 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edger-GAT: Relational Graph Attention Network for Multi-Relational Graphs
Sep 13, 2021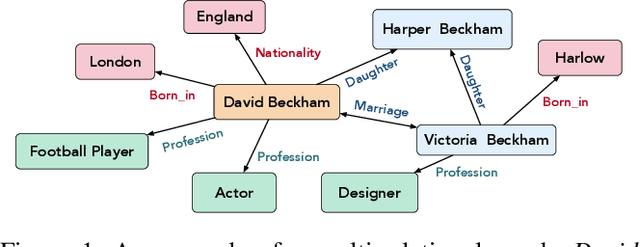

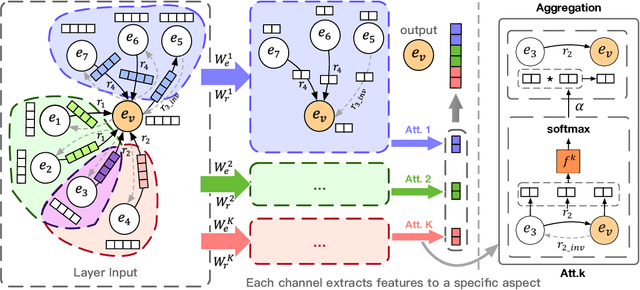

Graph Attention Network (GAT) focuses on modelling simple undirected and single relational graph data only. This limits its ability to deal with more general and complex multi-relational graphs that contain entities with directed links of different labels (e.g., knowledge graphs). Therefore, directly applying GAT on multi-relational graphs leads to sub-optimal solutions. To tackle this issue, we propose r-GAT, a relational graph attention network to learn multi-channel entity representations. Specifically, each channel corresponds to a latent semantic aspect of an entity. This enables us to aggregate neighborhood information for the current aspect using relation features. We further propose a query-aware attention mechanism for subsequent tasks to select useful aspects. Extensive experiments on link prediction and entity classification tasks show that our r-GAT can model multi-relational graphs effectively. Also, we show the interpretability of our approach by case study.
DisenE: Disentangling Knowledge Graph Embeddings
Nov 12, 2020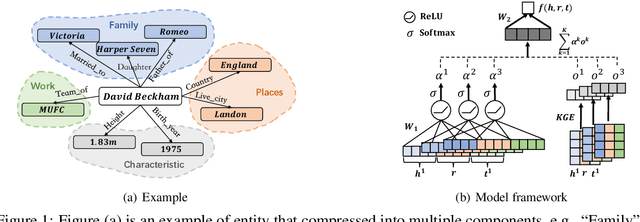
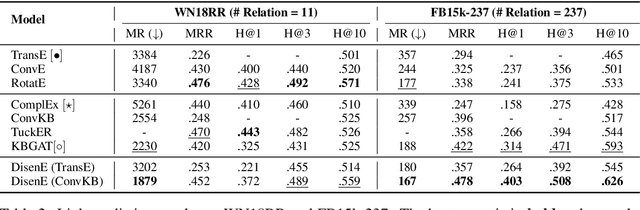
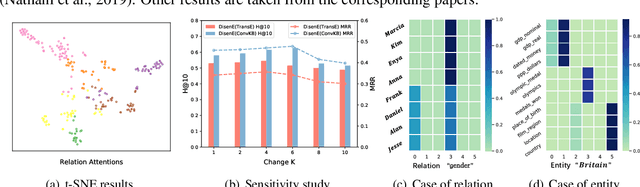
Knowledge graph embedding (KGE), aiming to embed entities and relations into low-dimensional vectors, has attracted wide attention recently. However, the existing research is mainly based on the black-box neural models, which makes it difficult to interpret the learned representation. In this paper, we introduce DisenE, an end-to-end framework to learn disentangled knowledge graph embeddings. Specially, we introduce an attention-based mechanism that enables the model to explicitly focus on relevant components of entity embeddings according to a given relation. Furthermore, we introduce two novel regularizers to encourage each component of the entity representation to independently reflect an isolated semantic aspect. Experimental results demonstrate that our proposed DisenE investigates a perspective to address the interpretability of KGE and is proved to be an effective way to improve the performance of link prediction tasks.
Disentangle-based Continual Graph Representation Learning
Oct 06, 2020
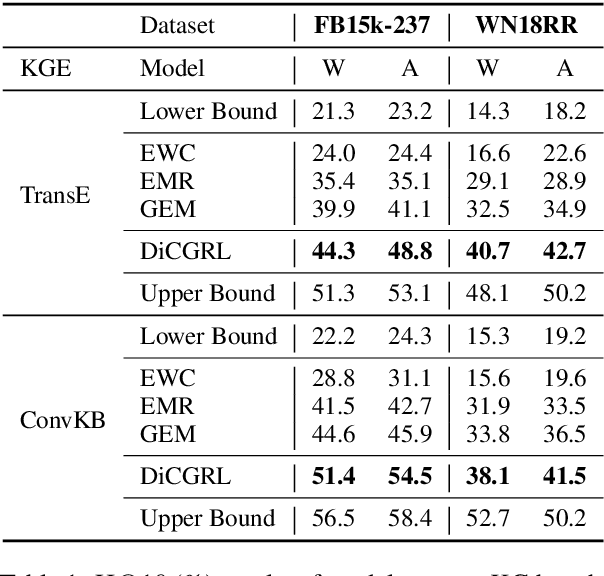
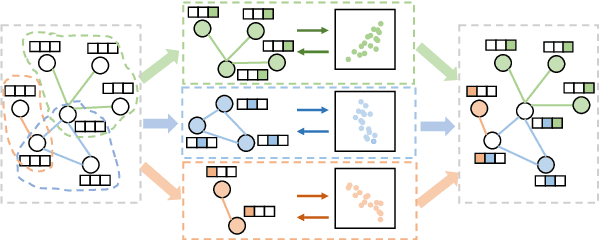

