 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Be So Dense: Sparse-to-Sparse GAN Training Without Sacrificing Performance
Mar 05, 2022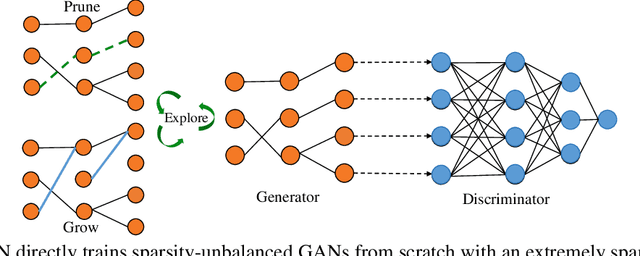

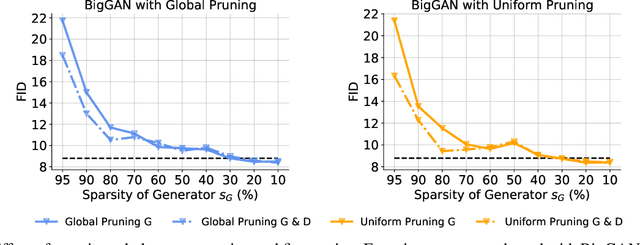

Generative adversarial networks (GANs) have received an upsurging interest since being proposed due to the high quality of the generated data. While achieving increasingly impressive results, the resource demands associated with the large model size hinders the usage of GANs in resource-limited scenarios. For inference, the existing model compression techniques can reduce the model complexity with comparable performance. However, the training efficiency of GANs has less been explored due to the fragile training process of GANs. In this paper, we, for the first time, explore the possibility of directly training sparse GAN from scratch without involving any dense or pre-training steps. Even more unconventionally, our proposed method enables directly training sparse unbalanced GANs with an extremely sparse generator from scratch. Instead of training full GANs, we start with sparse GANs and dynamically explore the parameter space spanned over the generator throughout training. Such a sparse-to-sparse training procedure enhances the capacity of the highly sparse generator progressively while sticking to a fixed small parameter budget with appealing training and inference efficiency gains. Extensive experiments with modern GAN architectures validate the effectiveness of our method. Our sparsified GANs, trained from scratch in one single run, are able to outperform the ones learned by expensive iterative pruning and re-training. Perhaps most importantly, we find instead of inheriting parameters from expensive pre-trained GANs, directly training sparse GANs from scratch can be a much more efficient solution. For example, only training with a 80% sparse generator and a 70% sparse discriminator, our method can achieve even better performance than the dense BigGAN.
DGL-GAN: Discriminator Guided Learning for GAN Compression
Dec 13, 2021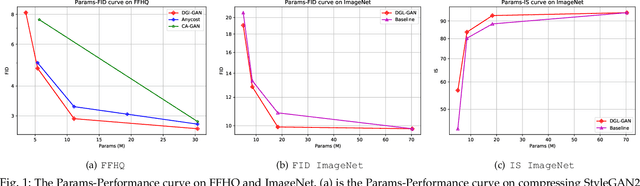
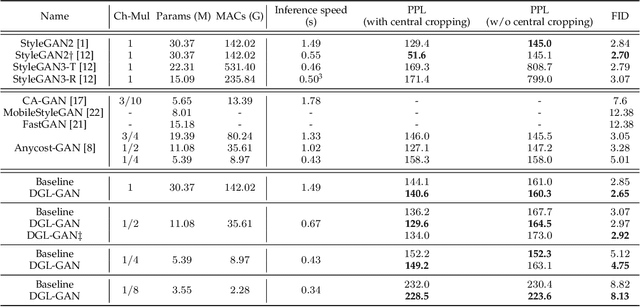


