 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerU-Popo: Universal Post-Processing Model for Structured Document Parsing
May 24, 2026VLM-based OCR models have become the de facto choice for document parsing, as they can accurately extract page-level elements (e.g., paragraphs within individual pages) together with their bounding boxes and textual content. However, downstream applications such as RAG require coherent document-level information, whereas these models often break cross-page continuity and fail to recover disrupted structures, such as paragraphs and tables truncated by page boundaries. Such relationships are not confined to a single page; instead, they require joint analysis of titles, paragraphs, tables, and images spanning multiple pages. A natural solution is therefore to reuse existing OCR outputs and reconstruct document-level logical structures through post-processing. To this end, we propose MinerU-Popo, a lightweight and universal framework for POst-Processing OCR outputs, which converts page-level results from diverse parsers into coherent document-level structures. MinerU-Popo decomposes the problem into four focused subtasks: text truncation recovery, table truncation recovery, title hierarchy reconstruction, and image-text association. To address these effectively, we build a task-oriented data engine with task-specific input filtering, and use the generated data (30K) to fine-tune a lightweight post-processing model (Qwen3-VL-4B). To support long documents, we introduce dynamic chunking with overlap-based synchronization, which aligns chunk-level outputs from the fine-tuned model and preserves global consistency. Finally, we assemble the aligned outputs into a tree-structured document representation, further enriched with node chunking and summaries for downstream retrieval and analysis. Empirical results show MinerU-Popo improves title-hierarchy TEDS by at least 20% across all five tested OCR models, improves RAG accuracy and reduces per-query latency.
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Apr 06, 2026Current document parsing methods compete primarily on model architecture innovation, while systematic engineering of training data remains underexplored. Yet SOTA models of different architectures and parameter scales exhibit highly consistent failure patterns on the same set of hard samples, suggesting that the performance bottleneck stems from shared deficiencies in training data rather than architecture itself. Building on this finding, we present \minerupro, which advances the state of the art solely through data engineering and training strategy optimization while keeping the 1.2B-parameter architecture of \mineru completely fixed. At its core is a Data Engine co-designed around coverage, informativeness, and annotation accuracy: Diversity-and-Difficulty-Aware Sampling expands training data from under 10M to 65.5M samples while correcting distribution shift; Cross-Model Consistency Verification leverages output agreement among heterogeneous models to assess sample difficulty and generate reliable annotations; the Judge-and-Refine pipeline improves annotation quality for hard samples through render-then-verify iterative correction. A three-stage progressive training strategy -- large-scale pre-training, hard sample fine-tuning, and GRPO alignment -- sequentially exploits these data at different quality tiers. On the evaluation front, we fix element-matching biases in OmniDocBench~v1.5 and introduce a Hard subset, establishing the more discriminative OmniDocBench~v1.6 protocol. Without any architectural modification, \minerupro achieves 95.69 on OmniDocBench~v1.6, improving over the same-architecture baseline by 2.71 points and surpassing all existing methods including models with over 200$\times$ more parameters.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
Dec 10, 2024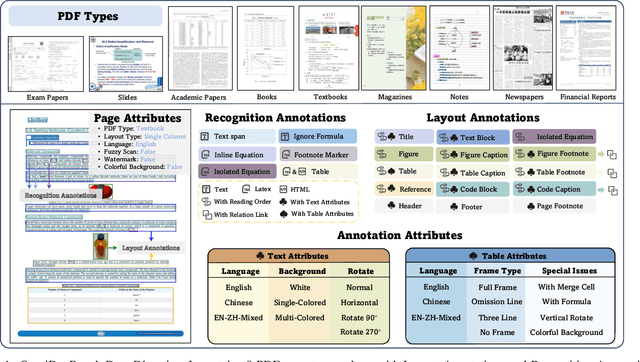
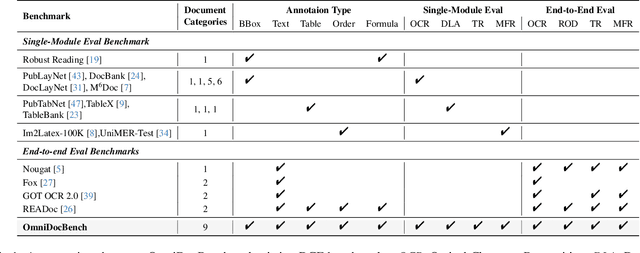
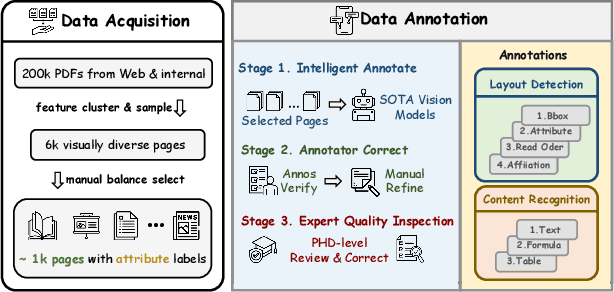
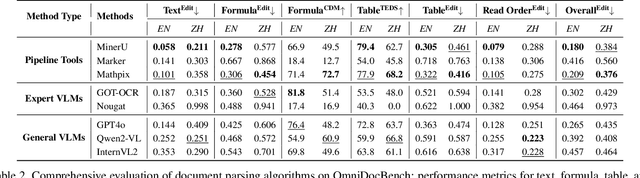
Document content extraction is crucial in computer vision, especially for meeting the high-quality data needs of large language models (LLMs) and retrieval-augmented generation (RAG) technologies. However, current document parsing methods suffer from significant limitations in terms of diversity and comprehensive evaluation. To address these challenges, we introduce OmniDocBench, a novel multi-source benchmark designed to advance automated document content extraction. OmniDocBench includes a meticulously curated and annotated high-quality evaluation dataset comprising nine diverse document types, such as academic papers, textbooks, slides, among others. Our benchmark provides a flexible and comprehensive evaluation framework with 19 layout category labels and 14 attribute labels, enabling multi-level assessments across entire datasets, individual modules, or specific data types. Using OmniDocBench, we perform an exhaustive comparative analysis of existing modular pipelines and multimodal end-to-end methods, highlighting their limitations in handling document diversity and ensuring fair evaluation. OmniDocBench establishes a robust, diverse, and fair evaluation standard for the document content extraction field, offering crucial insights for future advancements and fostering the development of document parsing technologies. The codes and dataset is available in https://github.com/opendatalab/OmniDocBench.