Graph embedding (GE) methods embed nodes (and/or edges) in graph into a low-dimensional semantic space, and have shown its effectiveness in modeling multi-relational data. However, existing GE models are not practical in real-world applications since it overlooked the streaming nature of incoming data. To address this issue, we study the problem of continual graph representation learning which aims to continually train a GE model on new data to learn incessantly emerging multi-relational data while avoiding catastrophically forgetting old learned knowledge. Moreover, we propose a disentangle-based continual graph representation learning (DiCGRL) framework inspired by the human's ability to learn procedural knowledge. The experimental results show that DiCGRL could effectively alleviate the catastrophic forgetting problem and outperform state-of-the-art continual learning models. The code and datasets are released on https://github.com/KXY-PUBLIC/DiCGRL.
NASE: Learning Knowledge Graph Embedding for Link Prediction via Neural Architecture Search
Aug 18, 2020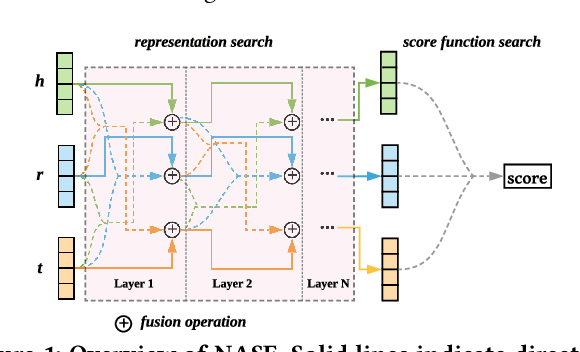
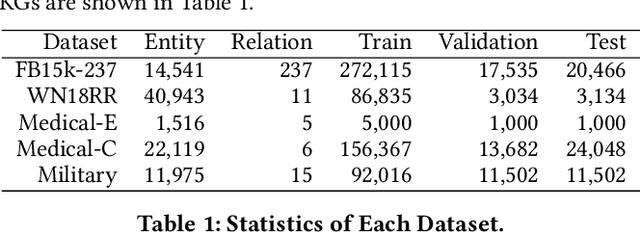
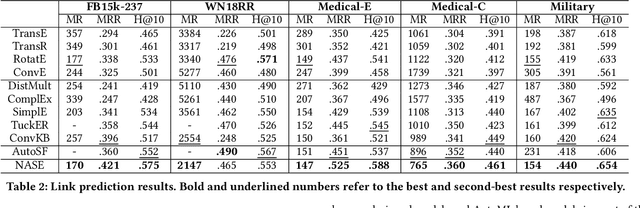

