 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Mean Field Games, with Applications to Economics
Paper and Code
Jun 25, 2021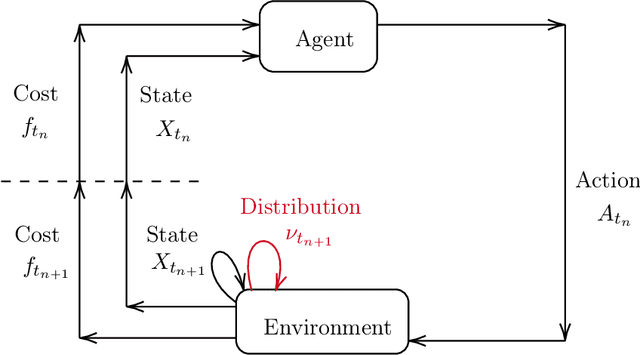
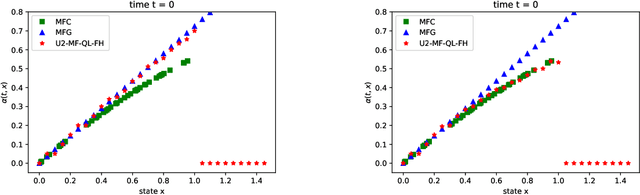
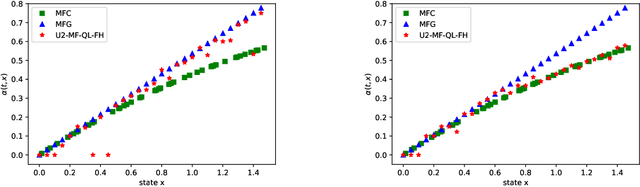
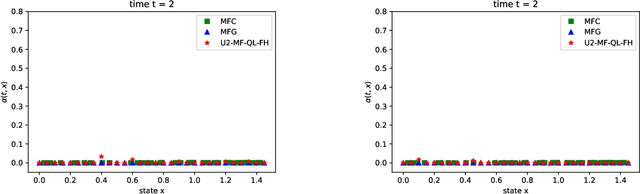
Mean field games (MFG) and mean field control problems (MFC) are frameworks to study Nash equilibria or social optima in games with a continuum of agents. These problems can be used to approximate competitive or cooperative games with a large finite number of agents and have found a broad range of applications, in particular in economics. In recent years, the question of learning in MFG and MFC has garnered interest, both as a way to compute solutions and as a way to model how large populations of learners converge to an equilibrium. Of particular interest is the setting where the agents do not know the model, which leads to the development of reinforcement learning (RL) methods. After reviewing the literature on this topic, we present a two timescale approach with RL for MFG and MFC, which relies on a unified Q-learning algorithm. The main novelty of this method is to simultaneously update an action-value function and a distribution but with different rates, in a model-free fashion. Depending on the ratio of the two learning rates, the algorithm learns either the MFG or the MFC solution. To illustrate this method, we apply it to a mean field problem of accumulated consumption in finite horizon with HARA utility function, and to a trader's optimal liquidation problem.