 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoTLIP: Improving Language-Image Pre-training for Long Text Understanding
Paper and Code

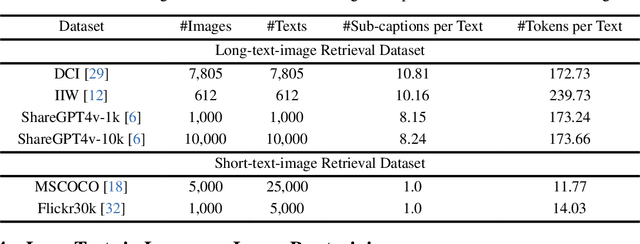


Understanding long text is of great demands in practice but beyond the reach of most language-image pre-training (LIP) models. In this work, we empirically confirm that the key reason causing such an issue is that the training images are usually paired with short captions, leaving certain tokens easily overshadowed by salient tokens. Towards this problem, our initial attempt is to relabel the data with long captions, however, directly learning with which may lead to performance degradation in understanding short text (e.g., in the image classification task). Then, after incorporating corner tokens to aggregate diverse textual information, we manage to help the model catch up to its original level of short text understanding yet greatly enhance its capability of long text understanding. We further look into whether the model can continuously benefit from longer captions and notice a clear trade-off between the performance and the efficiency. Finally, we validate the effectiveness of our approach using a self-constructed large-scale dataset, which consists of 100M long caption oriented text-image pairs. It is noteworthy that, on the task of long-text image retrieval, we beat the competitor using long captions with 11.1% improvement (i.e., from 72.62% to 83.72%). We will release the code, the model, and the new dataset to facilitate the reproducibility and further research. The project page is available at https://wuw2019.github.io/lotlip.