 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZ-Stack Scanning can Improve AI Detection of Mitosis: A Case Study of Meningiomas
Jan 27, 2025



Z-stack scanning is an emerging whole slide imaging technology that captures multiple focal planes alongside the z-axis of a glass slide. Because z-stacking can offer enhanced depth information compared to the single-layer whole slide imaging, this technology can be particularly useful in analyzing small-scaled histopathological patterns. However, its actual clinical impact remains debated with mixed results. To clarify this, we investigate the effect of z-stack scanning on artificial intelligence (AI) mitosis detection of meningiomas. With the same set of 22 Hematoxylin and Eosin meningioma glass slides scanned by three different digital pathology scanners, we tested the performance of three AI pipelines on both single-layer and z-stacked whole slide images (WSIs). Results showed that in all scanner-AI combinations, z-stacked WSIs significantly increased AI's sensitivity (+17.14%) on the mitosis detection with only a marginal impact on precision. Our findings provide quantitative evidence that highlights z-stack scanning as a promising technique for AI mitosis detection, paving the way for more reliable AI-assisted pathology workflows, which can ultimately benefit patient management.
Supporting Mitosis Detection AI Training with Inter-Observer Eye-Gaze Consistencies
Apr 02, 2024

The expansion of artificial intelligence (AI) in pathology tasks has intensified the demand for doctors' annotations in AI development. However, collecting high-quality annotations from doctors is costly and time-consuming, creating a bottleneck in AI progress. This study investigates eye-tracking as a cost-effective technology to collect doctors' behavioral data for AI training with a focus on the pathology task of mitosis detection. One major challenge in using eye-gaze data is the low signal-to-noise ratio, which hinders the extraction of meaningful information. We tackled this by levering the properties of inter-observer eye-gaze consistencies and creating eye-gaze labels from consistent eye-fixations shared by a group of observers. Our study involved 14 non-medical participants, from whom we collected eye-gaze data and generated eye-gaze labels based on varying group sizes. We assessed the efficacy of such eye-gaze labels by training Convolutional Neural Networks (CNNs) and comparing their performance to those trained with ground truth annotations and a heuristic-based baseline. Results indicated that CNNs trained with our eye-gaze labels closely followed the performance of ground-truth-based CNNs, and significantly outperformed the baseline. Although primarily focused on mitosis, we envision that insights from this study can be generalized to other medical imaging tasks.
Population-aware Online Mirror Descent for Mean-Field Games by Deep Reinforcement Learning
Mar 06, 2024Mean Field Games (MFGs) have the ability to handle large-scale multi-agent systems, but learning Nash equilibria in MFGs remains a challenging task. In this paper, we propose a deep reinforcement learning (DRL) algorithm that achieves population-dependent Nash equilibrium without the need for averaging or sampling from history, inspired by Munchausen RL and Online Mirror Descent. Through the design of an additional inner-loop replay buffer, the agents can effectively learn to achieve Nash equilibrium from any distribution, mitigating catastrophic forgetting. The resulting policy can be applied to various initial distributions. Numerical experiments on four canonical examples demonstrate our algorithm has better convergence properties than SOTA algorithms, in particular a DRL version of Fictitious Play for population-dependent policies.
Joint State and Input Estimation of Agent Based on Recursive Kalman Filter Given Prior Knowledge
Nov 15, 2021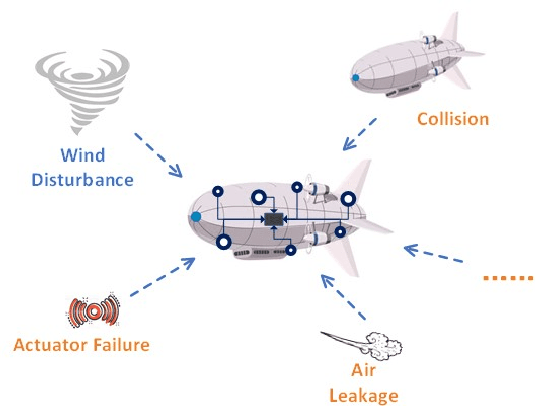
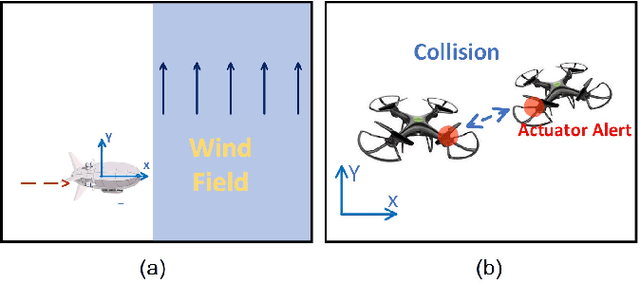
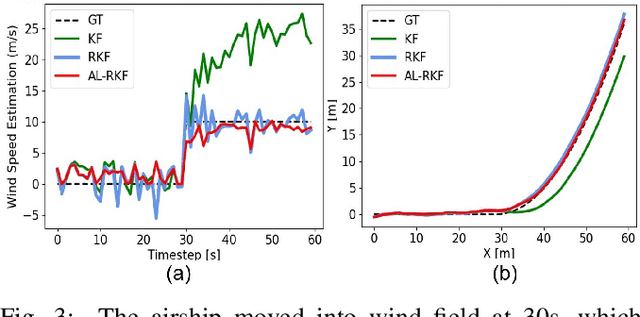
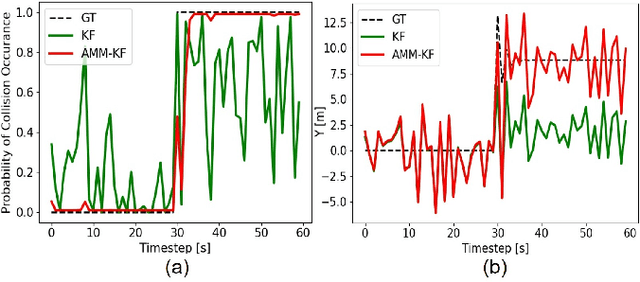
Modern autonomous systems are purposed for many challenging scenarios, where agents will face unexpected events and complicated tasks. The presence of disturbance noise with control command and unknown inputs can negatively impact robot performance. Previous research of joint input and state estimation separately study the continuous and discrete cases without any prior information. This paper combines the continuous space and discrete space estimation into a unified theory based on the Expectation-Maximum (EM) algorithm. By introducing prior knowledge of events as the constraint, inequality optimization problems are formulated to determine a gain matrix or dynamic weights to realize an optimal input estimation with lower variance and more accurate decision-making. Finally, statistical results from experiments show that our algorithm owns 81\% improvement of the variance than KF and 47\% improvement than RKF in continuous space; a remarkable improvement of right decision-making probability of our input estimator in discrete space, identification ability is also analyzed by experiments.