Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Unsupervised Speech Recognition with Diffusion GANs
Paper and Code
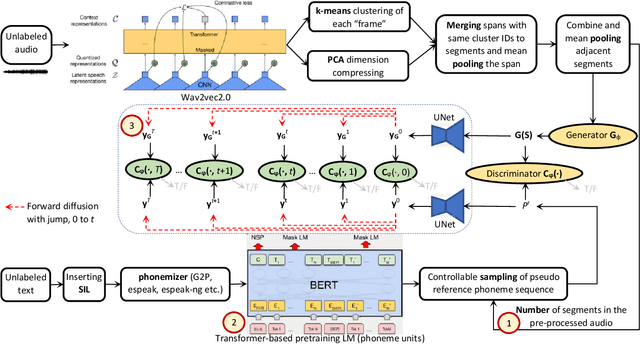
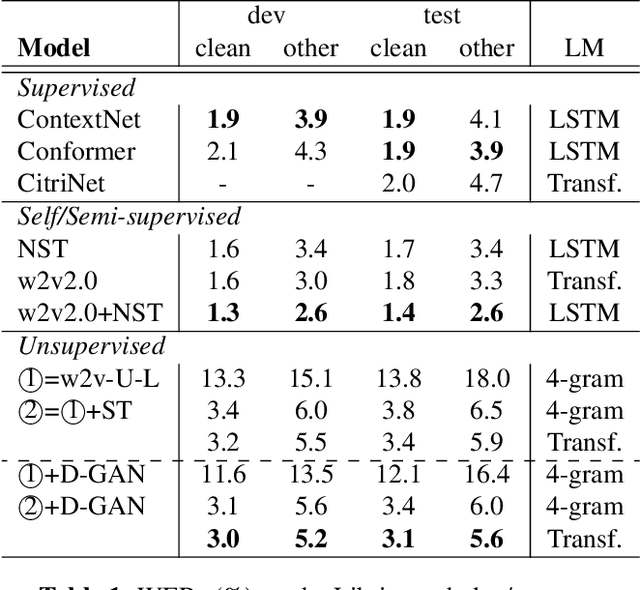
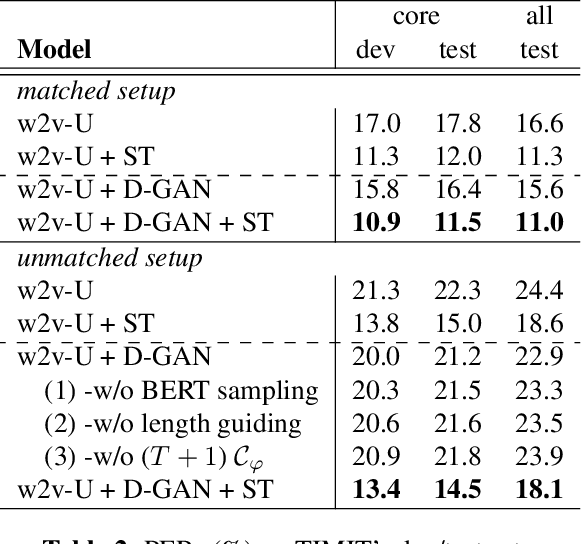
We enhance the vanilla adversarial training method for unsupervised Automatic Speech Recognition (ASR) by a diffusion-GAN. Our model (1) injects instance noises of various intensities to the generator's output and unlabeled reference text which are sampled from pretrained phoneme language models with a length constraint, (2) asks diffusion timestep-dependent discriminators to separate them, and (3) back-propagates the gradients to update the generator. Word/phoneme error rate comparisons with wav2vec-U under Librispeech (3.1% for test-clean and 5.6% for test-other), TIMIT and MLS datasets, show that our enhancement strategies work effectively.
* 5 pages, 1 figure, accepted by ICASSP 2023
View paper on