 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Agent Coordination via Dynamic Joint-State Graph Construction
Sep 08, 2025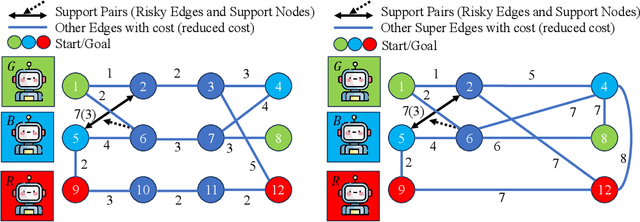

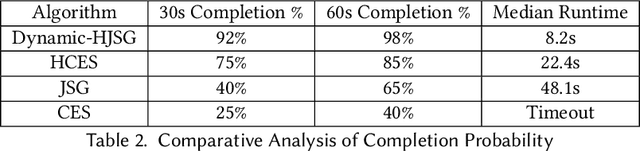
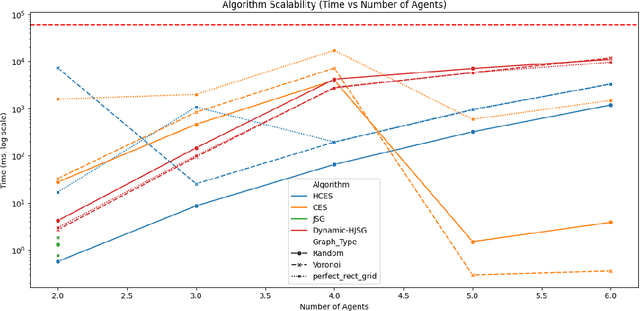
Multi-agent pathfinding (MAPF) traditionally focuses on collision avoidance, but many real-world applications require active coordination between agents to improve team performance. This paper introduces Team Coordination on Graphs with Risky Edges (TCGRE), where agents collaborate to reduce traversal costs on high-risk edges via support from teammates. We reformulate TCGRE as a 3D matching problem-mapping robot pairs, support pairs, and time steps-and rigorously prove its NP-hardness via reduction from Minimum 3D Matching. To address this complexity, (in the conference version) we proposed efficient decomposition methods, reducing the problem to tractable subproblems: Joint-State Graph (JSG): Encodes coordination as a single-agent shortest-path problem. Coordination-Exhaustive Search (CES): Optimizes support assignments via exhaustive pairing. Receding-Horizon Optimistic Cooperative A* (RHOCA*): Balances optimality and scalability via horizon-limited planning. Further in this extension, we introduce a dynamic graph construction method (Dynamic-HJSG), leveraging agent homogeneity to prune redundant states and reduce computational overhead by constructing the joint-state graph dynamically. Theoretical analysis shows Dynamic-HJSG preserves optimality while lowering complexity from exponential to polynomial in key cases. Empirical results validate scalability for large teams and graphs, with HJSG outperforming baselines greatly in runtime in different sizes and types of graphs. This work bridges combinatorial optimization and multi-agent planning, offering a principled framework for collaborative pathfinding with provable guarantees, and the key idea of the solution can be widely extended to many other collaborative optimization problems, such as MAPF.
MedBLIP: Fine-tuning BLIP for Medical Image Captioning
May 20, 2025



Medical image captioning is a challenging task that requires generating clinically accurate and semantically meaningful descriptions of radiology images. While recent vision-language models (VLMs) such as BLIP, BLIP2, Gemini and ViT-GPT2 show strong performance on natural image datasets, they often produce generic or imprecise captions when applied to specialized medical domains. In this project, we explore the effectiveness of fine-tuning the BLIP model on the ROCO dataset for improved radiology captioning. We compare the fine-tuned BLIP against its zero-shot version, BLIP-2 base, BLIP-2 Instruct and a ViT-GPT2 transformer baseline. Our results demonstrate that domain-specific fine-tuning on BLIP significantly improves performance across both quantitative and qualitative evaluation metrics. We also visualize decoder cross-attention maps to assess interpretability and conduct an ablation study to evaluate the contributions of encoder-only and decoder-only fine-tuning. Our findings highlight the importance of targeted adaptation for medical applications and suggest that decoder-only fine-tuning (encoder-frozen) offers a strong performance baseline with 5% lower training time than full fine-tuning, while full model fine-tuning still yields the best results overall.
Heterogeneous Team Coordination on Partially Observable Graphs with Realistic Communication
Oct 29, 2024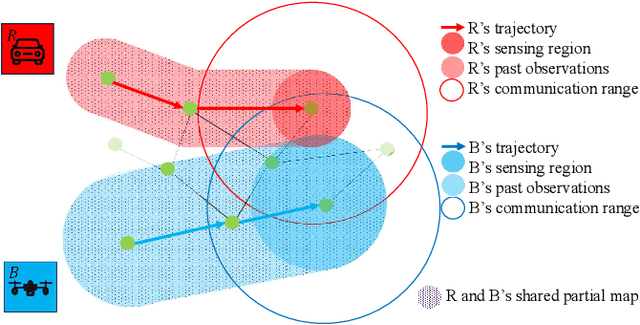

