 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Gaussian Map for Vision-Language Navigation
May 26, 2026Vision-Language Navigation (VLN) requires an agent to navigate 3D environments following natural language instructions. During navigation, existing agents commonly encounter perceptual uncertainty, such as insufficient evidence for reliable grounding or ambiguity in interpreting spatial cues, yet they typically ignore such information when predicting actions. In this work, we explicitly model three forms of perceptual uncertainty (i.e., geometric, semantic, and appearance uncertainty) and integrate them into the agent's observation space to enable informed decision-making. Concretely, our agent first constructs a Semantic Gaussian Map (SGM), composed of differentiable 3D Gaussian primitives initialized from panoramic observations, that encodes both the geometric structure and semantic content of the environment. On top of SGM, geometric uncertainty is estimated through variational perturbations of Gaussian position and scale to assess structural reliability; semantic uncertainty is captured by perturbing Gaussian semantic attributes to reveal ambiguous interpretations; and appearance uncertainty is characterized by Fisher Information, which measures the sensitivity of rendered observations to Gaussian-level variations. These uncertainties are incorporated into SGM, extending it into a unified 3D Value Map, which grounds them as affordances and constraints that support reliable navigation. Comprehensive evaluations across multiple VLN benchmarks show the effectiveness of our agent.
PointForward: Feedforward Driving Reconstruction through Point-Aligned Representations
May 12, 2026High-fidelity reconstruction of driving scenes is crucial for autonomous driving. While recent feedforward 3D Gaussian Splatting (3DGS) methods enable fast reconstruction, their per-pixel Gaussian prediction paradigm often suffers from multi-view inconsistency and layering artifacts. Moreover, existing methods often model dynamic instances via dense flow prediction, which lacks explicit cross-view correspondence and instance-level consistency. In this paper, we propose PointForward, a feedforward driving reconstruction framework through point-aligned representations. Unlike pixel-aligned methods, we initialize sparse 3D queries in world space and aggregate multi-view image information via spatial-temporal fusion onto these queries, enforcing explicit cross-view consistency in a single feedforward pass. To handle scene dynamics, we introduce scene graphs that explicitly organize moving instances during reconstruction. By leveraging 3D bounding boxes, our method enables instance-level motion propagation and temporally consistent dynamic representations. Extensive experiments demonstrate that PointForward achieves state-of-the-art performance on large-scale driving benchmarks. The code will be available upon the publication of the paper.
Contact Matrix: Enhancing Dance Motion Synthesis with Precise Interaction Modeling
May 06, 2026Generating realistic reactive motions, in which one person reacts to the fixed motions of others, is challenging due to strict interaction constraints and a limited feasible solution space. This paper focuses on a typical scenario: duet dance, where high-quality data is scarce, motion patterns are complex, and the details of human interactions are both intricate and abundant. To tackle these challenges, we propose a novel two-stage framework. In the first stage, we introduce a motion VQ-VAE with separate body-part encoders and a joint decoder, enabling specialized codebooks to enhance representation capacity while dynamically modeling dependencies across body parts during decoding, thereby preventing inconsistencies in the generated motions. In the second stage, we propose a contact-aware diffusion model for reactive motion generation that jointly generates motion and a contact matrix between individuals, enabling explicit interaction modeling and providing guidance toward more precise and constrained interaction dynamics during sampling. Experiments show that our method outperforms Duolando with lower $\text{FID}_k$ (8.89 vs. 25.30) and $\text{FID}_{cd}$ (8.01 vs. 9.97), as well as a higher BED (0.4606 vs. 0.2858), indicating improved interaction fidelity and rhythmic synchronization.
Habitat-GS: A High-Fidelity Navigation Simulator with Dynamic Gaussian Splatting
Apr 14, 2026Training embodied AI agents depends critically on the visual fidelity of simulation environments and the ability to model dynamic humans. Current simulators rely on mesh-based rasterization with limited visual realism, and their support for dynamic human avatars, where available, is constrained to mesh representations, hindering agent generalization to human-populated real-world scenarios. We present Habitat-GS, a navigation-centric embodied AI simulator extended from Habitat-Sim that integrates 3D Gaussian Splatting scene rendering and drivable gaussian avatars while maintaining full compatibility with the Habitat ecosystem. Our system implements a 3DGS renderer for real-time photorealistic rendering and supports scalable 3DGS asset import from diverse sources. For dynamic human modeling, we introduce a gaussian avatar module that enables each avatar to simultaneously serve as a photorealistic visual entity and an effective navigation obstacle, allowing agents to learn human-aware behaviors in realistic settings. Experiments on point-goal navigation demonstrate that agents trained on 3DGS scenes achieve stronger cross-domain generalization, with mixed-domain training being the most effective strategy. Evaluations on avatar-aware navigation further confirm that gaussian avatars enable effective human-aware navigation. Finally, performance benchmarks validate the system's scalability across varying scene complexity and avatar counts.
