 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient, Validation-Free Intrinsic Quality Estimation for Large-Scale Face Recognition Datasets
May 28, 2026We propose Intrinsic Quality (IQ), a validation-free metric designed to estimate the inherent potential of face recognition (FR) datasets to produce high-performance models without the need for full-scale training. IQ integrates two components: (i) a Neighbor-Consistency Score that quantifies local identity label agreement via nearest neighbors, and (ii) Global Representation Subspace Complexity (Effective Rank, ER), which captures the underlying embedding geometry and dataset diversity. IQ allows for rapid evaluation using lightweight proxy models or data subsets, facilitating dataset diagnosis and curation prior to resource-intensive full-scale training. We describe an experimental protocol tailored to clean, noisy, and mixed-quality FR datasets, and outline evaluation methodologies to validate IQ's predictive power for downstream performance.
LLaVA-OneVision-2: Towards Next-Generation Perceptual Intelligence
May 25, 2026We introduce LLaVA-OneVision-2 (LLaVA-OV-2), the most capable vision-language model in the LLaVA-OneVision series to date, achieving superior performance across a broad range of multimodal benchmarks. The model builds on a native OneVision-Encoder and incorporates Windowed Attention for efficient local computation while maintaining native resolution. Its key advance is codec-stream tokenization: it treats compressed video as a continuous bit-cost stream, where bit-cost dynamics determine adaptive temporal groups, and motion-residual cues select salient spatial evidence into compact visual canvases. This allocation concentrates a limited token budget on event-bearing content, enabling more stable long-video token compression than fixed groups of pictures. A shared 3D RoPE further places codec canvases, sampled frames, and images in a unified spatiotemporal coordinate system. Furthermore, we build the LLaVA-OV-2 data and training stack around large-scale open supervision: approximately 8M re-captioned video samples for pretraining, a 4M-sample spatial corpus for fine-tuning. We also introduce JumpScore, a temporal-localization benchmark targeting fine-grained grounding in high-frequency, densely repeated motion, a regime underrepresented by existing video evaluations. A standout capability of LLaVA-OV-2 is its unified perception across video understanding, temporal grounding, spatial grounding, and manipulation-trace reasoning. On JumpScore, LLaVA-OneVision-2-8B reaches 74.9 JumpScore mAP, surpassing Qwen3-VL-8B (30.1) by +44.8 points; under matched visual-token budgets on the same benchmark, codec-stream inputs improve temporal grounding over frame sampling by +9.7 points. Across standard benchmarks, LLaVA-OneVision-2-8B further outperforms Qwen3-VL-8B by +4.3 average points on video tasks, +5.3 on spatial tasks, and +15.6 average J&F on tracking tasks.
UniDoc-RL: Coarse-to-Fine Visual RAG with Hierarchical Actions and Dense Rewards
Apr 16, 2026Retrieval-Augmented Generation (RAG) extends Large Vision-Language Models (LVLMs) with external visual knowledge. However, existing visual RAG systems typically rely on generic retrieval signals that overlook the fine-grained visual semantics essential for complex reasoning. To address this limitation, we propose UniDoc-RL, a unified reinforcement learning framework in which an LVLM agent jointly performs retrieval, reranking, active visual perception, and reasoning. UniDoc-RL formulates visual information acquisition as a sequential decision-making problem with a hierarchical action space. Specifically, it progressively refines visual evidence from coarse-grained document retrieval to fine-grained image selection and active region cropping, allowing the model to suppress irrelevant content and attend to information-dense regions. For effective end-to-end training, we introduce a dense multi-reward scheme that provides task-aware supervision for each action. Based on Group Relative Policy Optimization (GRPO), UniDoc-RL aligns agent behavior with multiple objectives without relying on a separate value network. To support this training paradigm, we curate a comprehensive dataset of high-quality reasoning trajectories with fine-grained action annotations. Experiments on three benchmarks demonstrate that UniDoc-RL consistently surpasses state-of-the-art baselines, yielding up to 17.7% gains over prior RL-based methods.
