 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriming, Path-dependence, and Plasticity: Understanding the molding of user-LLM interaction and its implications from (many) chat logs in the wild
May 07, 2026User interactions with LLMs are shaped by prior experiences and individual exploration, but in-lab studies do not provide system designers with visibility into these in-the-wild factors. This work explores a new approach to studying real-world user-LLM interactions through large-scale chat logs from the wild. Through analysis of 140K chatbot sessions from 7,955 anonymized global users over time, we demonstrate key patterns in user expressions despite varied tasks: (1) LLM users are not tabula rasa, nor are they constantly adapting; rather, interaction patterns form and stabilize rapidly through individual early trajectories; (2) Longitudinal outcomes, such as recurring text patterns and retention rates, are strongly correlated with early exploration; (3) Parallel dynamics are present, including organizing expressions by task types such as emotional support, or in response to model-version updates. These results present an ``agency paradox'': despite LLM input spaces being unconstrained and user-driven, we in fact see less user exploration. We call for design consideration surrounding the molding procedure and its incorporation in future research.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
What We Talk About When We Talk About LMs: Implicit Paradigm Shifts and the Ship of Language Models
Jul 02, 2024The term Language Models (LMs), as a time-specific collection of models of interest, is constantly reinvented, with its referents updated much like the $\textit{Ship of Theseus}$ replaces its parts but remains the same ship in essence. In this paper, we investigate this $\textit{Ship of Language Models}$ problem, wherein scientific evolution takes the form of continuous, implicit retrofits of key existing terms. We seek to initiate a novel perspective of scientific progress, in addition to the more well-studied emergence of new terms. To this end, we construct the data infrastructure based on recent NLP publications. Then, we perform a series of text-based analyses toward a detailed, quantitative understanding of the use of Language Models as a term of art. Our work highlights how systems and theories influence each other in scientific discourse, and we call for attention to the transformation of this Ship that we all are contributing to.
More than Classification: A Unified Framework for Event Temporal Relation Extraction
May 28, 2023



Event temporal relation extraction~(ETRE) is usually formulated as a multi-label classification task, where each type of relation is simply treated as a one-hot label. This formulation ignores the meaning of relations and wipes out their intrinsic dependency. After examining the relation definitions in various ETRE tasks, we observe that all relations can be interpreted using the start and end time points of events. For example, relation \textit{Includes} could be interpreted as event 1 starting no later than event 2 and ending no earlier than event 2. In this paper, we propose a unified event temporal relation extraction framework, which transforms temporal relations into logical expressions of time points and completes the ETRE by predicting the relations between certain time point pairs. Experiments on TB-Dense and MATRES show significant improvements over a strong baseline and outperform the state-of-the-art model by 0.3\% on both datasets. By representing all relations in a unified framework, we can leverage the relations with sufficient data to assist the learning of other relations, thus achieving stable improvement in low-data scenarios. When the relation definitions are changed, our method can quickly adapt to the new ones by simply modifying the logic expressions that map time points to new event relations. The code is released at \url{https://github.com/AndrewZhe/A-Unified-Framework-for-ETRE}.
