 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Public Fine-Tuning Datasets: A Complex Review of Current Practices from a Construction Perspective
Paper and Code
Jul 11, 2024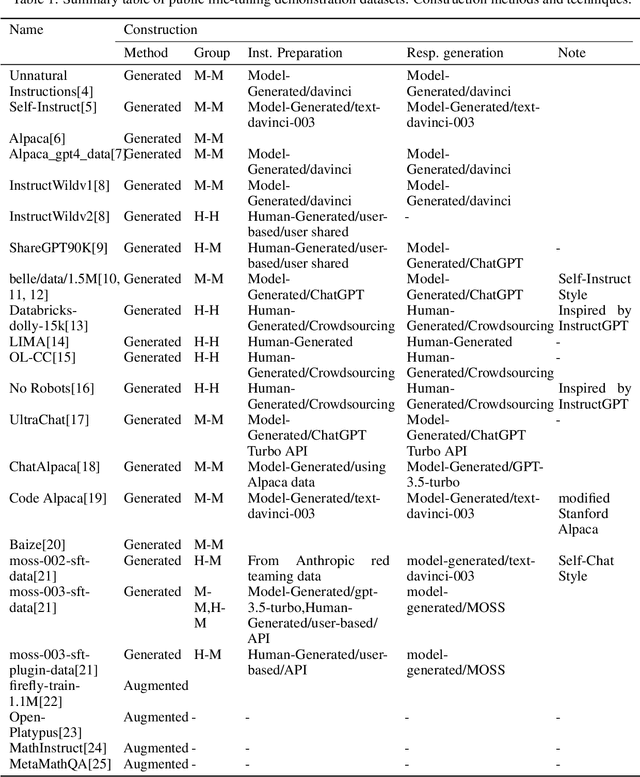
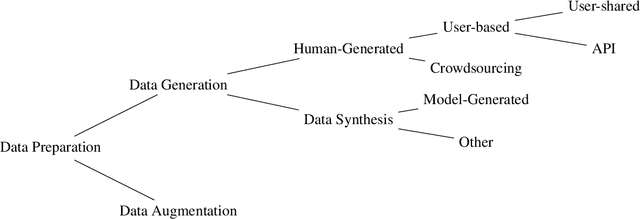
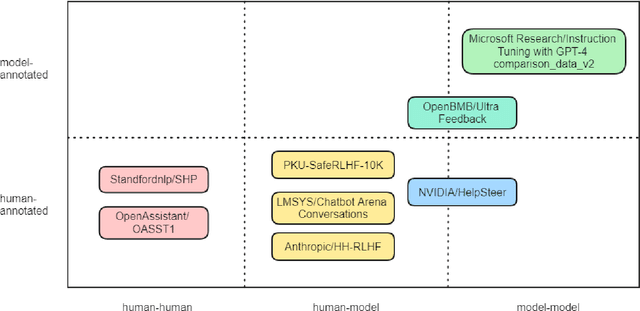
With the rapid development of the large model domain, research related to fine-tuning has concurrently seen significant advancement, given that fine-tuning is a constituent part of the training process for large-scale models. Data engineering plays a fundamental role in the training process of models, which includes data infrastructure, data processing, etc. Data during fine-tuning likewise forms the base for large models. In order to embrace the power and explore new possibilities of fine-tuning datasets, this paper reviews current public fine-tuning datasets from the perspective of data construction. An overview of public fine-tuning datasets from two sides: evolution and taxonomy, is provided in this review, aiming to chart the development trajectory. Construction techniques and methods for public fine-tuning datasets of Large Language Models (LLMs), including data generation and data augmentation among others, are detailed. This elaboration follows the aforementioned taxonomy, specifically across demonstration, comparison, and generalist categories. Additionally, a category tree of data generation techniques has been abstracted in our review to assist researchers in gaining a deeper understanding of fine-tuning datasets from the construction dimension. Our review also summarizes the construction features in different data preparation phases of current practices in this field, aiming to provide a comprehensive overview and inform future research. Fine-tuning dataset practices, encompassing various data modalities, are also discussed from a construction perspective in our review. Towards the end of the article, we offer insights and considerations regarding the future construction and developments of fine-tuning datasets.