OneVision-Encoder: Codec-Aligned Sparsity as a Foundational Principle for Multimodal Intelligence
Feb 09, 2026Hypothesis. Artificial general intelligence is, at its core, a compression problem. Effective compression demands resonance: deep learning scales best when its architecture aligns with the fundamental structure of the data. These are the fundamental principles. Yet, modern vision architectures have strayed from these truths: visual signals are highly redundant, while discriminative information, the surprise, is sparse. Current models process dense pixel grids uniformly, wasting vast compute on static background rather than focusing on the predictive residuals that define motion and meaning. We argue that to solve visual understanding, we must align our architectures with the information-theoretic principles of video, i.e., Codecs. Method. OneVision-Encoder encodes video by compressing predictive visual structure into semantic meaning. By adopting Codec Patchification, OV-Encoder abandons uniform computation to focus exclusively on the 3.1%-25% of regions rich in signal entropy. To unify spatial and temporal reasoning under irregular token layouts, OneVision-Encoder employs a shared 3D RoPE and is trained with a large-scale cluster discrimination objective over more than one million semantic concepts, jointly capturing object permanence and motion dynamics. Evidence. The results validate our core hypothesis: efficiency and accuracy are not a trade-off; they are positively correlated. When integrated into LLM, it consistently outperforms strong vision backbones such as Qwen3-ViT and SigLIP2 across 16 image, video, and document understanding benchmarks, despite using substantially fewer visual tokens and pretraining data. Notably, on video understanding tasks, OV-Encoder achieves an average improvement of 4.1% over Qwen3-ViT. Codec-aligned, patch-level sparsity is a foundational principle, enabling OV-Encoder as a scalable engine for next-generation visual generalists.
DanQing: An Up-to-Date Large-Scale Chinese Vision-Language Pre-training Dataset
Jan 15, 2026Vision-Language Pre-training (VLP) models demonstrate strong performance across various downstream tasks by learning from large-scale image-text pairs through contrastive pretraining. The release of extensive English image-text datasets (e.g., COYO-700M and LAION-400M) has enabled widespread adoption of models such as CLIP and SigLIP in tasks including cross-modal retrieval and image captioning. However, the advancement of Chinese vision-language pretraining has substantially lagged behind, due to the scarcity of high-quality Chinese image-text data. To address this gap, we develop a comprehensive pipeline for constructing a high-quality Chinese cross-modal dataset. As a result, we propose DanQing, which contains 100 million image-text pairs collected from Common Crawl. Different from existing datasets, DanQing is curated through a more rigorous selection process, yielding superior data quality. Moreover, DanQing is primarily built from 2024-2025 web data, enabling models to better capture evolving semantic trends and thus offering greater practical utility. We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model. Experimental results show that DanQing consistently achieves superior performance across a range of Chinese downstream tasks, including zero-shot classification, cross-modal retrieval, and LMM-based evaluations. To facilitate further research in Chinese vision-language pre-training, we will open-source the DanQing dataset under the Creative Common CC-BY 4.0 license.
ProCLIP: Progressive Vision-Language Alignment via LLM-based Embedder
Oct 22, 2025The original CLIP text encoder is limited by a maximum input length of 77 tokens, which hampers its ability to effectively process long texts and perform fine-grained semantic understanding. In addition, the CLIP text encoder lacks support for multilingual inputs. All these limitations significantly restrict its applicability across a broader range of tasks. Recent studies have attempted to replace the CLIP text encoder with an LLM-based embedder to enhance its ability in processing long texts, multilingual understanding, and fine-grained semantic comprehension. However, because the representation spaces of LLMs and the vision-language space of CLIP are pretrained independently without alignment priors, direct alignment using contrastive learning can disrupt the intrinsic vision-language alignment in the CLIP image encoder, leading to an underutilization of the knowledge acquired during pre-training. To address this challenge, we propose ProCLIP, a curriculum learning-based progressive vision-language alignment framework to effectively align the CLIP image encoder with an LLM-based embedder. Specifically, ProCLIP first distills knowledge from CLIP's text encoder into the LLM-based embedder to leverage CLIP's rich pretrained knowledge while establishing initial alignment between the LLM embedder and CLIP image encoder. Subsequently, ProCLIP further aligns the CLIP image encoder with the LLM-based embedder through image-text contrastive tuning, employing self-distillation regularization to avoid overfitting. To achieve a more effective alignment, instance semantic alignment loss and embedding structure alignment loss are employed during representation inheritance and contrastive tuning. The Code is available at https://github.com/VisionXLab/ProCLIP.
