 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Oct 18, 2024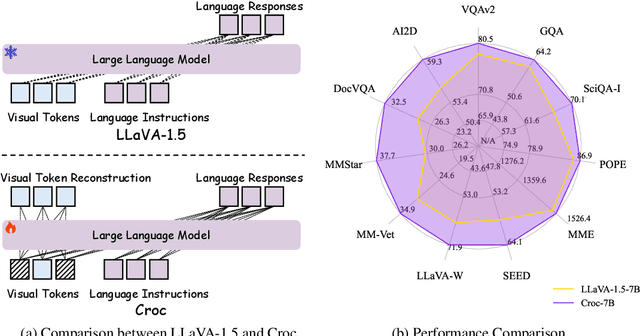
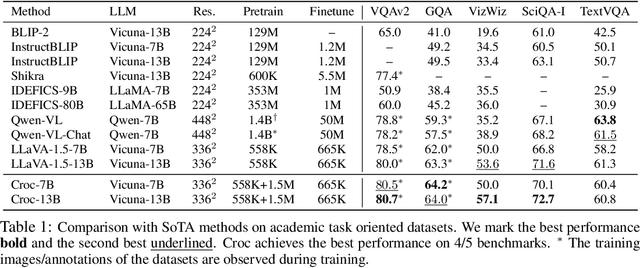
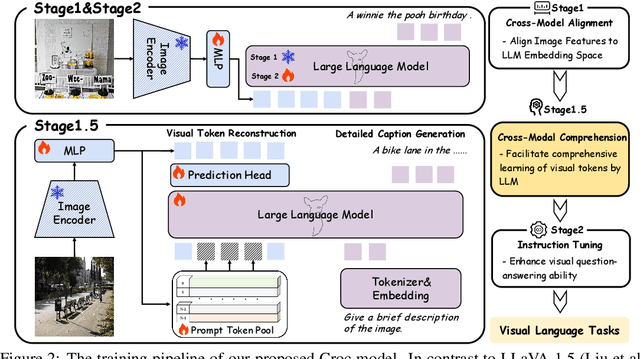
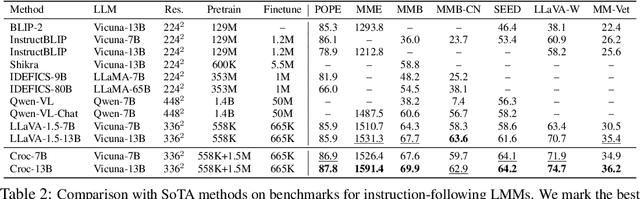
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a "foreign language" for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling
Aug 02, 2024



VAR is a new generation paradigm that employs 'next-scale prediction' as opposed to 'next-token prediction'. This innovative transformation enables auto-regressive (AR) transformers to rapidly learn visual distributions and achieve robust generalization. However, the original VAR model is constrained to class-conditioned synthesis, relying solely on textual captions for guidance. In this paper, we introduce VAR-CLIP, a novel text-to-image model that integrates Visual Auto-Regressive techniques with the capabilities of CLIP. The VAR-CLIP framework encodes captions into text embeddings, which are then utilized as textual conditions for image generation. To facilitate training on extensive datasets, such as ImageNet, we have constructed a substantial image-text dataset leveraging BLIP2. Furthermore, we delve into the significance of word positioning within CLIP for the purpose of caption guidance. Extensive experiments confirm VAR-CLIP's proficiency in generating fantasy images with high fidelity, textual congruence, and aesthetic excellence. Our project page are https://github.com/daixiangzi/VAR-CLIP
Point-Voxel Adaptive Feature Abstraction for Robust Point Cloud Classification
Oct 30, 2022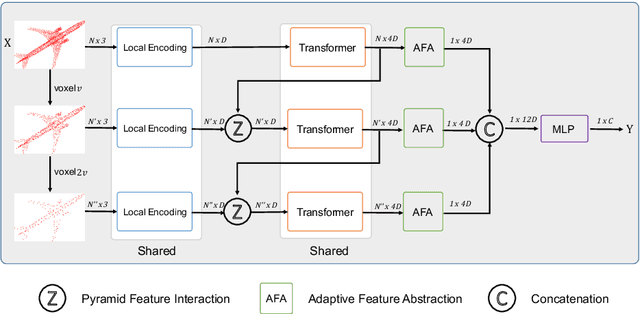
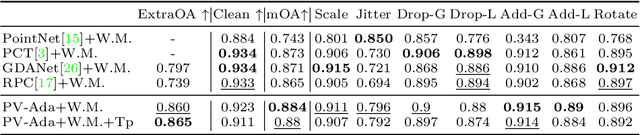

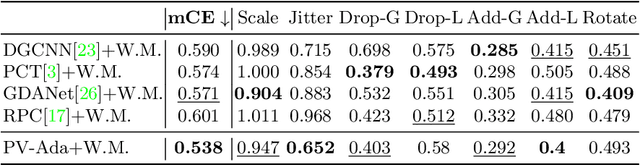
Great progress has been made in point cloud classification with learning-based methods. However, complex scene and sensor inaccuracy in real-world application make point cloud data suffer from corruptions, such as occlusion, noise and outliers. In this work, we propose Point-Voxel based Adaptive (PV-Ada) feature abstraction for robust point cloud classification under various corruptions. Specifically, the