Generative Adversarial Networks (GANs) with high computation costs, e.g., BigGAN and StyleGAN2, have achieved remarkable results in synthesizing high resolution and diverse images with high fidelity from random noises. Reducing the computation cost of GANs while keeping generating photo-realistic images is an urgent and challenging field for their broad applications on computational resource-limited devices. In this work, we propose a novel yet simple {\bf D}iscriminator {\bf G}uided {\bf L}earning approach for compressing vanilla {\bf GAN}, dubbed {\bf DGL-GAN}. Motivated by the phenomenon that the teacher discriminator may contain some meaningful information, we transfer the knowledge merely from the teacher discriminator via the adversarial function. We show DGL-GAN is valid since empirically, learning from the teacher discriminator could facilitate the performance of student GANs, verified by extensive experimental findings. Furthermore, we propose a two-stage training strategy for training DGL-GAN, which can largely stabilize its training process and achieve superior performance when we apply DGL-GAN to compress the two most representative large-scale vanilla GANs, i.e., StyleGAN2 and BigGAN. Experiments show that DGL-GAN achieves state-of-the-art (SOTA) results on both StyleGAN2 (FID 2.92 on FFHQ with nearly $1/3$ parameters of StyleGAN2) and BigGAN (IS 93.29 and FID 9.92 on ImageNet with nearly $1/4$ parameters of BigGAN) and also outperforms several existing vanilla GAN compression techniques. Moreover, DGL-GAN is also effective in boosting the performance of original uncompressed GANs, original uncompressed StyleGAN2 boosted with DGL-GAN achieves FID 2.65 on FFHQ, which achieves a new state-of-the-art performance. Code and models are available at \url{https://github.com/yuesongtian/DGL-GAN}.
AlphaGAN: Fully Differentiable Architecture Search for Generative Adversarial Networks
Jun 16, 2020
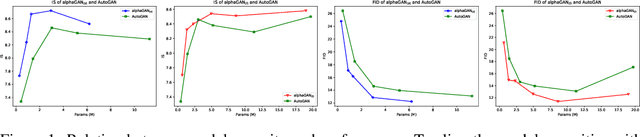
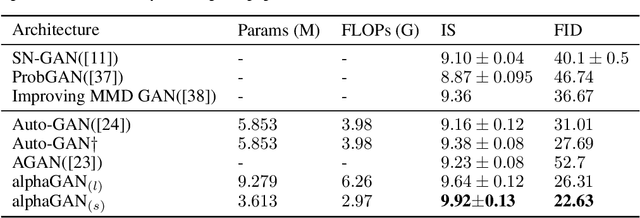
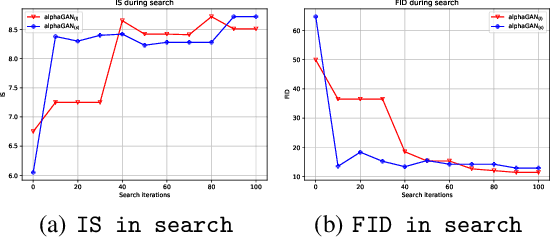
Generative Adversarial Networks (GANs) are formulated as minimax game problems, whereby generators attempt to approach real data distributions by virtue of adversarial learning against discriminators. The intrinsic problem complexity poses the challenge to enhance the performance of generative networks. In this work, we aim to boost model learning from the perspective of network architectures, by incorporating recent progress on automated architecture search into GANs. To this end, we propose a fully differentiable search framework for generative adversarial networks, dubbed alphaGAN. The searching process is formalized as solving a bi-level minimax optimization problem, in which the outer-level objective aims for seeking a suitable network architecture towards pure Nash Equilibrium conditioned on the generator and the discriminator network parameters optimized with a traditional GAN loss in the inner level. The entire optimization performs a first-order method by alternately minimizing the two-level objective in a fully differentiable manner, enabling architecture search to be completed in an enormous search space. Extensive experiments on CIFAR-10 and STL-10 datasets show that our algorithm can obtain high-performing architectures only with 3-GPU hours on a single GPU in the search space comprised of approximate 2 ? 1011 possible configurations. We also provide a comprehensive analysis on the behavior of the searching process and the properties of searched architectures, which would benefit further research on architectures for generative models. Pretrained models and codes are available at https://github.com/yuesongtian/AlphaGAN.