 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024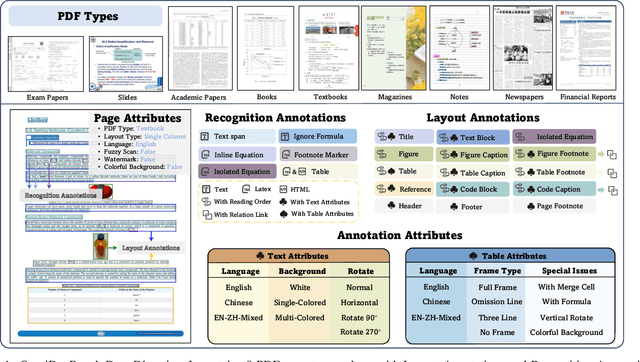
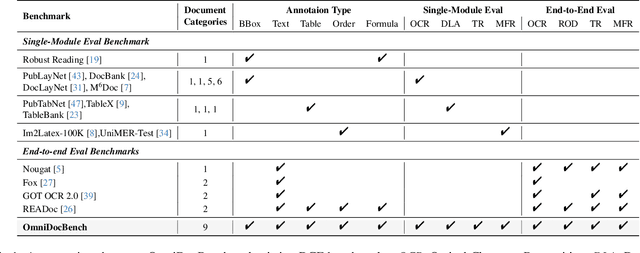
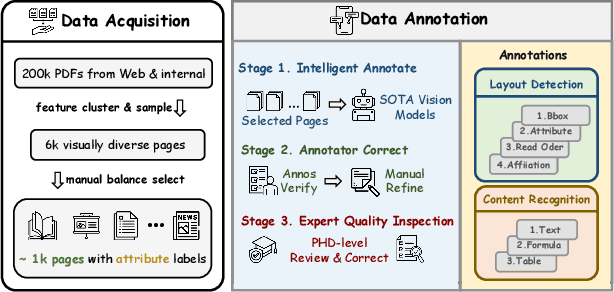
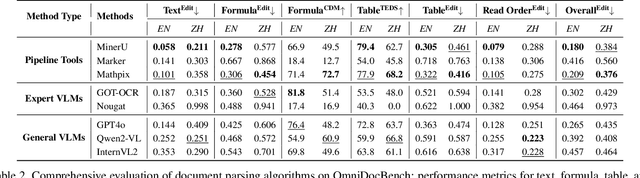
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.
Continuous Geometry-Aware Graph Diffusion via Hyperbolic Neural PDE
Jun 03, 2024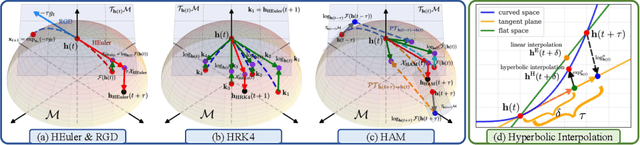
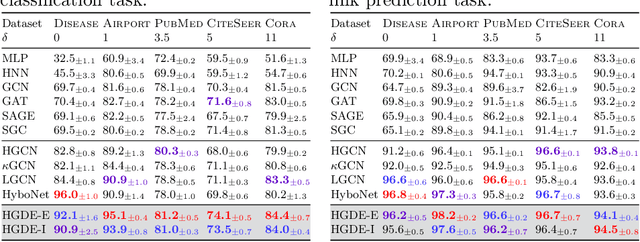
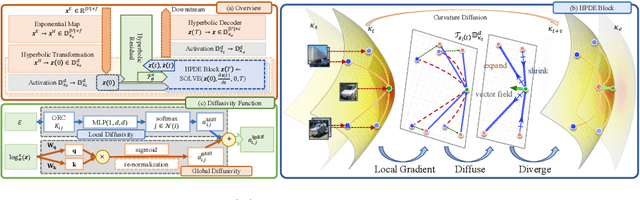
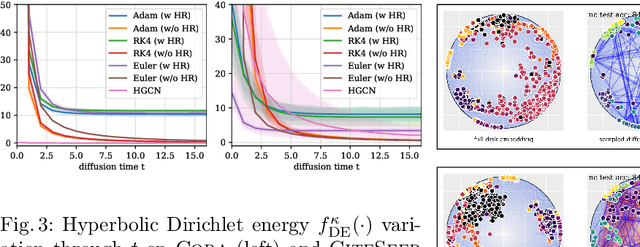
While Hyperbolic Graph Neural Network (HGNN) has recently emerged as a powerful tool dealing with hierarchical graph data, the limitations of scalability and efficiency hinder itself from generalizing to deep models. In this paper, by envisioning depth as a continuous-time embedding evolution, we decouple the HGNN and reframe the information propagation as a partial differential equation, letting node-wise attention undertake the role of diffusivity within the Hyperbolic Neural PDE (HPDE). By introducing theoretical principles \textit{e.g.,} field and flow, gradient, divergence, and diffusivity on a non-Euclidean manifold for HPDE integration, we discuss both implicit and explicit discretization schemes to formulate numerical HPDE solvers. Further, we propose the Hyperbolic Graph Diffusion Equation (HGDE) -- a flexible vector flow function that can be integrated to obtain expressive hyperbolic node embeddings. By analyzing potential energy decay of embeddings, we demonstrate that HGDE is capable of modeling both low- and high-order proximity with the benefit of local-global diffusivity functions. Experiments on node classification and link prediction and image-text classification tasks verify the superiority of the proposed method, which consistently outperforms various competitive models by a significant margin.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024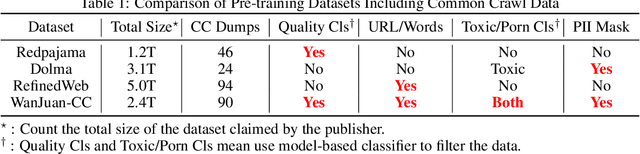
