 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation-aware Online Mirror Descent for Mean-Field Games by Deep Reinforcement Learning
Mar 06, 2024Mean Field Games (MFGs) have the ability to handle large-scale multi-agent systems, but learning Nash equilibria in MFGs remains a challenging task. In this paper, we propose a deep reinforcement learning (DRL) algorithm that achieves population-dependent Nash equilibrium without the need for averaging or sampling from history, inspired by Munchausen RL and Online Mirror Descent. Through the design of an additional inner-loop replay buffer, the agents can effectively learn to achieve Nash equilibrium from any distribution, mitigating catastrophic forgetting. The resulting policy can be applied to various initial distributions. Numerical experiments on four canonical examples demonstrate our algorithm has better convergence properties than SOTA algorithms, in particular a DRL version of Fictitious Play for population-dependent policies.
Learning Correlated Equilibria in Mean-Field Games
Aug 22, 2022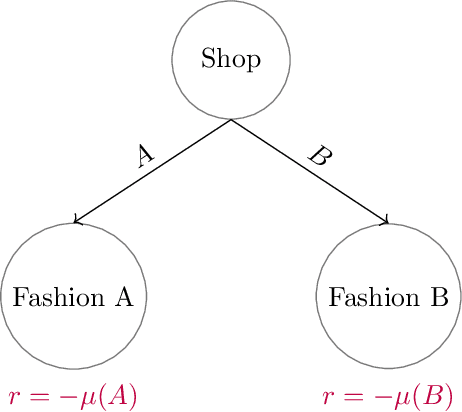
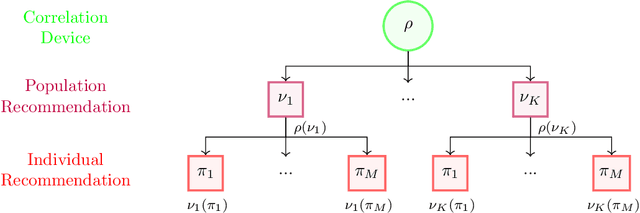
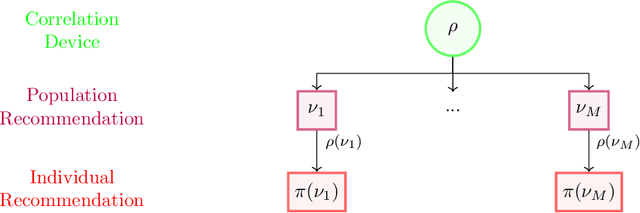
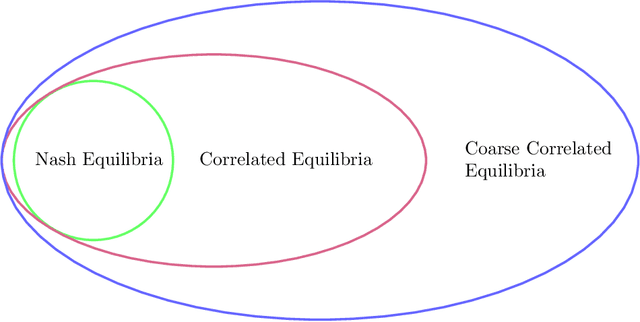
The designs of many large-scale systems today, from traffic routing environments to smart grids, rely on game-theoretic equilibrium concepts. However, as the size of an $N$-player game typically grows exponentially with $N$, standard game theoretic analysis becomes effectively infeasible beyond a low number of players. Recent approaches have gone around this limitation by instead considering Mean-Field games, an approximation of anonymous $N$-player games, where the number of players is infinite and the population's state distribution, instead of every individual player's state, is the object of interest. The practical computability of Mean-Field Nash equilibria, the most studied Mean-Field equilibrium to date, however, typically depends on beneficial non-generic structural properties such as monotonicity or contraction properties, which are required for known algorithms to converge. In this work, we provide an alternative route for studying Mean-Field games, by developing the concepts of Mean-Field correlated and coarse-correlated equilibria. We show that they can be efficiently learnt in \emph{all games}, without requiring any additional assumption on the structure of the game, using three classical algorithms. Furthermore, we establish correspondences between our notions and those already present in the literature, derive optimality bounds for the Mean-Field - $N$-player transition, and empirically demonstrate the convergence of these algorithms on simple games.
Reinforcement Learning for Mean Field Games, with Applications to Economics
Jun 25, 2021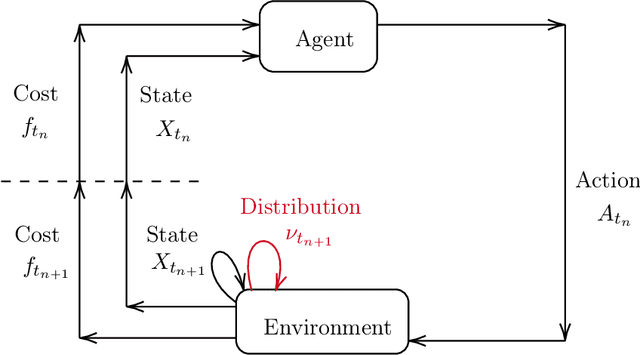
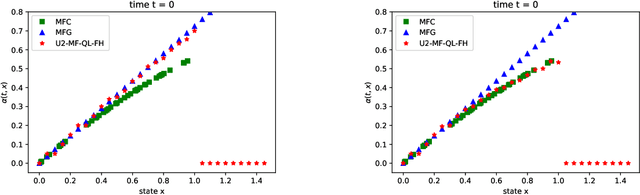
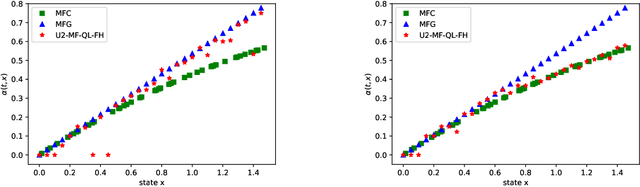
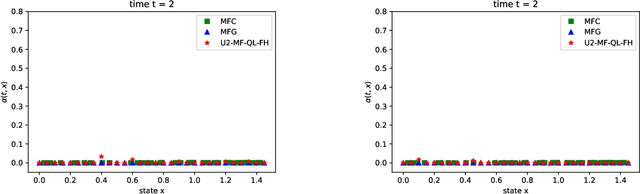
Mean field games (MFG) and mean field control problems (MFC) are frameworks to study Nash equilibria or social optima in games with a continuum of agents. These problems can be used to approximate competitive or cooperative games with a large finite number of agents and have found a broad range of applications, in particular in economics. In recent years, the question of learning in MFG and MFC has garnered interest, both as a way to compute solutions and as a way to model how large populations of learners converge to an equilibrium. Of particular interest is the setting where the agents do not know the model, which leads to the development of reinforcement learning (RL) methods. After reviewing the literature on this topic, we present a two timescale approach with RL for MFG and MFC, which relies on a unified Q-learning algorithm. The main novelty of this method is to simultaneously update an action-value function and a distribution but with different rates, in a model-free fashion. Depending on the ratio of the two learning rates, the algorithm learns either the MFG or the MFC solution. To illustrate this method, we apply it to a mean field problem of accumulated consumption in finite horizon with HARA utility function, and to a trader's optimal liquidation problem.