 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCroc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Oct 18, 2024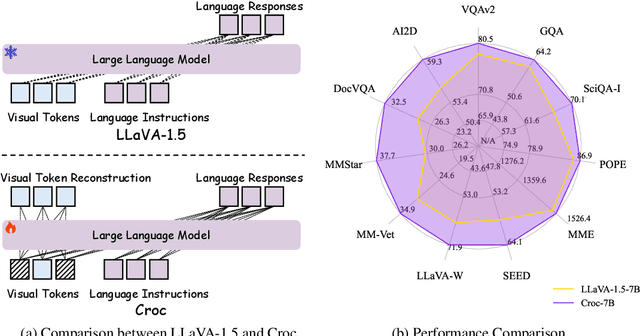
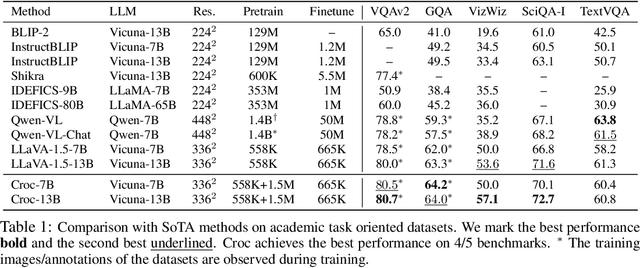
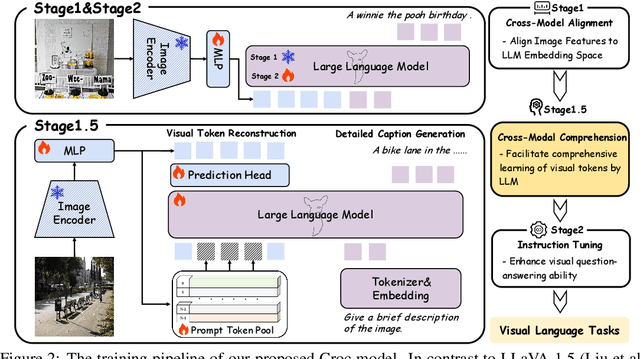
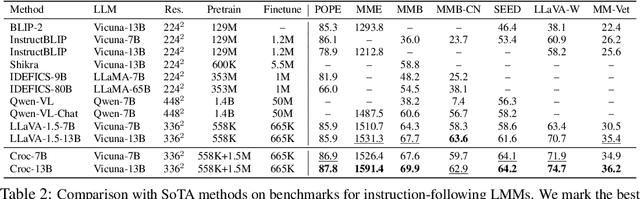
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a "foreign language" for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Aug 18, 2024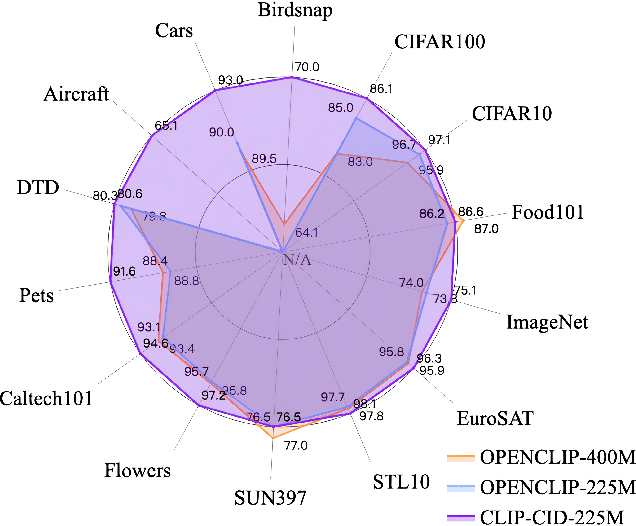
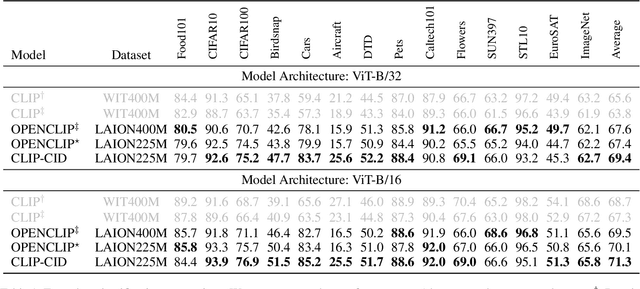
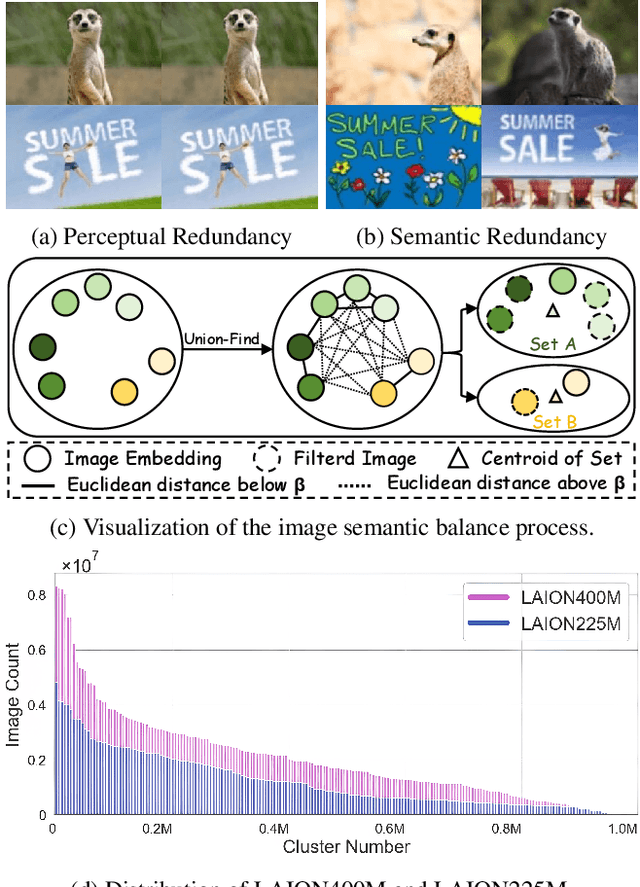
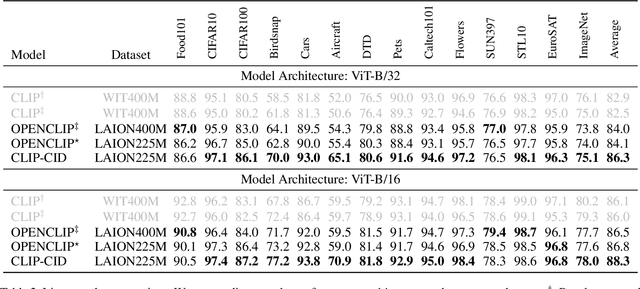
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling
Aug 02, 2024



