 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs
May 12, 2026The continued improvements in language model capability have unlocked their widespread use as drivers of autonomous agents, for example in coding or computer use applications. However, the core of these systems has not changed much since early instruction-tuned models like ChatGPT. Even advanced AI agents function on message exchange formats, successively exchanging messages with users, systems, with itself (i.e. chain-of-thought) and tools in a single stream of computation. This bottleneck to a single stream in chat models leads to a number of limitations: the agent cannot act (generate output) while reading, and in reverse, cannot react to new information while writing. Similarly, the agent cannot act while thinking and cannot think while reading or acting on information. In this work, we show that models can be unblocked by switching from instruction-tuning for sequential message formats to instruction-tuning for multiple, parallel streams of computation, splitting each role into a separate stream. Every forward pass of the language model then simultaneously reads from multiple input streams and generates tokens in multiple output streams, all of which causally depend on earlier timesteps. We argue that this data-driven change remedies a number of usability limitations as outlined above, improves model efficiency through parallelization, improves model security through better separation of concerns and can further improve model monitorability.
Efficient Test-Time Inference via Deterministic Exploration of Truncated Decoding Trees
Apr 22, 2026Self-consistency boosts inference-time performance by sampling multiple reasoning traces in parallel and voting. However, in constrained domains like math and code, this strategy is compute-inefficient because it samples with replacement, repeatedly revisiting the same high-probability prefixes and duplicate completions. We propose Distinct Leaf Enumeration (DLE), a deterministic decoding method that treats truncated sampling as traversal of a pruned decoding tree and systematically enumerates distinct leaves instead of sampling with replacement. This strategy improves inference efficiency in two ways. Algorithmically, it increases coverage of the truncated search space under a fixed budget by exploring previously unvisited high-probability branches. Systemically, it reuses shared prefixes and reduces redundant token generation. Empirically, DLE explores higher-quality reasoning traces than stochastic self-consistency, yielding better performance on math, coding, and general reasoning tasks.
Efficient Parallel Samplers for Recurrent-Depth Models and Their Connection to Diffusion Language Models
Oct 16, 2025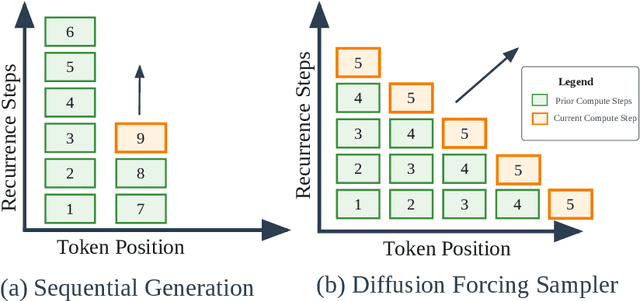
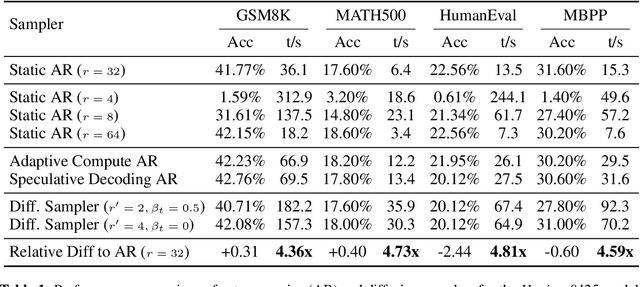
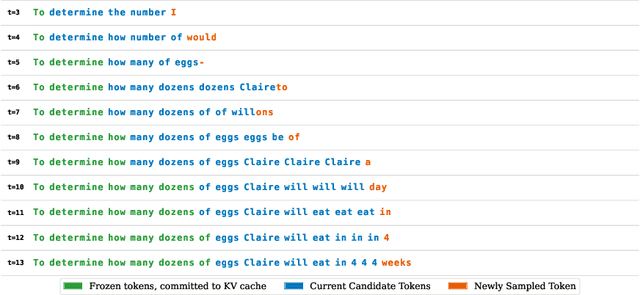
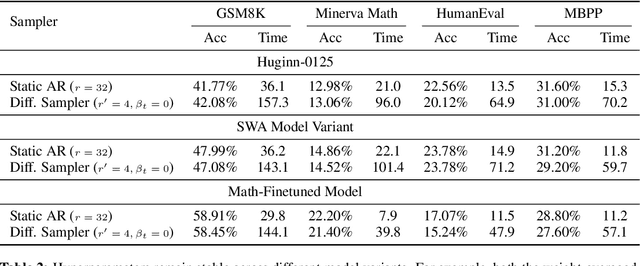
Language models with recurrent depth, also referred to as universal or looped when considering transformers, are defined by the capacity to increase their computation through the repetition of layers. Recent efforts in pretraining have demonstrated that these architectures can scale to modern language modeling tasks while exhibiting advantages in reasoning tasks. In this work, we examine the relationship between recurrent-depth models and diffusion language models. Building on their similarities, we develop a new diffusion forcing sampler for these models to accelerate generation. The sampler advances by decoding new tokens at every forward pass of the model, while the latent states of these tokens can be further refined in parallel through recurrence. Theoretically, generation with our sampler is strictly more expressive than the baseline autoregressive generation using the same time budget on modern hardware. Moreover, this sampler, based on principles from diffusion literature, can be directly applied to existing 3.5B recurrent-depth transformers without any tuning, leading to up to a 5x speedup. Consequently, our findings not only provide an efficient mechanism for parallelizing the extra computation in recurrent-depth models at inference, but also suggest that such models can be naturally viewed as strong continuous, though causal, diffusion language models.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