proposed framework iteratively voxelize the point cloud and extract point-voxel feature with shared local encoding and Transformer. Then, adaptive max-pooling is proposed to robustly aggregate the point cloud feature for classification. Experiments on ModelNet-C dataset demonstrate that PV-Ada outperforms the state-of-the-art methods. In particular, we rank the $2^{nd}$ place in ModelNet-C classification track of PointCloud-C Challenge 2022, with Overall Accuracy (OA) being 0.865. Code will be available at https://github.com/zhulf0804/PV-Ada.
Point Cloud Registration using Representative Overlapping Points
Jul 06, 2021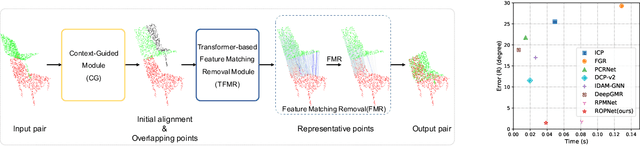
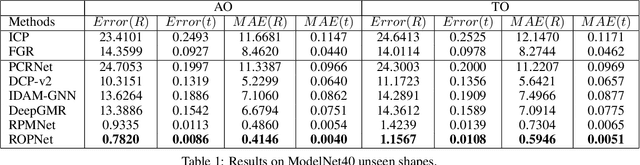
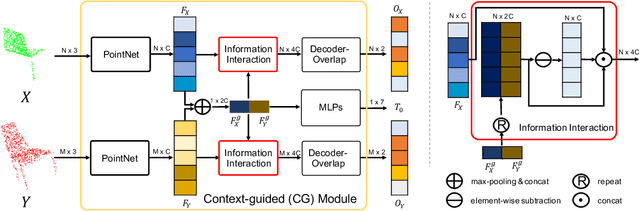
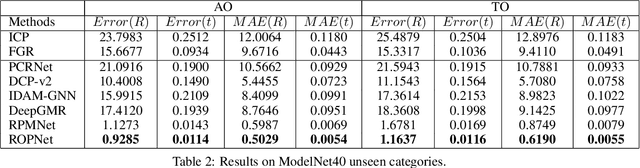
3D point cloud registration is a fundamental task in robotics and computer vision. Recently, many learning-based point cloud registration methods based on correspondences have emerged. However, these methods heavily rely on such correspondences and meet great challenges with partial overlap. In this paper, we propose ROPNet, a new deep learning model using Representative Overlapping Points with discriminative features for registration that transforms partial-to-partial registration into partial-to-complete registration. Specifically, we propose a context-guided module which uses an encoder to extract global features for predicting point overlap score. To better find representative overlapping points, we use the extracted global features for coarse alignment. Then, we introduce a Transformer to enrich point features and remove non-representative points based on point overlap score and feature matching. A similarity matrix is built in a partial-to-complete mode, and finally, weighted SVD is adopted to estimate a transformation matrix. Extensive experiments over ModelNet40 using noisy and partially overlapping point clouds show that the proposed method outperforms traditional and learning-based methods, achieving state-of-the-art performance. The code is available at https://github.com/zhulf0804/ROPNet.