UniVerse: Unleashing the Scene Prior of Video Diffusion Models for Robust Radiance Field Reconstruction
Oct 02, 2025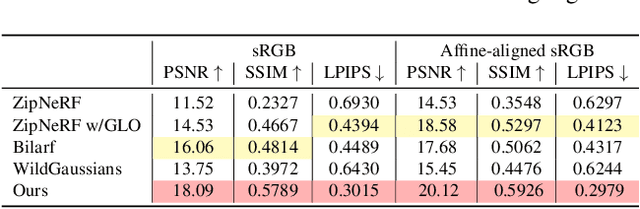
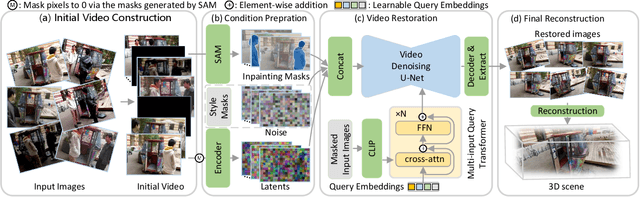
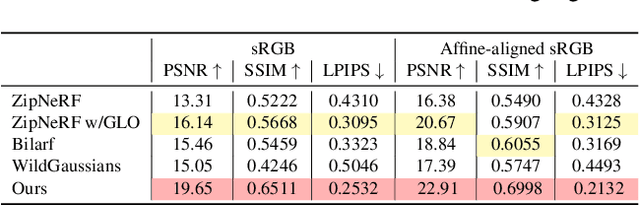

This paper tackles the challenge of robust reconstruction, i.e., the task of reconstructing a 3D scene from a set of inconsistent multi-view images. Some recent works have attempted to simultaneously remove image inconsistencies and perform reconstruction by integrating image degradation modeling into neural 3D scene representations.However, these methods rely heavily on dense observations for robustly optimizing model parameters.To address this issue, we propose to decouple robust reconstruction into two subtasks: restoration and reconstruction, which naturally simplifies the optimization process.To this end, we introduce UniVerse, a unified framework for robust reconstruction based on a video diffusion model. Specifically, UniVerse first converts inconsistent images into initial videos, then uses a specially designed video diffusion model to restore them into consistent images, and finally reconstructs the 3D scenes from these restored images.Compared with case-by-case per-view degradation modeling, the diffusion model learns a general scene prior from large-scale data, making it applicable to diverse image inconsistencies.Extensive experiments on both synthetic and real-world datasets demonstrate the strong generalization capability and superior performance of our method in robust reconstruction. Moreover, UniVerse can control the style of the reconstructed 3D scene. Project page: https://jin-cao-tma.github.io/UniVerse.github.io/
Gradient-Attention Guided Dual-Masking Synergetic Framework for Robust Text-based Person Retrieval
Sep 11, 2025Although Contrastive Language-Image Pre-training (CLIP) exhibits strong performance across diverse vision tasks, its application to person representation learning faces two critical challenges: (i) the scarcity of large-scale annotated vision-language data focused on person-centric images, and (ii) the inherent limitations of global contrastive learning, which struggles to maintain discriminative local features crucial for fine-grained matching while remaining vulnerable to noisy text tokens. This work advances CLIP for person representation learning through synergistic improvements in data curation and model architecture. First, we develop a noise-resistant data construction pipeline that leverages the in-context learning capabilities of MLLMs to automatically filter and caption web-sourced images. This yields WebPerson, a large-scale dataset of 5M high-quality person-centric image-text pairs. Second, we introduce the GA-DMS (Gradient-Attention Guided Dual-Masking Synergetic) framework, which improves cross-modal alignment by adaptively masking noisy textual tokens based on the gradient-attention similarity score. Additionally, we incorporate masked token prediction objectives that compel the model to predict informative text tokens, enhancing fine-grained semantic representation learning. Extensive experiments show that GA-DMS achieves state-of-the-art performance across multiple benchmarks.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Apr 24, 2025The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLM\'s language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.