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
Apr 09, 2026This paper addresses the task of large-scale 3D scene reconstruction from long video sequences. Recent feed-forward reconstruction models have shown promising results by directly regressing 3D geometry from RGB images without explicit 3D priors or geometric constraints. However, these methods often struggle to maintain reconstruction accuracy and consistency over long sequences due to limited memory capacity and the inability to effectively capture global contextual cues. In contrast, humans can naturally exploit the global understanding of the scene to inform local perception. Motivated by this, we propose a novel neural global context representation that efficiently compresses and retains long-range scene information, enabling the model to leverage extensive contextual cues for enhanced reconstruction accuracy and consistency. The context representation is realized through a set of lightweight neural sub-networks that are rapidly adapted during test time via self-supervised objectives, which substantially increases memory capacity without incurring significant computational overhead. The experiments on multiple large-scale benchmarks, including the KITTI Odometry~\cite{Geiger2012CVPR} and Oxford Spires~\cite{tao2025spires} datasets, demonstrate the effectiveness of our approach in handling ultra-large scenes, achieving leading pose accuracy and state-of-the-art 3D reconstruction accuracy while maintaining efficiency. Code is available at https://zju3dv.github.io/scal3r.
InfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Jan 06, 2026Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Jan 03, 2026We present UniSH, a unified, feed-forward framework for joint metric-scale 3D scene and human reconstruction. A key challenge in this domain is the scarcity of large-scale, annotated real-world data, forcing a reliance on synthetic datasets. This reliance introduces a significant sim-to-real domain gap, leading to poor generalization, low-fidelity human geometry, and poor alignment on in-the-wild videos. To address this, we propose an innovative training paradigm that effectively leverages unlabeled in-the-wild data. Our framework bridges strong, disparate priors from scene reconstruction and HMR, and is trained with two core components: (1) a robust distillation strategy to refine human surface details by distilling high-frequency details from an expert depth model, and (2) a two-stage supervision scheme, which first learns coarse localization on synthetic data, then fine-tunes on real data by directly optimizing the geometric correspondence between the SMPL mesh and the human point cloud. This approach enables our feed-forward model to jointly recover high-fidelity scene geometry, human point clouds, camera parameters, and coherent, metric-scale SMPL bodies, all in a single forward pass. Extensive experiments demonstrate that our model achieves state-of-the-art performance on human-centric scene reconstruction and delivers highly competitive results on global human motion estimation, comparing favorably against both optimization-based frameworks and HMR-only methods. Project page: https://murphylmf.github.io/UniSH/
Split4D: Decomposed 4D Scene Reconstruction Without Video Segmentation
Dec 28, 2025This paper addresses the problem of decomposed 4D scene reconstruction from multi-view videos. Recent methods achieve this by lifting video segmentation results to a 4D representation through differentiable rendering techniques. Therefore, they heavily rely on the quality of video segmentation maps, which are often unstable, leading to unreliable reconstruction results. To overcome this challenge, our key idea is to represent the decomposed 4D scene with the Freetime FeatureGS and design a streaming feature learning strategy to accurately recover it from per-image segmentation maps, eliminating the need for video segmentation. Freetime FeatureGS models the dynamic scene as a set of Gaussian primitives with learnable features and linear motion ability, allowing them to move to neighboring regions over time. We apply a contrastive loss to Freetime FeatureGS, forcing primitive features to be close or far apart based on whether their projections belong to the same instance in the 2D segmentation map. As our Gaussian primitives can move across time, it naturally extends the feature learning to the temporal dimension, achieving 4D segmentation. Furthermore, we sample observations for training in a temporally ordered manner, enabling the streaming propagation of features over time and effectively avoiding local minima during the optimization process. Experimental results on several datasets show that the reconstruction quality of our method outperforms recent methods by a large margin.
