentation model based on Mamba. It incorporates a mamba segmentation decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a local supervision module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNetMamba outperforms the state-of-the-art methods with mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through the lightweight design, less memory footprint and reduced computational cost. The source code is available at https://github.com/EnzeZhu2001/UNetMamba.
UNetMamba: Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 21, 2024The semantic segmentation of high-resolution remote sensing images plays a crucial role in downstream applications such as urban planning and disaster assessment. However, existing Transformer-based methods suffer from the constraint between accuracy and efficiency. To overcome this dilemma, we propose UNetMamba, a novel Mamba-based semantic segmentation model. It incorporates a Mamba Segmentation Decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a Local Supervision Module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNet-Mamba outperforms the state-of-the-art methods with the mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through light weight, low memory footprint and low computational cost. The source code will soon be publicly available at https://github.com/EnzeZhu2001/UNetMamba.
MiLMo:Minority Multilingual Pre-trained Language Model
Dec 04, 2022



Pre-trained language models are trained on large-scale unsupervised data, and they can be fine-tuned on small-scale labeled datasets and achieve good results. Multilingual pre-trained language models can be trained on multiple languages and understand multiple languages at the same time. At present, the research on pre-trained models mainly focuses on rich-resource language, while there is relatively little research on low-resource languages such as minority languages, and the public multilingual pre-trained language model can not work well for minority languages. Therefore, this paper constructs a multilingual pre-trained language model named MiLMo that performs better on minority language tasks, including Mongolian, Tibetan, Uyghur, Kazakh and Korean. To solve the problem of scarcity of datasets on minority languages and verify the effectiveness of the MiLMo model, this paper constructs a minority multilingual text classification dataset named MiTC, and trains a word2vec model for each language. By comparing the word2vec model and the pre-trained model in the text classification task, this paper provides an optimal scheme for the downstream task research of minority languages. The final experimental results show that the performance of the pre-trained model is better than that of the word2vec model, and it has achieved the best results in minority multilingual text classification. The multilingual pre-trained language model MiLMo, multilingual word2vec model and multilingual text classification dataset MiTC are published on https://milmo.cmli-nlp.com.