Does Recommend-Revise Produce Reliable Annotations? An Analysis on Missing Instances in DocRED
Apr 17, 2022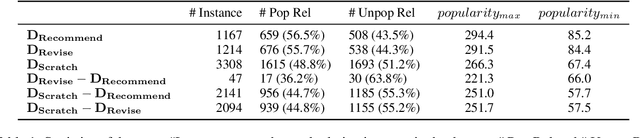
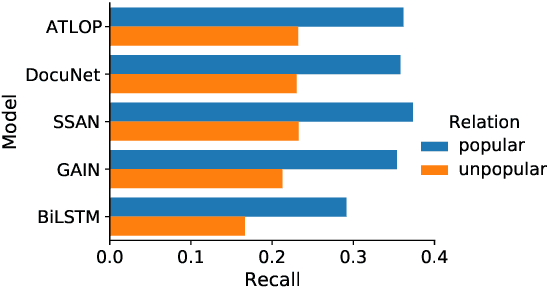
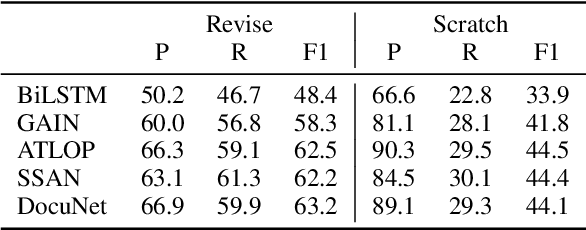
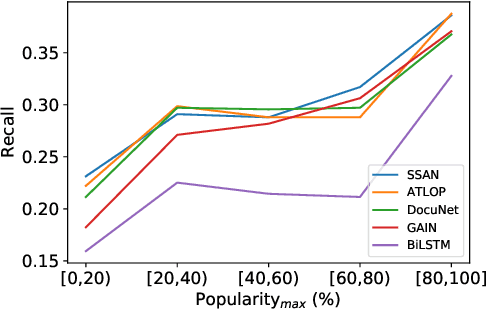
DocRED is a widely used dataset for document-level relation extraction. In the large-scale annotation, a \textit{recommend-revise} scheme is adopted to reduce the workload. Within this scheme, annotators are provided with candidate relation instances from distant supervision, and they then manually supplement and remove relational facts based on the recommendations. However, when comparing DocRED with a subset relabeled from scratch, we find that this scheme results in a considerable amount of false negative samples and an obvious bias towards popular entities and relations. Furthermore, we observe that the models trained on DocRED have low recall on our relabeled dataset and inherit the same bias in the training data. Through the analysis of annotators' behaviors, we figure out the underlying reason for the problems above: the scheme actually discourages annotators from supplementing adequate instances in the revision phase. We appeal to future research to take into consideration the issues with the recommend-revise scheme when designing new models and annotation schemes. The relabeled dataset is released at \url{https://github.com/AndrewZhe/Revisit-DocRED}, to serve as a more reliable test set of document RE models.
Exploring Distantly-Labeled Rationales in Neural Network Models
Jun 03, 2021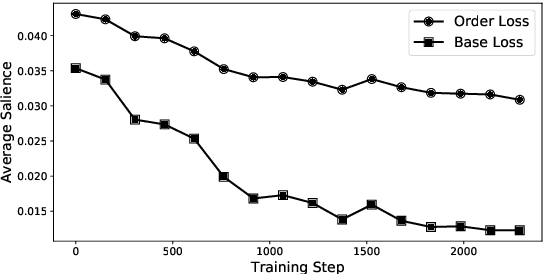
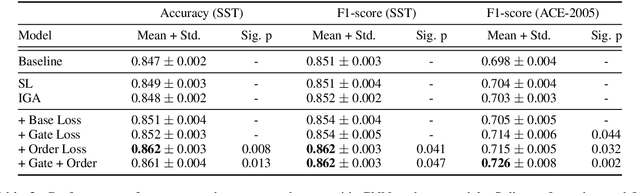
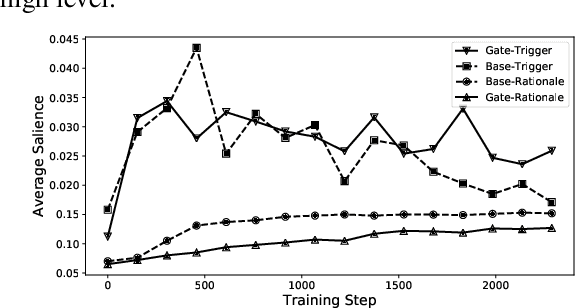
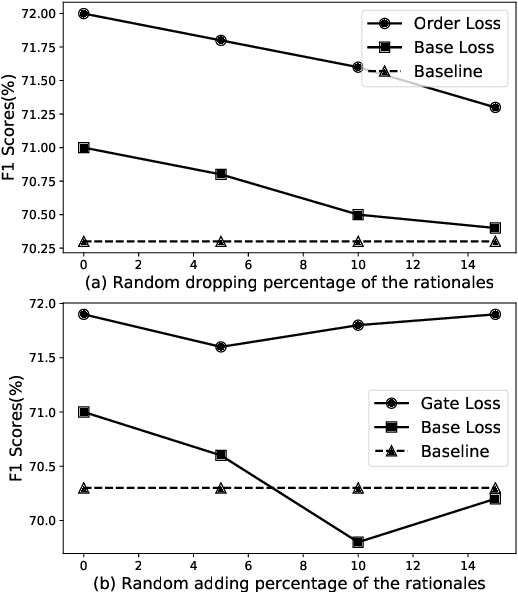