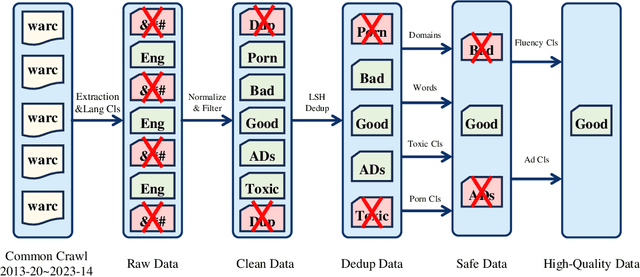
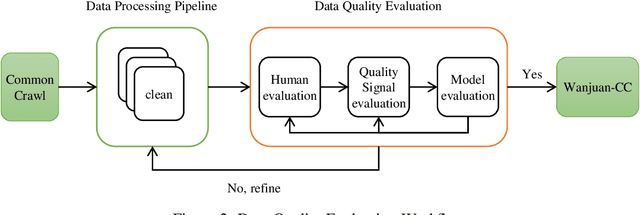

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
Deep Learning for MIMO Channel Estimation: Interpretation, Performance, and Comparison
Nov 05, 2019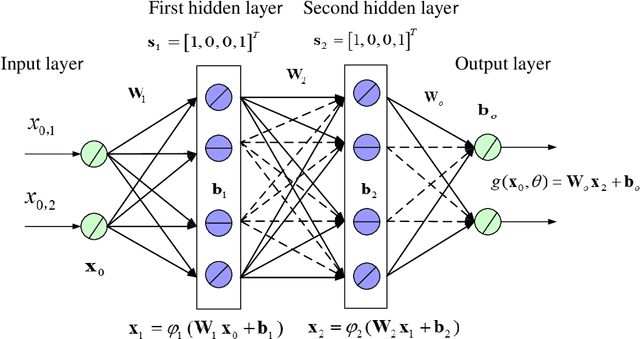
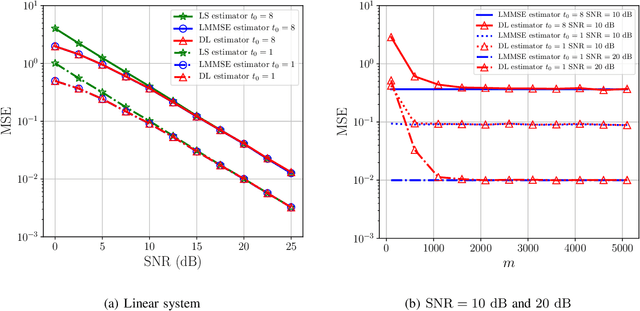
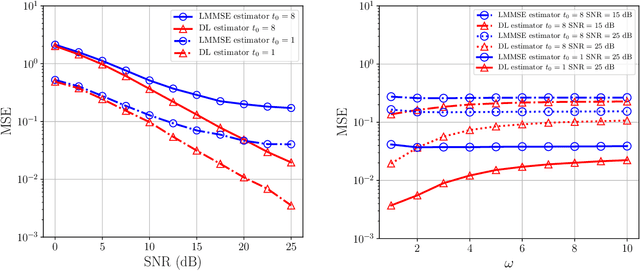
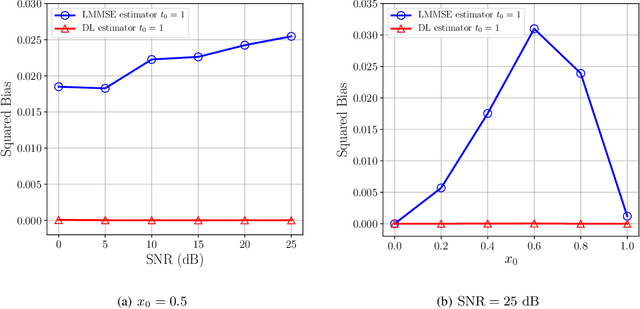
Deep learning (DL) has emerged as an effective tool for channel estimation in wireless communication systems, especially under some imperfect environments. However, even with such unprecedented success, DL methods still serve as black boxes and the lack of explanations on their internal mechanism severely limits further improvement and extension. In this paper, we present a preliminary theoretical analysis on DL based channel estimation for multiple-antenna systems to understand and interpret its internal mechanism. Deep neural network (DNN) with rectified linear unit (ReLU) activation function is mathematically equivalent to a set of local linear functions corresponding to different input regions. Hence, the DL estimator built on it can achieve universal approximation to a large family of functions by making efficient use of piecewise linearity. We demonstrate that DL based channel estimation does not restrict to any specific signal model and will approach to the minimum mean-squared error (MMSE) estimation in various scenarios without requiring any prior knowledge of channel statistics. Therefore, DL based channel estimation outperforms or is comparable with traditional channel estimation. Simulation results confirm the accuracy of the proposed interpretation and demonstrate the effectiveness of DL based channel estimation under both linear and nonlinear signal models.