SpatialTree: How Spatial Abilities Branch Out in MLLMs
Dec 23, 2025Cognitive science suggests that spatial ability develops progressively-from perception to reasoning and interaction. Yet in multimodal LLMs (MLLMs), this hierarchy remains poorly understood, as most studies focus on a narrow set of tasks. We introduce SpatialTree, a cognitive-science-inspired hierarchy that organizes spatial abilities into four levels: low-level perception (L1), mental mapping (L2), simulation (L3), and agentic competence (L4). Based on this taxonomy, we construct the first capability-centric hierarchical benchmark, thoroughly evaluating mainstream MLLMs across 27 sub-abilities. The evaluation results reveal a clear structure: L1 skills are largely orthogonal, whereas higher-level skills are strongly correlated, indicating increasing interdependency. Through targeted supervised fine-tuning, we uncover a surprising transfer dynamic-negative transfer within L1, but strong cross-level transfer from low- to high-level abilities with notable synergy. Finally, we explore how to improve the entire hierarchy. We find that naive RL that encourages extensive "thinking" is unreliable: it helps complex reasoning but hurts intuitive perception. We propose a simple auto-think strategy that suppresses unnecessary deliberation, enabling RL to consistently improve performance across all levels. By building SpatialTree, we provide a proof-of-concept framework for understanding and systematically scaling spatial abilities in MLLMs.
StreamingTalker: Audio-driven 3D Facial Animation with Autoregressive Diffusion Model
Nov 19, 2025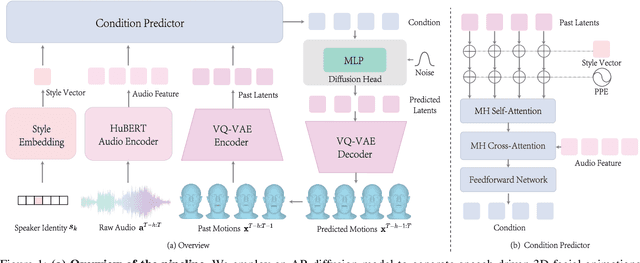
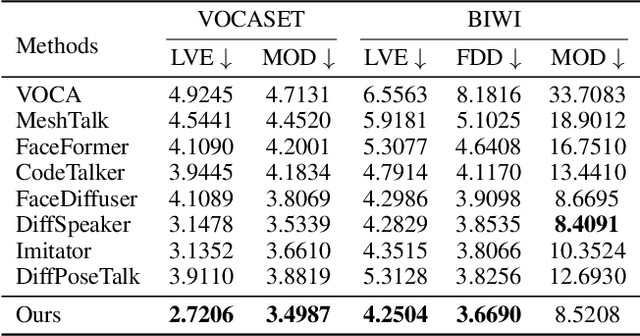
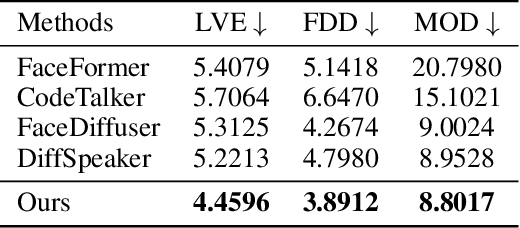
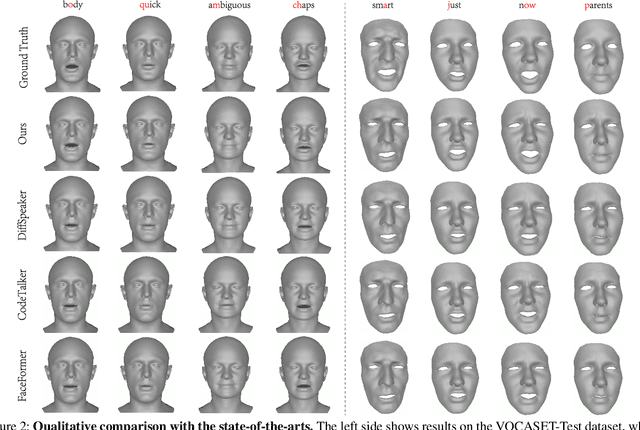
This paper focuses on the task of speech-driven 3D facial animation, which aims to generate realistic and synchronized facial motions driven by speech inputs. Recent methods have employed audio-conditioned diffusion models for 3D facial animation, achieving impressive results in generating expressive and natural animations. However, these methods process the whole audio sequences in a single pass, which poses two major challenges: they tend to perform poorly when handling audio sequences that exceed the training horizon and will suffer from significant latency when processing long audio inputs. To address these limitations, we propose a novel autoregressive diffusion model that processes input audio in a streaming manner. This design ensures flexibility with varying audio lengths and achieves low latency independent of audio duration. Specifically, we select a limited number of past frames as historical motion context and combine them with the audio input to create a dynamic condition. This condition guides the diffusion process to iteratively generate facial motion frames, enabling real-time synthesis with high-quality results. Additionally, we implemented a real-time interactive demo, highlighting the effectiveness and efficiency of our approach. We will release the code at https://zju3dv.github.io/StreamingTalker/.