MinerU: An Open-Source Solution for Precise Document Content Extraction
Sep 27, 2024



Document content analysis has been a crucial research area in computer vision. Despite significant advancements in methods such as OCR, layout detection, and formula recognition, existing open-source solutions struggle to consistently deliver high-quality content extraction due to the diversity in document types and content. To address these challenges, we present MinerU, an open-source solution for high-precision document content extraction. MinerU leverages the sophisticated PDF-Extract-Kit models to extract content from diverse documents effectively and employs finely-tuned preprocessing and postprocessing rules to ensure the accuracy of the final results. Experimental results demonstrate that MinerU consistently achieves high performance across various document types, significantly enhancing the quality and consistency of content extraction. The MinerU open-source project is available at https://github.com/opendatalab/MinerU.
LIMP: Large Language Model Enhanced Intent-aware Mobility Prediction
Aug 23, 2024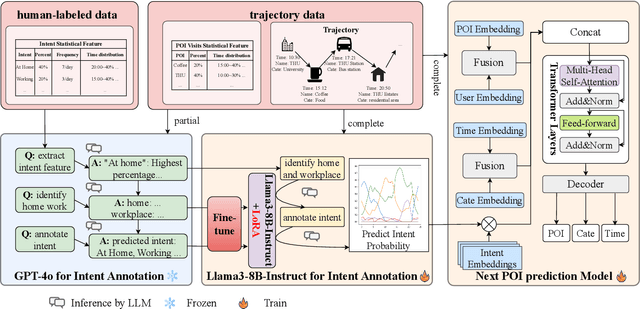

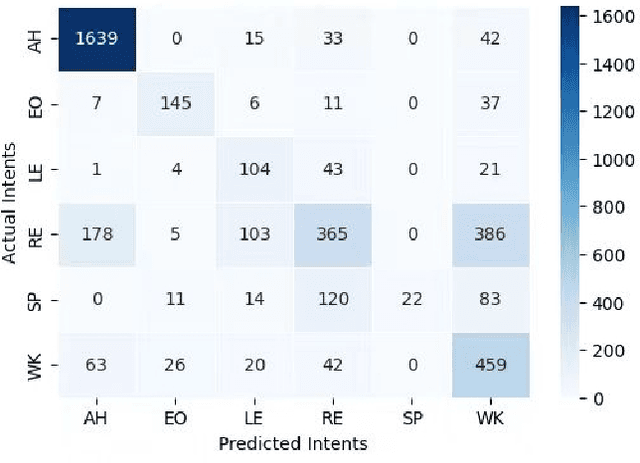
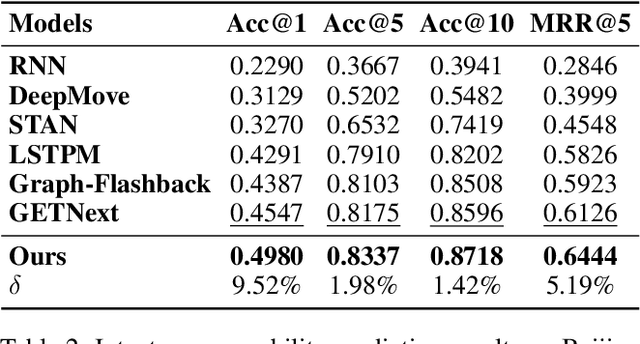
Human mobility prediction is essential for applications like urban planning and transportation management, yet it remains challenging due to the complex, often implicit, intentions behind human behavior. Existing models predominantly focus on spatiotemporal patterns, paying less attention to the underlying intentions that govern movements. Recent advancements in large language models (LLMs) offer a promising alternative research angle for integrating commonsense reasoning into mobility prediction. However, it is a non-trivial problem because LLMs are not natively built for mobility intention inference, and they also face scalability issues and integration difficulties with spatiotemporal models. To address these challenges, we propose a novel LIMP (LLMs for Intent-ware Mobility Prediction) framework. Specifically, LIMP introduces an "Analyze-Abstract-Infer" (A2I) agentic workflow to unleash LLM's commonsense reasoning power for mobility intention inference. Besides, we design an efficient fine-tuning scheme to transfer reasoning power from commercial LLM to smaller-scale, open-source language model, ensuring LIMP's scalability to millions of mobility records. Moreover, we propose a transformer-based intention-aware mobility prediction model to effectively harness the intention inference ability of LLM. Evaluated on two real-world datasets, LIMP significantly outperforms baseline models, demonstrating improved accuracy in next-location prediction and effective intention inference. The interpretability of intention-aware mobility prediction highlights our LIMP framework's potential for real-world applications. Codes and data can be found in https://github.com/tsinghua-fib-lab/LIMP .
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.