 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRSplat: Feed-Forward Super-Resolution Gaussian Splatting from Sparse Multi-View Images
Nov 15, 2025Feed-forward 3D reconstruction from sparse, low-resolution (LR) images is a crucial capability for real-world applications, such as autonomous driving and embodied AI. However, existing methods often fail to recover fine texture details. This limitation stems from the inherent lack of high-frequency information in LR inputs. To address this, we propose \textbf{SRSplat}, a feed-forward framework that reconstructs high-resolution 3D scenes from only a few LR views. Our main insight is to compensate for the deficiency of texture information by jointly leveraging external high-quality reference images and internal texture cues. We first construct a scene-specific reference gallery, generated for each scene using Multimodal Large Language Models (MLLMs) and diffusion models. To integrate this external information, we introduce the \textit{Reference-Guided Feature Enhancement (RGFE)} module, which aligns and fuses features from the LR input images and their reference twin image. Subsequently, we train a decoder to predict the Gaussian primitives using the multi-view fused feature obtained from \textit{RGFE}. To further refine predicted Gaussian primitives, we introduce \textit{Texture-Aware Density Control (TADC)}, which adaptively adjusts Gaussian density based on the internal texture richness of the LR inputs. Extensive experiments demonstrate that our SRSplat outperforms existing methods on various datasets, including RealEstate10K, ACID, and DTU, and exhibits strong cross-dataset and cross-resolution generalization capabilities.
Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Nov 10, 2025



Dynamic Gaussian Splatting approaches have achieved remarkable performance for 4D scene reconstruction. However, these approaches rely on dense-frame video sequences for photorealistic reconstruction. In real-world scenarios, due to equipment constraints, sometimes only sparse frames are accessible. In this paper, we propose Sparse4DGS, the first method for sparse-frame dynamic scene reconstruction. We observe that dynamic reconstruction methods fail in both canonical and deformed spaces under sparse-frame settings, especially in areas with high texture richness. Sparse4DGS tackles this challenge by focusing on texture-rich areas. For the deformation network, we propose Texture-Aware Deformation Regularization, which introduces a texture-based depth alignment loss to regulate Gaussian deformation. For the canonical Gaussian field, we introduce Texture-Aware Canonical Optimization, which incorporates texture-based noise into the gradient descent process of canonical Gaussians. Extensive experiments show that when taking sparse frames as inputs, our method outperforms existing dynamic or few-shot techniques on NeRF-Synthetic, HyperNeRF, NeRF-DS, and our iPhone-4D datasets.
Division-of-Thoughts: Harnessing Hybrid Language Model Synergy for Efficient On-Device Agents
Feb 06, 2025The rapid expansion of web content has made on-device AI assistants indispensable for helping users manage the increasing complexity of online tasks. The emergent reasoning ability in large language models offer a promising path for next-generation on-device AI agents. However, deploying full-scale Large Language Models (LLMs) on resource-limited local devices is challenging. In this paper, we propose Division-of-Thoughts (DoT), a collaborative reasoning framework leveraging the synergy between locally deployed Smaller-scale Language Models (SLMs) and cloud-based LLMs. DoT leverages a Task Decomposer to elicit the inherent planning abilities in language models to decompose user queries into smaller sub-tasks, which allows hybrid language models to fully exploit their respective strengths. Besides, DoT employs a Task Scheduler to analyze the pair-wise dependency of sub-tasks and create a dependency graph, facilitating parallel reasoning of sub-tasks and the identification of key steps. To allocate the appropriate model based on the difficulty of sub-tasks, DoT leverages a Plug-and-Play Adapter, which is an additional task head attached to the SLM that does not alter the SLM's parameters. To boost adapter's task allocation capability, we propose a self-reinforced training method that relies solely on task execution feedback. Extensive experiments on various benchmarks demonstrate that our DoT significantly reduces LLM costs while maintaining competitive reasoning accuracy. Specifically, DoT reduces the average reasoning time and API costs by 66.12% and 83.57%, while achieving comparable reasoning accuracy with the best baseline methods.
Towards Large Reasoning Models: A Survey on Scaling LLM Reasoning Capabilities
Jan 17, 2025



Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Jan 16, 2025Language has long been conceived as an essential tool for human reasoning. The breakthrough of Large Language Models (LLMs) has sparked significant research interest in leveraging these models to tackle complex reasoning tasks. Researchers have moved beyond simple autoregressive token generation by introducing the concept of "thought" -- a sequence of tokens representing intermediate steps in the reasoning process. This innovative paradigm enables LLMs' to mimic complex human reasoning processes, such as tree search and reflective thinking. Recently, an emerging trend of learning to reason has applied reinforcement learning (RL) to train LLMs to master reasoning processes. This approach enables the automatic generation of high-quality reasoning trajectories through trial-and-error search algorithms, significantly expanding LLMs' reasoning capacity by providing substantially more training data. Furthermore, recent studies demonstrate that encouraging LLMs to "think" with more tokens during test-time inference can further significantly boost reasoning accuracy. Therefore, the train-time and test-time scaling combined to show a new research frontier -- a path toward Large Reasoning Model. The introduction of OpenAI's o1 series marks a significant milestone in this research direction. In this survey, we present a comprehensive review of recent progress in LLM reasoning. We begin by introducing the foundational background of LLMs and then explore the key technical components driving the development of large reasoning models, with a focus on automated data construction, learning-to-reason techniques, and test-time scaling. We also analyze popular open-source projects at building large reasoning models, and conclude with open challenges and future research directions.
LIMP: Large Language Model Enhanced Intent-aware Mobility Prediction
Aug 23, 2024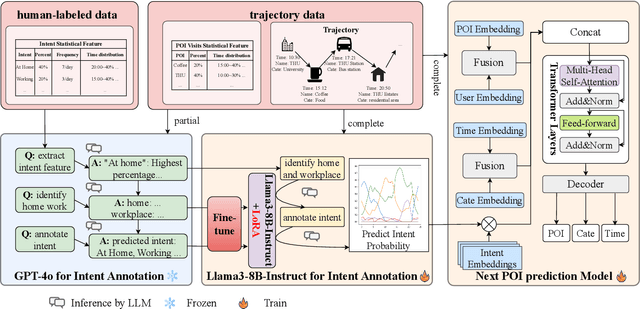

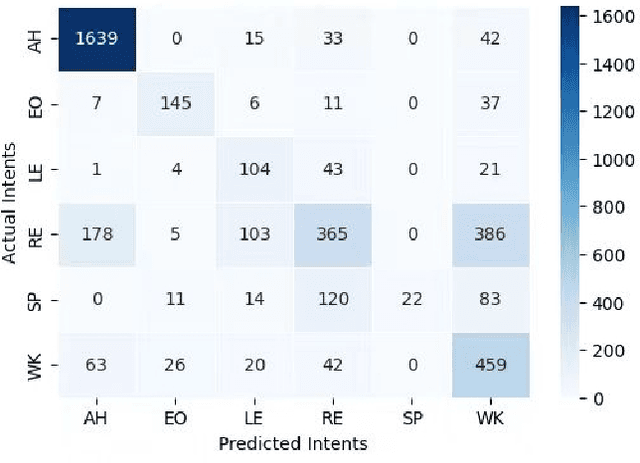
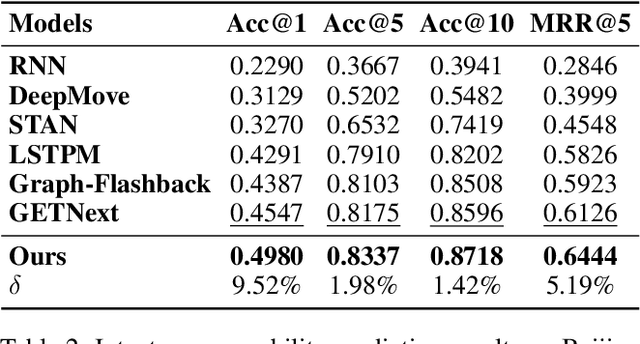
Human mobility prediction is essential for applications like urban planning and transportation management, yet it remains challenging due to the complex, often implicit, intentions behind human behavior. Existing models predominantly focus on spatiotemporal patterns, paying less attention to the underlying intentions that govern movements. Recent advancements in large language models (LLMs) offer a promising alternative research angle for integrating commonsense reasoning into mobility prediction. However, it is a non-trivial problem because LLMs are not natively built for mobility intention inference, and they also face scalability issues and integration difficulties with spatiotemporal models. To address these challenges, we propose a novel LIMP (LLMs for Intent-ware Mobility Prediction) framework. Specifically, LIMP introduces an "Analyze-Abstract-Infer" (A2I) agentic workflow to unleash LLM's commonsense reasoning power for mobility intention inference. Besides, we design an efficient fine-tuning scheme to transfer reasoning power from commercial LLM to smaller-scale, open-source language model, ensuring LIMP's scalability to millions of mobility records. Moreover, we propose a transformer-based intention-aware mobility prediction model to effectively harness the intention inference ability of LLM. Evaluated on two real-world datasets, LIMP significantly outperforms baseline models, demonstrating improved accuracy in next-location prediction and effective intention inference. The interpretability of intention-aware mobility prediction highlights our LIMP framework's potential for real-world applications. Codes and data can be found in https://github.com/tsinghua-fib-lab/LIMP .