 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
AvatarVTON: 4D Virtual Try-On for Animatable Avatars
Oct 06, 2025We propose AvatarVTON, the first 4D virtual try-on framework that generates realistic try-on results from a single in-shop garment image, enabling free pose control, novel-view rendering, and diverse garment choices. Unlike existing methods, AvatarVTON supports dynamic garment interactions under single-view supervision, without relying on multi-view garment captures or physics priors. The framework consists of two key modules: (1) a Reciprocal Flow Rectifier, a prior-free optical-flow correction strategy that stabilizes avatar fitting and ensures temporal coherence; and (2) a Non-Linear Deformer, which decomposes Gaussian maps into view-pose-invariant and view-pose-specific components, enabling adaptive, non-linear garment deformations. To establish a benchmark for 4D virtual try-on, we extend existing baselines with unified modules for fair qualitative and quantitative comparisons. Extensive experiments show that AvatarVTON achieves high fidelity, diversity, and dynamic garment realism, making it well-suited for AR/VR, gaming, and digital-human applications.
NexusGS: Sparse View Synthesis with Epipolar Depth Priors in 3D Gaussian Splatting
Mar 24, 2025Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) have noticeably advanced photo-realistic novel view synthesis using images from densely spaced camera viewpoints. However, these methods struggle in few-shot scenarios due to limited supervision. In this paper, we present NexusGS, a 3DGS-based approach that enhances novel view synthesis from sparse-view images by directly embedding depth information into point clouds, without relying on complex manual regularizations. Exploiting the inherent epipolar geometry of 3DGS, our method introduces a novel point cloud densification strategy that initializes 3DGS with a dense point cloud, reducing randomness in point placement while preventing over-smoothing and overfitting. Specifically, NexusGS comprises three key steps: Epipolar Depth Nexus, Flow-Resilient Depth Blending, and Flow-Filtered Depth Pruning. These steps leverage optical flow and camera poses to compute accurate depth maps, while mitigating the inaccuracies often associated with optical flow. By incorporating epipolar depth priors, NexusGS ensures reliable dense point cloud coverage and supports stable 3DGS training under sparse-view conditions. Experiments demonstrate that NexusGS significantly enhances depth accuracy and rendering quality, surpassing state-of-the-art methods by a considerable margin. Furthermore, we validate the superiority of our generated point clouds by substantially boosting the performance of competing methods. Project page: https://usmizuki.github.io/NexusGS/.
D$^4$-VTON: Dynamic Semantics Disentangling for Differential Diffusion based Virtual Try-On
Jul 21, 2024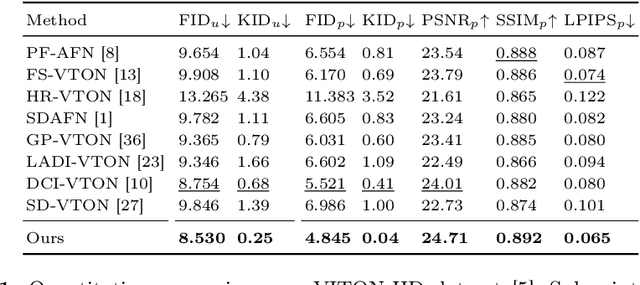
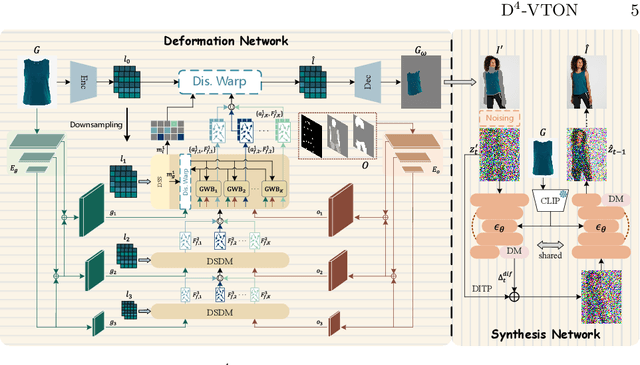
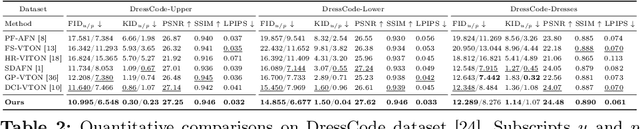
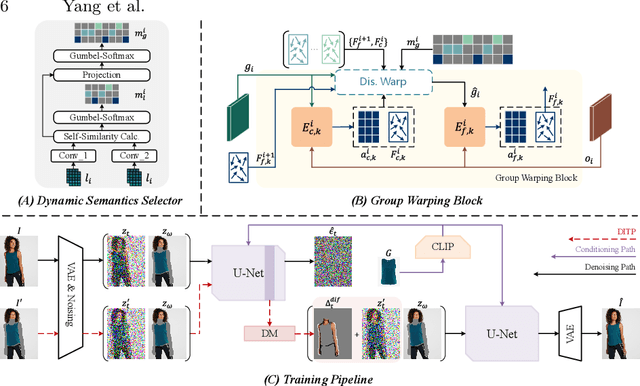
In this paper, we introduce D$^4$-VTON, an innovative solution for image-based virtual try-on. We address challenges from previous studies, such as semantic inconsistencies before and after garment warping, and reliance on static, annotation-driven clothing parsers. Additionally, we tackle the complexities in diffusion-based VTON models when handling simultaneous tasks like inpainting and denoising. Our approach utilizes two key technologies: Firstly, Dynamic Semantics Disentangling Modules (DSDMs) extract abstract semantic information from garments to create distinct local flows, improving precise garment warping in a self-discovered manner. Secondly, by integrating a Differential Information Tracking Path (DITP), we establish a novel diffusion-based VTON paradigm. This path captures differential information between incomplete try-on inputs and their complete versions, enabling the network to handle multiple degradations independently, thereby minimizing learning ambiguities and achieving realistic results with minimal overhead. Extensive experiments demonstrate that D$^4$-VTON significantly outperforms existing methods in both quantitative metrics and qualitative evaluations, demonstrating its capability in generating realistic images and ensuring semantic consistency.