Recent studies strive to incorporate various human rationales into neural networks to improve model performance, but few pay attention to the quality of the rationales. Most existing methods distribute their models' focus to distantly-labeled rationale words entirely and equally, while ignoring the potential important non-rationale words and not distinguishing the importance of different rationale words. In this paper, we propose two novel auxiliary loss functions to make better use of distantly-labeled rationales, which encourage models to maintain their focus on important words beyond labeled rationales (PINs) and alleviate redundant training on non-helpful rationales (NoIRs). Experiments on two representative classification tasks show that our proposed methods can push a classification model to effectively learn crucial clues from non-perfect rationales while maintaining the ability to spread its focus to other unlabeled important words, thus significantly outperform existing methods.
Three Sentences Are All You Need: Local Path Enhanced Document Relation Extraction
Jun 03, 2021
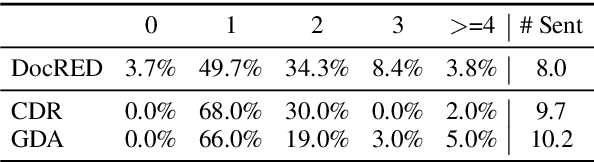
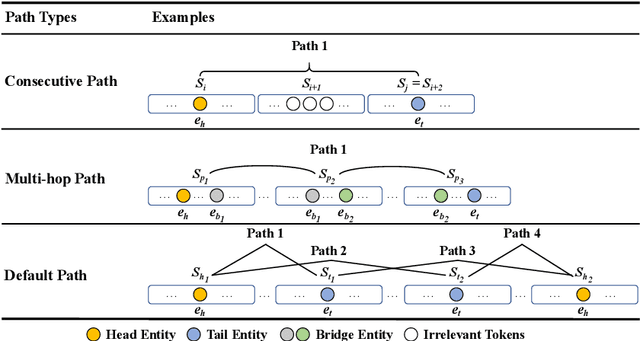
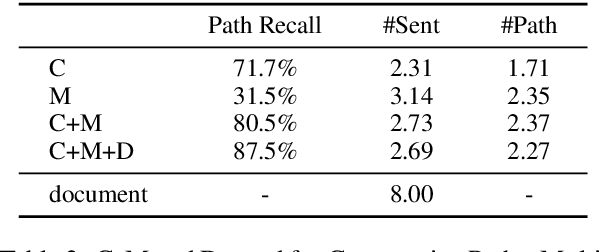
Document-level Relation Extraction (RE) is a more challenging task than sentence RE as it often requires reasoning over multiple sentences. Yet, human annotators usually use a small number of sentences to identify the relationship between a given entity pair. In this paper, we present an embarrassingly simple but effective method to heuristically select evidence sentences for document-level RE, which can be easily combined with BiLSTM to achieve good performance on benchmark datasets, even better than fancy graph neural network based methods. We have released our code at https://github.com/AndrewZhe/Three-Sentences-Are-All-You-Need.