 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARoL: Context-aware Adaptation for Robot Learning
Jun 08, 2025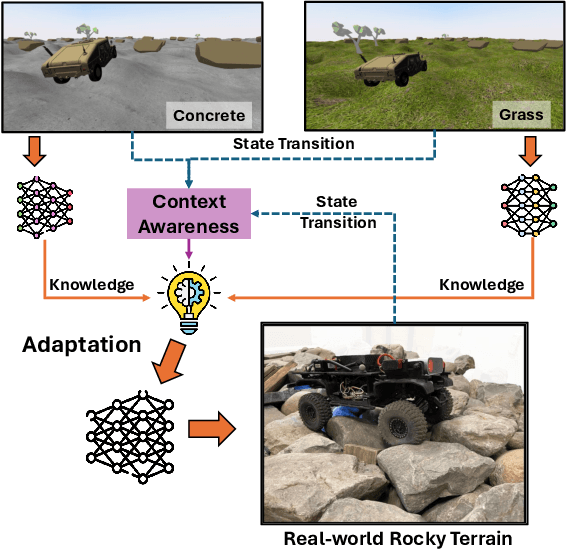
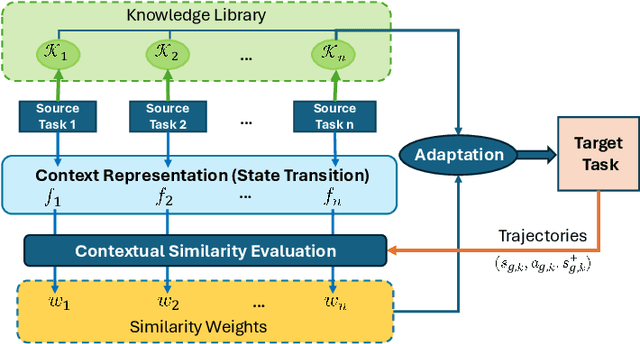
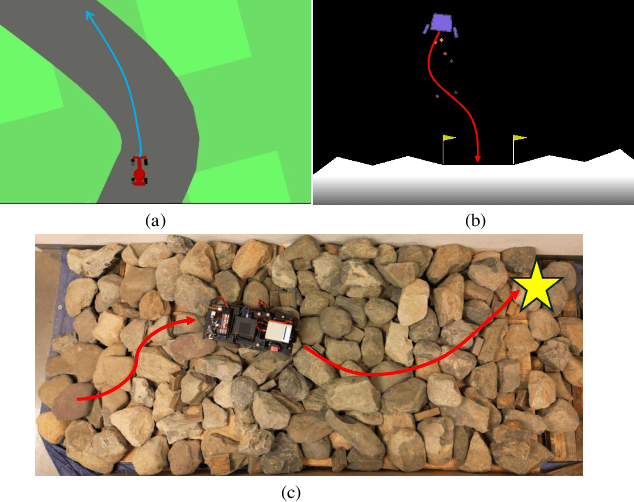
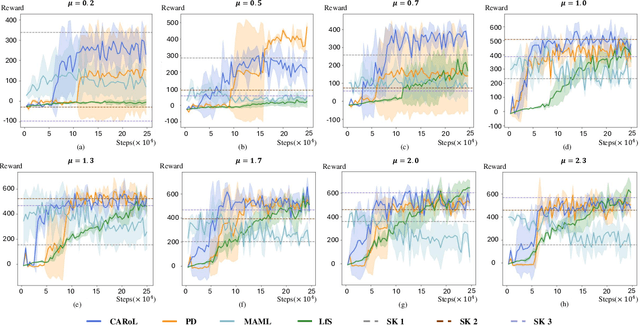
Using Reinforcement Learning (RL) to learn new robotic tasks from scratch is often inefficient. Leveraging prior knowledge has the potential to significantly enhance learning efficiency, which, however, raises two critical challenges: how to determine the relevancy of existing knowledge and how to adaptively integrate them into learning a new task. In this paper, we propose Context-aware Adaptation for Robot Learning (CARoL), a novel framework to efficiently learn a similar but distinct new task from prior knowledge. CARoL incorporates context awareness by analyzing state transitions in system dynamics to identify similarities between the new task and prior knowledge. It then utilizes these identified similarities to prioritize and adapt specific knowledge pieces for the new task. Additionally, CARoL has a broad applicability spanning policy-based, value-based, and actor-critic RL algorithms. We validate the efficiency and generalizability of CARoL on both simulated robotic platforms and physical ground vehicles. The simulations include CarRacing and LunarLander environments, where CARoL demonstrates faster convergence and higher rewards when learning policies for new tasks. In real-world experiments, we show that CARoL enables a ground vehicle to quickly and efficiently adapt policies learned in simulation to smoothly traverse real-world off-road terrain.
