 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
MinerU: An Open-Source Solution for Precise Document Content Extraction
Sep 27, 2024



Document content analysis has been a crucial research area in computer vision. Despite significant advancements in methods such as OCR, layout detection, and formula recognition, existing open-source solutions struggle to consistently deliver high-quality content extraction due to the diversity in document types and content. To address these challenges, we present MinerU, an open-source solution for high-precision document content extraction. MinerU leverages the sophisticated PDF-Extract-Kit models to extract content from diverse documents effectively and employs finely-tuned preprocessing and postprocessing rules to ensure the accuracy of the final results. Experimental results demonstrate that MinerU consistently achieves high performance across various document types, significantly enhancing the quality and consistency of content extraction. The MinerU open-source project is available at https://github.com/opendatalab/MinerU.
Investigating Public Fine-Tuning Datasets: A Complex Review of Current Practices from a Construction Perspective
Jul 11, 2024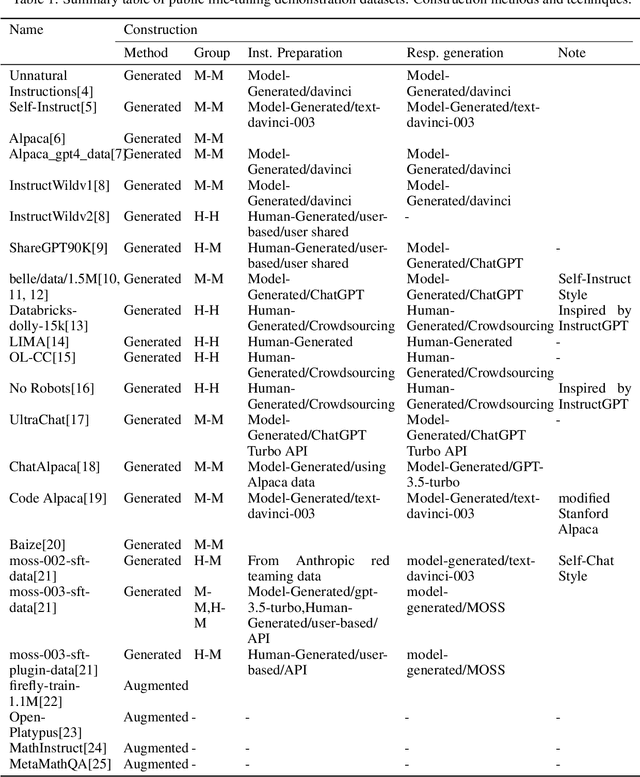
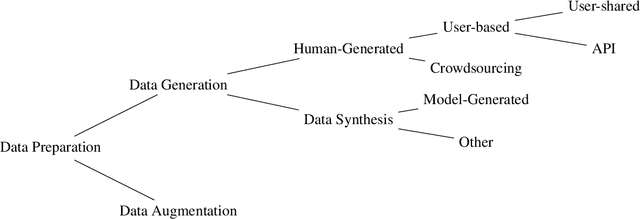
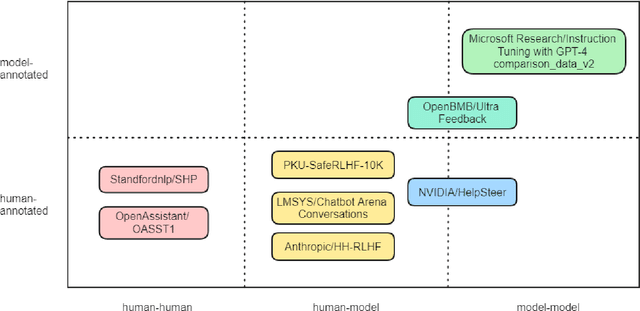
With the rapid development of the large model domain, research related to fine-tuning has concurrently seen significant advancement, given that fine-tuning is a constituent part of the training process for large-scale models. Data engineering plays a fundamental role in the training process of models, which includes data infrastructure, data processing, etc. Data during fine-tuning likewise forms the base for large models. In order to embrace the power and explore new possibilities of fine-tuning datasets, this paper reviews current public fine-tuning datasets from the perspective of data construction. An overview of public fine-tuning datasets from two sides: evolution and taxonomy, is provided in this review, aiming to chart the development trajectory. Construction techniques and methods for public fine-tuning datasets of Large Language Models (LLMs), including data generation and data augmentation among others, are detailed. This elaboration follows the aforementioned taxonomy, specifically across demonstration, comparison, and generalist categories. Additionally, a category tree of data generation techniques has been abstracted in our review to assist researchers in gaining a deeper understanding of fine-tuning datasets from the construction dimension. Our review also summarizes the construction features in different data preparation phases of current practices in this field, aiming to provide a comprehensive overview and inform future research. Fine-tuning dataset practices, encompassing various data modalities, are also discussed from a construction perspective in our review. Towards the end of the article, we offer insights and considerations regarding the future construction and developments of fine-tuning datasets.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.