Link prediction is the task of predicting missing connections between entities in the knowledge graph (KG). While various forms of models are proposed for the link prediction task, most of them are designed based on a few known relation patterns in several well-known datasets. Due to the diversity and complexity nature of the real-world KGs, it is inherently difficult to design a model that fits all datasets well. To address this issue, previous work has tried to use Automated Machine Learning (AutoML) to search for the best model for a given dataset. However, their search space is limited only to bilinear model families. In this paper, we propose a novel Neural Architecture Search (NAS) framework for the link prediction task. First, the embeddings of the input triplet are refined by the Representation Search Module. Then, the prediction score is searched within the Score Function Search Module. This framework entails a more general search space, which enables us to take advantage of several mainstream model families, and thus it can potentially achieve better performance. We relax the search space to be continuous so that the architecture can be optimized efficiently using gradient-based search strategies. Experimental results on several benchmark datasets demonstrate the effectiveness of our method compared with several state-of-the-art approaches.
Improving BERT with Self-Supervised Attention
Apr 29, 2020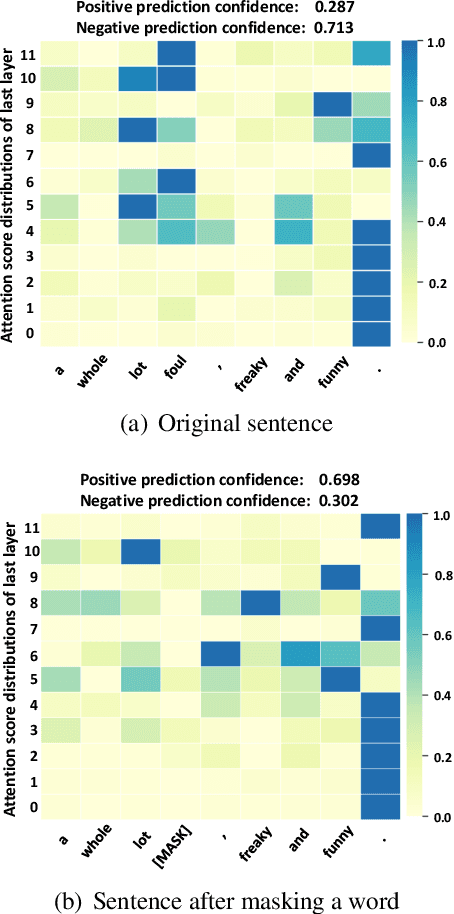
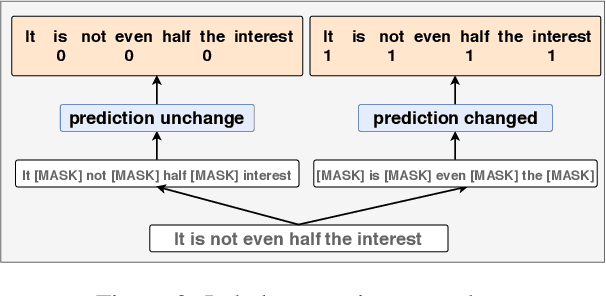

One of the most popular paradigms of applying large, pre-trained NLP models such as BERT is to fine-tune it on a smaller dataset. However, one challenge remains as the fine-tuned model often overfits on smaller datasets. A symptom of this phenomenon is that irrelevant words in the sentences, even when they are obvious to humans, can substantially degrade the performance of these fine-tuned BERT models. In this paper, we propose a novel technique, called Self-Supervised Attention (SSA) to help facilitate this generalization challenge. Specifically, SSA automatically generates weak, token-level attention labels iteratively by "probing" the fine-tuned model from the previous iteration. We investigate two different ways of integrating SSA into BERT and propose a hybrid approach to combine their benefits. Empirically, on a variety of public datasets, we illustrate significant performance improvement using our SSA-enhanced BERT model.
TextNAS: A Neural Architecture Search Space tailored for Text Representation
Dec 23, 2019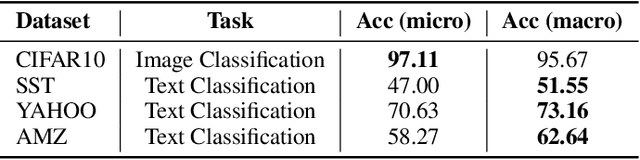