VAR is a new generation paradigm that employs 'next-scale prediction' as opposed to 'next-token prediction'. This innovative transformation enables auto-regressive (AR) transformers to rapidly learn visual distributions and achieve robust generalization. However, the original VAR model is constrained to class-conditioned synthesis, relying solely on textual captions for guidance. In this paper, we introduce VAR-CLIP, a novel text-to-image model that integrates Visual Auto-Regressive techniques with the capabilities of CLIP. The VAR-CLIP framework encodes captions into text embeddings, which are then utilized as textual conditions for image generation. To facilitate training on extensive datasets, such as ImageNet, we have constructed a substantial image-text dataset leveraging BLIP2. Furthermore, we delve into the significance of word positioning within CLIP for the purpose of caption guidance. Extensive experiments confirm VAR-CLIP's proficiency in generating fantasy images with high fidelity, textual congruence, and aesthetic excellence. Our project page are https://github.com/daixiangzi/VAR-CLIP
Multi-label Cluster Discrimination for Visual Representation Learning
Jul 24, 2024



Contrastive Language Image Pre-training (CLIP) has recently demonstrated success across various tasks due to superior feature representation empowered by image-text contrastive learning. However, the instance discrimination method used by CLIP can hardly encode the semantic structure of training data. To handle this limitation, cluster discrimination has been proposed through iterative cluster assignment and classification. Nevertheless, most cluster discrimination approaches only define a single pseudo-label for each image, neglecting multi-label signals in the image. In this paper, we propose a novel Multi-Label Cluster Discrimination method named MLCD to enhance representation learning. In the clustering step, we first cluster the large-scale LAION-400M dataset into one million centers based on off-the-shelf embedding features. Considering that natural images frequently contain multiple visual objects or attributes, we select the multiple closest centers as auxiliary class labels. In the discrimination step, we design a novel multi-label classification loss, which elegantly separates losses from positive classes and negative classes, and alleviates ambiguity on decision boundary. We validate the proposed multi-label cluster discrimination method with experiments on different scales of models and pre-training datasets. Experimental results show that our method achieves state-of-the-art performance on multiple downstream tasks including linear probe, zero-shot classification, and image-text retrieval.
High-Fidelity Facial Albedo Estimation via Texture Quantization
Jun 19, 2024



Recent 3D face reconstruction methods have made significant progress in shape estimation, but high-fidelity facial albedo reconstruction remains challenging. Existing methods depend on expensive light-stage captured data to learn facial albedo maps. However, a lack of diversity in subjects limits their ability to recover high-fidelity results. In this paper, we present a novel facial albedo reconstruction model, HiFiAlbedo, which recovers the albedo map directly from a single image without the need for captured albedo data. Our key insight is that the albedo map is the illumination invariant texture map, which enables us to use inexpensive texture data to derive an albedo estimation by eliminating illumination. To achieve this, we first collect large-scale ultra-high-resolution facial images and train a high-fidelity facial texture codebook. By using the FFHQ dataset and limited UV textures, we then fine-tune the encoder for texture reconstruction from the input image with adversarial supervision in both image and UV space. Finally, we train a cross-attention module and utilize group identity loss to learn the adaptation from facial texture to the albedo domain. Extensive experimentation has demonstrated that our method exhibits excellent generalizability and is capable of achieving high-fidelity results for in-the-wild facial albedo recovery. Our code, pre-trained weights, and training data will be made publicly available at https://hifialbedo.github.io/.