Fine, I'll Merge It Myself: A Multi-Fidelity Framework for Automated Model Merging
Feb 06, 2025



Reasoning capabilities represent a critical frontier for large language models (LLMs), but developing them requires extensive proprietary datasets and computational resources. One way to efficiently supplement capabilities with is by model merging, which offers a promising alternative by combining multiple models without retraining. However, current merging approaches rely on manually-designed strategies for merging hyperparameters, limiting the exploration of potential model combinations and requiring significant human effort. We propose an Automated Model Merging Framework that enables fine-grained exploration of merging strategies while reducing costs through multi-fidelity approximations. We support both single and multi-objective optimization and introduce two novel search spaces: layerwise fusion (LFS) and depth-wise integration (DIS). Evaluating across a number of benchmarks, we find that the search autonomously finds 1) Merges that further boost single-objective performance, even on tasks the model has already been finetuned on, and 2) Merges that optimize multi-objective frontiers across tasks. Effective merges are found with limited compute, e.g. within less than 500 search steps.
DualTalker: A Cross-Modal Dual Learning Approach for Speech-Driven 3D Facial Animation
Nov 13, 2023



In recent years, audio-driven 3D facial animation has gained significant attention, particularly in applications such as virtual reality, gaming, and video conferencing. However, accurately modeling the intricate and subtle dynamics of facial expressions remains a challenge. Most existing studies approach the facial animation task as a single regression problem, which often fail to capture the intrinsic inter-modal relationship between speech signals and 3D facial animation and overlook their inherent consistency. Moreover, due to the limited availability of 3D-audio-visual datasets, approaches learning with small-size samples have poor generalizability that decreases the performance. To address these issues, in this study, we propose a cross-modal dual-learning framework, termed DualTalker, aiming at improving data usage efficiency as well as relating cross-modal dependencies. The framework is trained jointly with the primary task (audio-driven facial animation) and its dual task (lip reading) and shares common audio/motion encoder components. Our joint training framework facilitates more efficient data usage by leveraging information from both tasks and explicitly capitalizing on the complementary relationship between facial motion and audio to improve performance. Furthermore, we introduce an auxiliary cross-modal consistency loss to mitigate the potential over-smoothing underlying the cross-modal complementary representations, enhancing the mapping of subtle facial expression dynamics. Through extensive experiments and a perceptual user study conducted on the VOCA and BIWI datasets, we demonstrate that our approach outperforms current state-of-the-art methods both qualitatively and quantitatively. We have made our code and video demonstrations available at https://github.com/sabrina-su/iadf.git.
