 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Evaluation of LLM World Models: A High-$T_c$ Superconductivity Case Study
Nov 05, 2025Large Language Models (LLMs) show great promise as a powerful tool for scientific literature exploration. However, their effectiveness in providing scientifically accurate and comprehensive answers to complex questions within specialized domains remains an active area of research. Using the field of high-temperature cuprates as an exemplar, we evaluate the ability of LLM systems to understand the literature at the level of an expert. We construct an expert-curated database of 1,726 scientific papers that covers the history of the field, and a set of 67 expert-formulated questions that probe deep understanding of the literature. We then evaluate six different LLM-based systems for answering these questions, including both commercially available closed models and a custom retrieval-augmented generation (RAG) system capable of retrieving images alongside text. Experts then evaluate the answers of these systems against a rubric that assesses balanced perspectives, factual comprehensiveness, succinctness, and evidentiary support. Among the six systems two using RAG on curated literature outperformed existing closed models across key metrics, particularly in providing comprehensive and well-supported answers. We discuss promising aspects of LLM performances as well as critical short-comings of all the models. The set of expert-formulated questions and the rubric will be valuable for assessing expert level performance of LLM based reasoning systems.
WinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
Sep 05, 2025We present WinT3R, a feed-forward reconstruction model capable of online prediction of precise camera poses and high-quality point maps. Previous methods suffer from a trade-off between reconstruction quality and real-time performance. To address this, we first introduce a sliding window mechanism that ensures sufficient information exchange among frames within the window, thereby improving the quality of geometric predictions without large computation. In addition, we leverage a compact representation of cameras and maintain a global camera token pool, which enhances the reliability of camera pose estimation without sacrificing efficiency. These designs enable WinT3R to achieve state-of-the-art performance in terms of online reconstruction quality, camera pose estimation, and reconstruction speed, as validated by extensive experiments on diverse datasets. Code and model are publicly available at https://github.com/LiZizun/WinT3R.
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
Multi-view Reconstruction via SfM-guided Monocular Depth Estimation
Mar 18, 2025In this paper, we present a new method for multi-view geometric reconstruction. In recent years, large vision models have rapidly developed, performing excellently across various tasks and demonstrating remarkable generalization capabilities. Some works use large vision models for monocular depth estimation, which have been applied to facilitate multi-view reconstruction tasks in an indirect manner. Due to the ambiguity of the monocular depth estimation task, the estimated depth values are usually not accurate enough, limiting their utility in aiding multi-view reconstruction. We propose to incorporate SfM information, a strong multi-view prior, into the depth estimation process, thus enhancing the quality of depth prediction and enabling their direct application in multi-view geometric reconstruction. Experimental results on public real-world datasets show that our method significantly improves the quality of depth estimation compared to previous monocular depth estimation works. Additionally, we evaluate the reconstruction quality of our approach in various types of scenes including indoor, streetscape, and aerial views, surpassing state-of-the-art MVS methods. The code and supplementary materials are available at https://zju3dv.github.io/murre/ .
Automatic Annotation Augmentation Boosts Translation between Molecules and Natural Language
Feb 10, 2025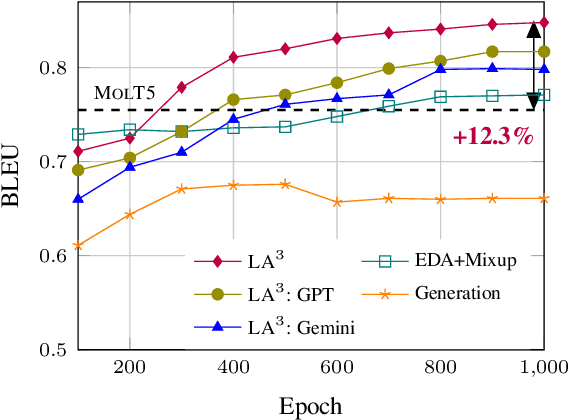
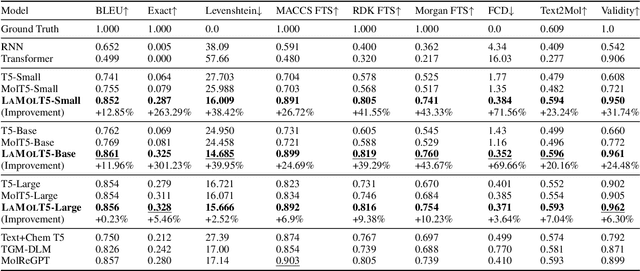
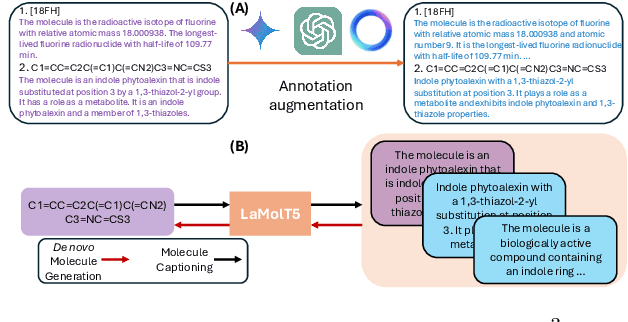
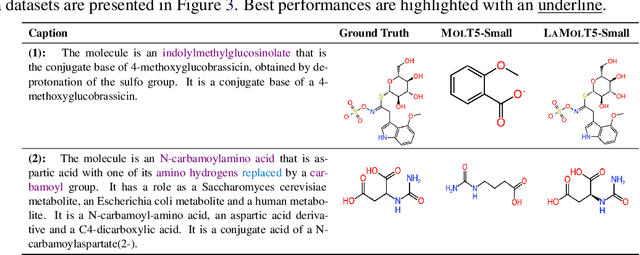
