 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMocap-2-to-3: Lifting 2D Diffusion-Based Pretrained Models for 3D Motion Capture
Mar 05, 2025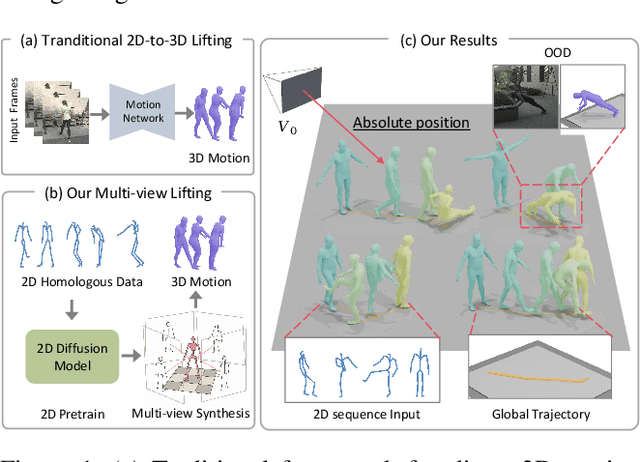
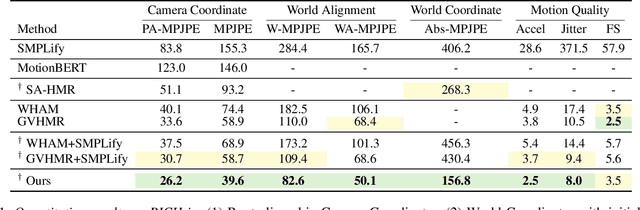
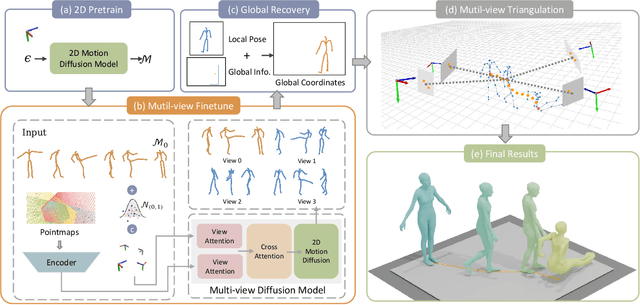
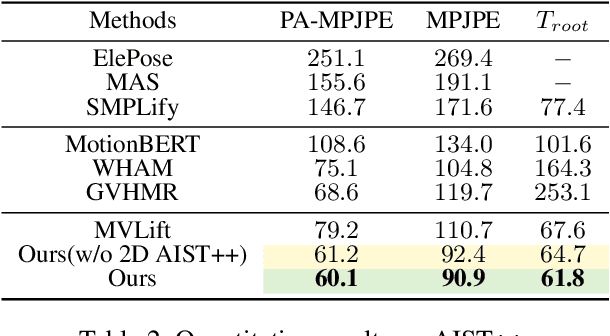
Recovering absolute poses in the world coordinate system from monocular views presents significant challenges. Two primary issues arise in this context. Firstly, existing methods rely on 3D motion data for training, which requires collection in limited environments. Acquiring such 3D labels for new actions in a timely manner is impractical, severely restricting the model's generalization capabilities. In contrast, 2D poses are far more accessible and easier to obtain. Secondly, estimating a person's absolute position in metric space from a single viewpoint is inherently more complex. To address these challenges, we introduce Mocap-2-to-3, a novel framework that decomposes intricate 3D motions into 2D poses, leveraging 2D data to enhance 3D motion reconstruction in diverse scenarios and accurately predict absolute positions in the world coordinate system. We initially pretrain a single-view diffusion model with extensive 2D data, followed by fine-tuning a multi-view diffusion model for view consistency using publicly available 3D data. This strategy facilitates the effective use of large-scale 2D data. Additionally, we propose an innovative human motion representation that decouples local actions from global movements and encodes geometric priors of the ground, ensuring the generative model learns accurate motion priors from 2D data. During inference, this allows for the gradual recovery of global movements, resulting in more plausible positioning. We evaluate our model's performance on real-world datasets, demonstrating superior accuracy in motion and absolute human positioning compared to state-of-the-art methods, along with enhanced generalization and scalability. Our code will be made publicly available.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Dec 17, 2024Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.