Mocap-2-to-3: Lifting 2D Diffusion-Based Pretrained Models for 3D Motion Capture
Mar 05, 2025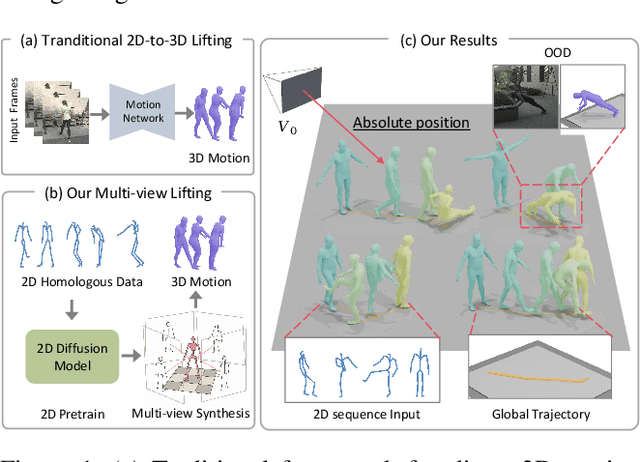
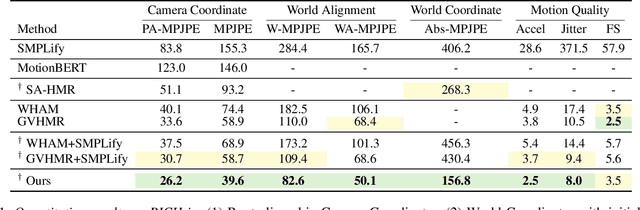
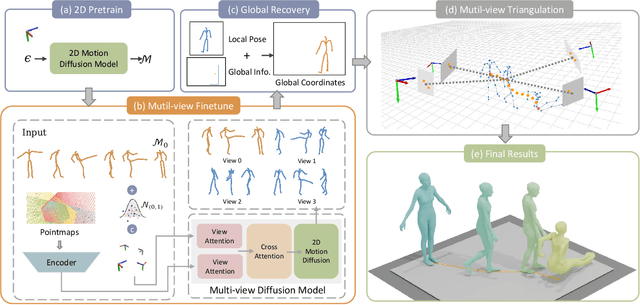
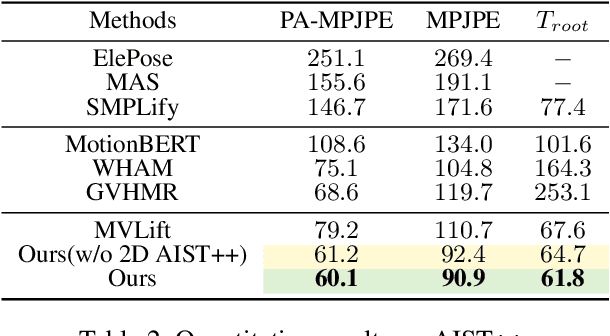
Recovering absolute poses in the world coordinate system from monocular views presents significant challenges. Two primary issues arise in this context. Firstly, existing methods rely on 3D motion data for training, which requires collection in limited environments. Acquiring such 3D labels for new actions in a timely manner is impractical, severely restricting the model's generalization capabilities. In contrast, 2D poses are far more accessible and easier to obtain. Secondly, estimating a person's absolute position in metric space from a single viewpoint is inherently more complex. To address these challenges, we introduce Mocap-2-to-3, a novel framework that decomposes intricate 3D motions into 2D poses, leveraging 2D data to enhance 3D motion reconstruction in diverse scenarios and accurately predict absolute positions in the world coordinate system. We initially pretrain a single-view diffusion model with extensive 2D data, followed by fine-tuning a multi-view diffusion model for view consistency using publicly available 3D data. This strategy facilitates the effective use of large-scale 2D data. Additionally, we propose an innovative human motion representation that decouples local actions from global movements and encodes geometric priors of the ground, ensuring the generative model learns accurate motion priors from 2D data. During inference, this allows for the gradual recovery of global movements, resulting in more plausible positioning. We evaluate our model's performance on real-world datasets, demonstrating superior accuracy in motion and absolute human positioning compared to state-of-the-art methods, along with enhanced generalization and scalability. Our code will be made publicly available.