Recent advancements in AI for biological research focus on integrating molecular data with natural language to accelerate drug discovery. However, the scarcity of high-quality annotations limits progress in this area. This paper introduces LA$^3$, a Language-based Automatic Annotation Augmentation framework that leverages large language models to augment existing datasets, thereby improving AI training. We demonstrate the effectiveness of LA$^3$ by creating an enhanced dataset, LaChEBI-20, where we systematically rewrite the annotations of molecules from an established dataset. These rewritten annotations preserve essential molecular information while providing more varied sentence structures and vocabulary. Using LaChEBI-20, we train LaMolT5 based on a benchmark architecture to learn the mapping between molecular representations and augmented annotations. Experimental results on text-based *de novo* molecule generation and molecule captioning demonstrate that LaMolT5 outperforms state-of-the-art models. Notably, incorporating LA$^3$ leads to improvements of up to 301% over the benchmark architecture. Furthermore, we validate the effectiveness of LA$^3$ notable applications in *image*, *text* and *graph* tasks, affirming its versatility and utility.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
SAM-guided Graph Cut for 3D Instance Segmentation
Dec 25, 2023



This paper addresses the challenge of 3D instance segmentation by simultaneously leveraging 3D geometric and multi-view image information. Many previous works have applied deep learning techniques to 3D point clouds for instance segmentation. However, these methods often failed to generalize to various types of scenes due to the scarcity and low-diversity of labeled 3D point cloud data. Some recent works have attempted to lift 2D instance segmentations to 3D within a bottom-up framework. The inconsistency in 2D instance segmentations among views can substantially degrade the performance of 3D segmentation. In this work, we introduce a novel 3D-to-2D query framework to effectively exploit 2D segmentation models for 3D instance segmentation. Specifically, we pre-segment the scene into several superpoints in 3D, formulating the task into a graph cut problem. The superpoint graph is constructed based on 2D segmentation models, where node features are obtained from multi-view image features and edge weights are computed based on multi-view segmentation results, enabling the better generalization ability. To process the graph, we train a graph neural network using pseudo 3D labels from 2D segmentation models. Experimental results on the ScanNet, ScanNet++ and KITTI-360 datasets demonstrate that our method achieves robust segmentation performance and can generalize across different types of scenes. Our project page is available at https://zju3dv.github.io/sam_graph.
Neural 3D Scene Reconstruction with the Manhattan-world Assumption
May 18, 2022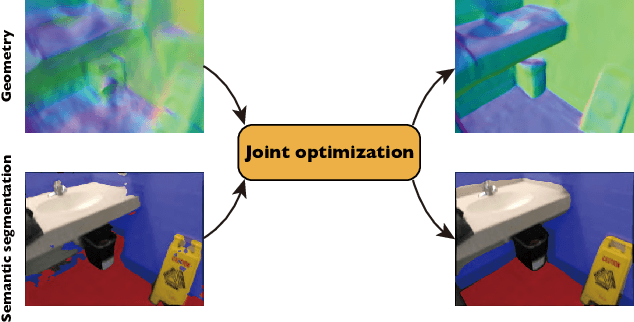
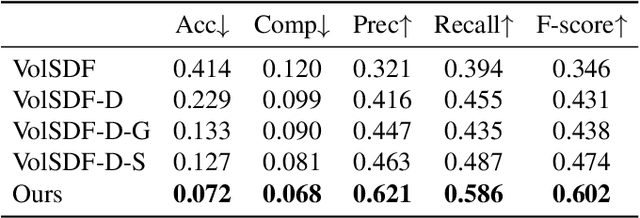
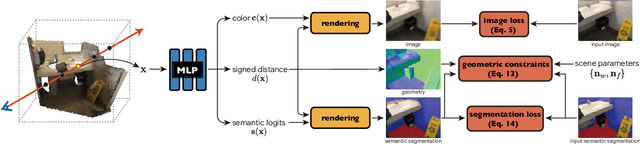
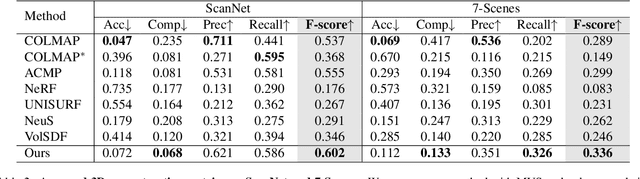
This paper addresses the challenge of reconstructing 3D indoor scenes from multi-view images. Many previous works have shown impressive reconstruction results on textured objects, but they still have difficulty in handling low-textured planar regions, which are common in indoor scenes. An approach to solving this issue is to incorporate planer constraints into the depth map estimation in multi-view stereo-based methods, but the per-view plane estimation and depth optimization lack both efficiency and multi-view consistency. In this work, we show that the planar constraints can be conveniently integrated into the recent implicit neural representation-based reconstruction methods. Specifically, we use an MLP network to represent the signed distance function as the scene geometry. Based on the Manhattan-world assumption, planar constraints are employed to regularize the geometry in floor and wall regions predicted by a 2D semantic segmentation network. To resolve the inaccurate segmentation, we encode the semantics of 3D points with another MLP and design a novel loss that jointly optimizes the scene geometry and semantics in 3D space. Experiments on ScanNet and 7-Scenes datasets show that the proposed method outperforms previous methods by a large margin on 3D reconstruction quality. The code is available at https://zju3dv.github.io/manhattan_sdf.