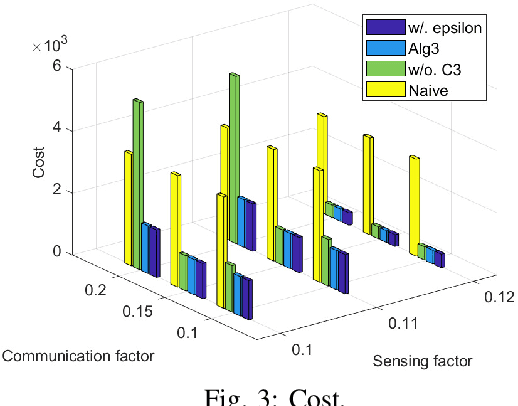
Team Coordination on Graphs with Risky Edges (\textsc{tcgre}) is a recently proposed problem, in which robots find paths to their goals while considering possible coordination to reduce overall team cost. However, \textsc{tcgre} assumes that the \emph{entire} environment is available to a \emph{homogeneous} robot team with \emph{ubiquitous} communication. In this paper, we study an extended version of \textsc{tcgre}, called \textsc{hpr-tcgre}, with three relaxations: Heterogeneous robots, Partial observability, and Realistic communication. To this end, we form a new combinatorial optimization problem on top of \textsc{tcgre}. After analysis, we divide it into two sub-problems, one for robots moving individually, another for robots in groups, depending on their communication availability. Then, we develop an algorithm that exploits real-time partial maps to solve local shortest path(s) problems, with a A*-like sub-goal(s) assignment mechanism that explores potential coordination opportunities for global interests. Extensive experiments indicate that our algorithm is able to produce team coordination behaviors in order to reduce overall cost even with our three relaxations.
Learning Coordinated Maneuver in Adversarial Environments
Jul 12, 2024



This paper aims to solve the coordination of a team of robots traversing a route in the presence of adversaries with random positions. Our goal is to minimize the overall cost of the team, which is determined by (i) the accumulated risk when robots stay in adversary-impacted zones and (ii) the mission completion time. During traversal, robots can reduce their speed and act as a `guard' (the slower, the better), which will decrease the risks certain adversary incurs. This leads to a trade-off between the robots' guarding behaviors and their travel speeds. The formulated problem is highly non-convex and cannot be efficiently solved by existing algorithms. Our approach includes a theoretical analysis of the robots' behaviors for the single-adversary case. As the scale of the problem expands, solving the optimal solution using optimization approaches is challenging, therefore, we employ reinforcement learning techniques by developing new encoding and policy-generating methods. Simulations demonstrate that our learning methods can efficiently produce team coordination behaviors. We discuss the reasoning behind these behaviors and explain why they reduce the overall team cost.
Scaling Team Coordination on Graphs with Reinforcement Learning
Mar 09, 2024This paper studies Reinforcement Learning (RL) techniques to enable team coordination behaviors in graph environments with support actions among teammates to reduce the costs of traversing certain risky edges in a centralized manner. While classical approaches can solve this non-standard multi-agent path planning problem by converting the original Environment Graph (EG) into a Joint State Graph (JSG) to implicitly incorporate the support actions, those methods do not scale well to large graphs and teams. To address this curse of dimensionality, we propose to use RL to enable agents to learn such graph traversal and teammate supporting behaviors in a data-driven manner. Specifically, through a new formulation of the team coordination on graphs with risky edges problem into Markov Decision Processes (MDPs) with a novel state and action space, we investigate how RL can solve it in two paradigms: First, we use RL for a team of agents to learn how to coordinate and reach the goal with minimal cost on a single EG. We show that RL efficiently solves problems with up to 20/4 or 25/3 nodes/agents, using a fraction of the time needed for JSG to solve such complex problems; Second, we learn a general RL policy for any $N$-node EGs to produce efficient supporting behaviors. We present extensive experiments and compare our RL approaches against their classical counterparts.