 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Be So Dense: Sparse-to-Sparse GAN Training Without Sacrificing Performance
Paper and Code
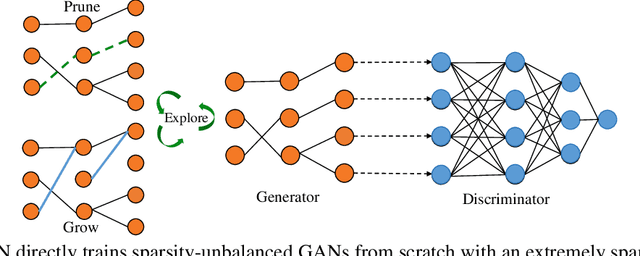

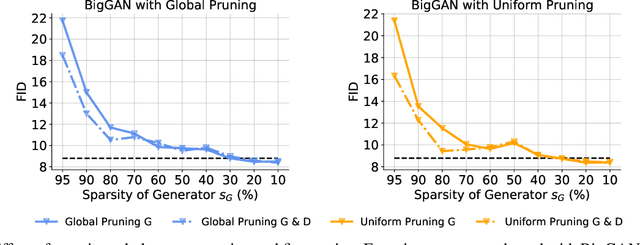

Generative adversarial networks (GANs) have received an upsurging interest since being proposed due to the high quality of the generated data. While achieving increasingly impressive results, the resource demands associated with the large model size hinders the usage of GANs in resource-limited scenarios. For inference, the existing model compression techniques can reduce the model complexity with comparable performance. However, the training efficiency of GANs has less been explored due to the fragile training process of GANs. In this paper, we, for the first time, explore the possibility of directly training sparse GAN from scratch without involving any dense or pre-training steps. Even more unconventionally, our proposed method enables directly training sparse unbalanced GANs with an extremely sparse generator from scratch. Instead of training full GANs, we start with sparse GANs and dynamically explore the parameter space spanned over the generator throughout training. Such a sparse-to-sparse training procedure enhances the capacity of the highly sparse generator progressively while sticking to a fixed small parameter budget with appealing training and inference efficiency gains. Extensive experiments with modern GAN architectures validate the effectiveness of our method. Our sparsified GANs, trained from scratch in one single run, are able to outperform the ones learned by expensive iterative pruning and re-training. Perhaps most importantly, we find instead of inheriting parameters from expensive pre-trained GANs, directly training sparse GANs from scratch can be a much more efficient solution. For example, only training with a 80% sparse generator and a 70% sparse discriminator, our method can achieve even better performance than the dense BigGAN.