Motion-2-to-3: Leveraging 2D Motion Data to Boost 3D Motion Generation
Dec 17, 2024Text-driven human motion synthesis is capturing significant attention for its ability to effortlessly generate intricate movements from abstract text cues, showcasing its potential for revolutionizing motion design not only in film narratives but also in virtual reality experiences and computer game development. Existing methods often rely on 3D motion capture data, which require special setups resulting in higher costs for data acquisition, ultimately limiting the diversity and scope of human motion. In contrast, 2D human videos offer a vast and accessible source of motion data, covering a wider range of styles and activities. In this paper, we explore leveraging 2D human motion extracted from videos as an alternative data source to improve text-driven 3D motion generation. Our approach introduces a novel framework that disentangles local joint motion from global movements, enabling efficient learning of local motion priors from 2D data. We first train a single-view 2D local motion generator on a large dataset of text-motion pairs. To enhance this model to synthesize 3D motion, we fine-tune the generator with 3D data, transforming it into a multi-view generator that predicts view-consistent local joint motion and root dynamics. Experiments on the HumanML3D dataset and novel text prompts demonstrate that our method efficiently utilizes 2D data, supporting realistic 3D human motion generation and broadening the range of motion types it supports. Our code will be made publicly available at https://zju3dv.github.io/Motion-2-to-3/.
Deconfounding Time Series Forecasting
Oct 27, 2024



Time series forecasting is a critical task in various domains, where accurate predictions can drive informed decision-making. Traditional forecasting methods often rely on current observations of variables to predict future outcomes, typically overlooking the influence of latent confounders, unobserved variables that simultaneously affect both the predictors and the target outcomes. This oversight can introduce bias and degrade the performance of predictive models. In this study, we address this challenge by proposing an enhanced forecasting approach that incorporates representations of latent confounders derived from historical data. By integrating these confounders into the predictive process, our method aims to improve the accuracy and robustness of time series forecasts. The proposed approach is demonstrated through its application to climate science data, showing significant improvements over traditional methods that do not account for confounders.
World-Grounded Human Motion Recovery via Gravity-View Coordinates
Sep 10, 2024



We present a novel method for recovering world-grounded human motion from monocular video. The main challenge lies in the ambiguity of defining the world coordinate system, which varies between sequences. Previous approaches attempt to alleviate this issue by predicting relative motion in an autoregressive manner, but are prone to accumulating errors. Instead, we propose estimating human poses in a novel Gravity-View (GV) coordinate system, which is defined by the world gravity and the camera view direction. The proposed GV system is naturally gravity-aligned and uniquely defined for each video frame, largely reducing the ambiguity of learning image-pose mapping. The estimated poses can be transformed back to the world coordinate system using camera rotations, forming a global motion sequence. Additionally, the per-frame estimation avoids error accumulation in the autoregressive methods. Experiments on in-the-wild benchmarks demonstrate that our method recovers more realistic motion in both the camera space and world-grounded settings, outperforming state-of-the-art methods in both accuracy and speed. The code is available at https://zju3dv.github.io/gvhmr/.