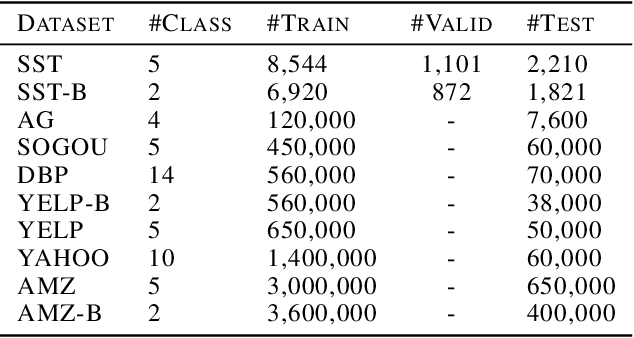
Learning text representation is crucial for text classification and other language related tasks. There are a diverse set of text representation networks in the literature, and how to find the optimal one is a non-trivial problem. Recently, the emerging Neural Architecture Search (NAS) techniques have demonstrated good potential to solve the problem. Nevertheless, most of the existing works of NAS focus on the search algorithms and pay little attention to the search space. In this paper, we argue that the search space is also an important human prior to the success of NAS in different applications. Thus, we propose a novel search space tailored for text representation. Through automatic search, the discovered network architecture outperforms state-of-the-art models on various public datasets on text classification and natural language inference tasks. Furthermore, some of the design principles found in the automatic network agree well with human intuition.
Time-Series Anomaly Detection Service at Microsoft
Jun 10, 2019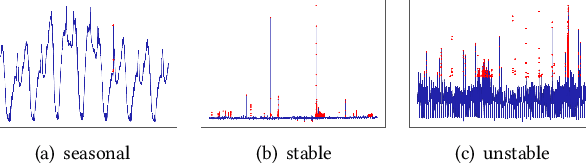
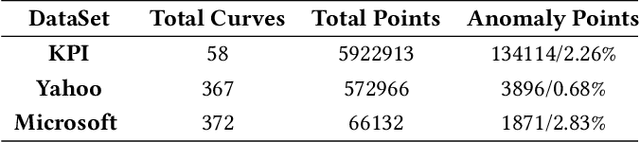
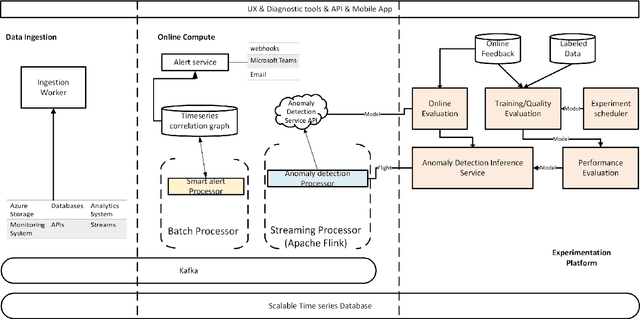

Large companies need to monitor various metrics (for example, Page Views and Revenue) of their applications and services in real time. At Microsoft, we develop a time-series anomaly detection service which helps customers to monitor the time-series continuously and alert for potential incidents on time. In this paper, we introduce the pipeline and algorithm of our anomaly detection service, which is designed to be accurate, efficient and general. The pipeline consists of three major modules, including data ingestion, experimentation platform and online compute. To tackle the problem of time-series anomaly detection, we propose a novel algorithm based on Spectral Residual (SR) and Convolutional Neural Network (CNN). Our work is the first attempt to borrow the SR model from visual saliency detection domain to time-series anomaly detection. Moreover, we innovatively combine SR and CNN together to improve the performance of SR model. Our approach achieves superior experimental results compared with state-of-the-art baselines on both public datasets and Microsoft production data.