AlphaGAN: Fully Differentiable Architecture Search for Generative Adversarial Networks
Jun 16, 2020
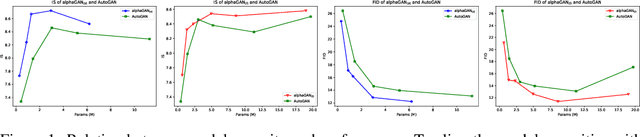
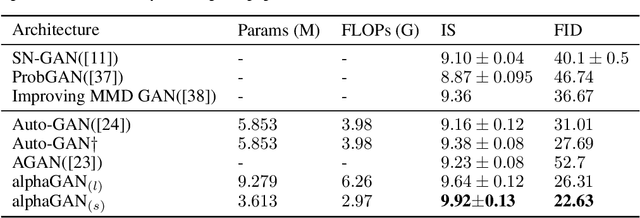
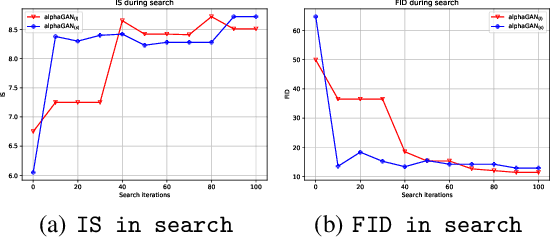
Generative Adversarial Networks (GANs) are formulated as minimax game problems, whereby generators attempt to approach real data distributions by virtue of adversarial learning against discriminators. The intrinsic problem complexity poses the challenge to enhance the performance of generative networks. In this work, we aim to boost model learning from the perspective of network architectures, by incorporating recent progress on automated architecture search into GANs. To this end, we propose a fully differentiable search framework for generative adversarial networks, dubbed alphaGAN. The searching process is formalized as solving a bi-level minimax optimization problem, in which the outer-level objective aims for seeking a suitable network architecture towards pure Nash Equilibrium conditioned on the generator and the discriminator network parameters optimized with a traditional GAN loss in the inner level. The entire optimization performs a first-order method by alternately minimizing the two-level objective in a fully differentiable manner, enabling architecture search to be completed in an enormous search space. Extensive experiments on CIFAR-10 and STL-10 datasets show that our algorithm can obtain high-performing architectures only with 3-GPU hours on a single GPU in the search space comprised of approximate 2 ? 1011 possible configurations. We also provide a comprehensive analysis on the behavior of the searching process and the properties of searched architectures, which would benefit further research on architectures for generative models. Pretrained models and codes are available at https://github.com/yuesongtian/AlphaGAN.
TextNAS: A Neural Architecture Search Space tailored for Text Representation
Dec 23, 2019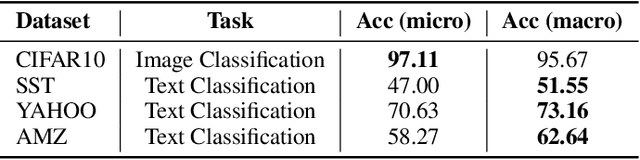


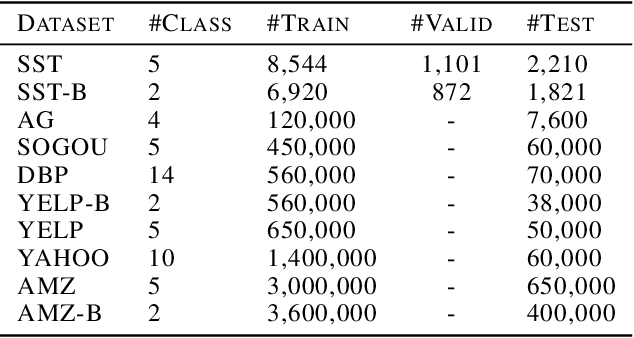
Learning text representation is crucial for text classification and other language related tasks. There are a diverse set of text representation networks in the literature, and how to find the optimal one is a non-trivial problem. Recently, the emerging Neural Architecture Search (NAS) techniques have demonstrated good potential to solve the problem. Nevertheless, most of the existing works of NAS focus on the search algorithms and pay little attention to the search space. In this paper, we argue that the search space is also an important human prior to the success of NAS in different applications. Thus, we propose a novel search space tailored for text representation. Through automatic search, the discovered network architecture outperforms state-of-the-art models on various public datasets on text classification and natural language inference tasks. Furthermore, some of the design principles found in the automatic network agree well with human intuition.