Learning Coordinated Maneuver in Adversarial Environments
Jul 12, 2024



This paper aims to solve the coordination of a team of robots traversing a route in the presence of adversaries with random positions. Our goal is to minimize the overall cost of the team, which is determined by (i) the accumulated risk when robots stay in adversary-impacted zones and (ii) the mission completion time. During traversal, robots can reduce their speed and act as a `guard' (the slower, the better), which will decrease the risks certain adversary incurs. This leads to a trade-off between the robots' guarding behaviors and their travel speeds. The formulated problem is highly non-convex and cannot be efficiently solved by existing algorithms. Our approach includes a theoretical analysis of the robots' behaviors for the single-adversary case. As the scale of the problem expands, solving the optimal solution using optimization approaches is challenging, therefore, we employ reinforcement learning techniques by developing new encoding and policy-generating methods. Simulations demonstrate that our learning methods can efficiently produce team coordination behaviors. We discuss the reasoning behind these behaviors and explain why they reduce the overall team cost.
Bi-CL: A Reinforcement Learning Framework for Robots Coordination Through Bi-level Optimization
Apr 23, 2024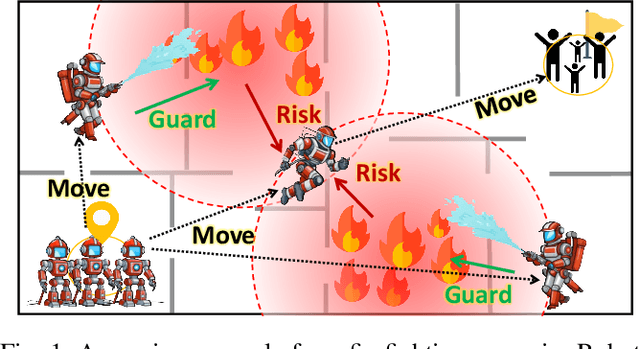



In multi-robot systems, achieving coordinated missions remains a significant challenge due to the coupled nature of coordination behaviors and the lack of global information for individual robots. To mitigate these challenges, this paper introduces a novel approach, Bi-level Coordination Learning (Bi-CL), that leverages a bi-level optimization structure within a centralized training and decentralized execution paradigm. Our bi-level reformulation decomposes the original problem into a reinforcement learning level with reduced action space, and an imitation learning level that gains demonstrations from a global optimizer. Both levels contribute to improved learning efficiency and scalability. We note that robots' incomplete information leads to mismatches between the two levels of learning models. To address this, Bi-CL further integrates an alignment penalty mechanism, aiming to minimize the discrepancy between the two levels without degrading their training efficiency. We introduce a running example to conceptualize the problem formulation and apply Bi-CL to two variations of this example: route-based and graph-based scenarios. Simulation results demonstrate that Bi-CL can learn more efficiently and achieve comparable performance with traditional multi-agent reinforcement learning baselines for multi-robot coordination.
Scaling Team Coordination on Graphs with Reinforcement Learning
Mar 09, 2024This paper studies Reinforcement Learning (RL) techniques to enable team coordination behaviors in graph environments with support actions among teammates to reduce the costs of traversing certain risky edges in a centralized manner. While classical approaches can solve this non-standard multi-agent path planning problem by converting the original Environment Graph (EG) into a Joint State Graph (JSG) to implicitly incorporate the support actions, those methods do not scale well to large graphs and teams. To address this curse of dimensionality, we propose to use RL to enable agents to learn such graph traversal and teammate supporting behaviors in a data-driven manner. Specifically, through a new formulation of the team coordination on graphs with risky edges problem into Markov Decision Processes (MDPs) with a novel state and action space, we investigate how RL can solve it in two paradigms: First, we use RL for a team of agents to learn how to coordinate and reach the goal with minimal cost on a single EG. We show that RL efficiently solves problems with up to 20/4 or 25/3 nodes/agents, using a fraction of the time needed for JSG to solve such complex problems; Second, we learn a general RL policy for any $N$-node EGs to produce efficient supporting behaviors. We present extensive experiments and compare our RL approaches against their classical counterparts.