 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Distantly-Labeled Rationales in Neural Network Models
Paper and Code
Jun 03, 2021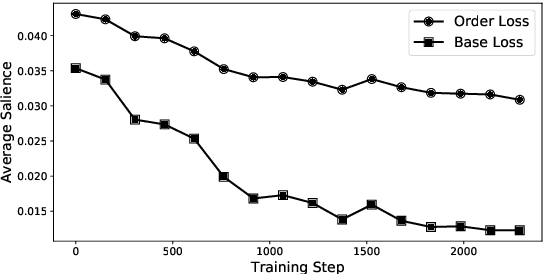
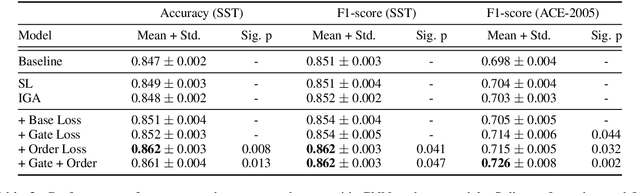
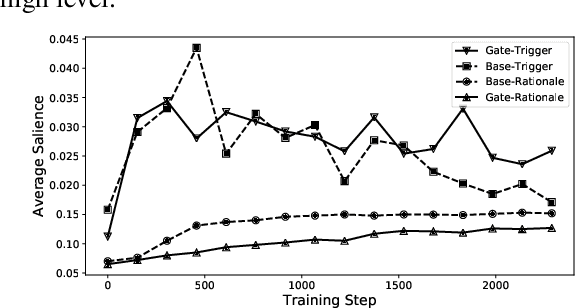
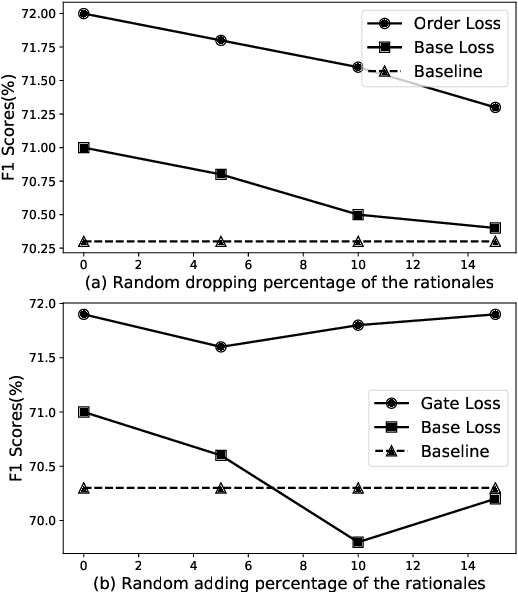
Recent studies strive to incorporate various human rationales into neural networks to improve model performance, but few pay attention to the quality of the rationales. Most existing methods distribute their models' focus to distantly-labeled rationale words entirely and equally, while ignoring the potential important non-rationale words and not distinguishing the importance of different rationale words. In this paper, we propose two novel auxiliary loss functions to make better use of distantly-labeled rationales, which encourage models to maintain their focus on important words beyond labeled rationales (PINs) and alleviate redundant training on non-helpful rationales (NoIRs). Experiments on two representative classification tasks show that our proposed methods can push a classification model to effectively learn crucial clues from non-perfect rationales while maintaining the ability to spread its focus to other unlabeled important words, thus significantly outperform existing methods.