 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
MegaSynth: Scaling Up 3D Scene Reconstruction with Synthesized Data
Dec 18, 2024



We propose scaling up 3D scene reconstruction by training with synthesized data. At the core of our work is MegaSynth, a procedurally generated 3D dataset comprising 700K scenes - over 50 times larger than the prior real dataset DL3DV - dramatically scaling the training data. To enable scalable data generation, our key idea is eliminating semantic information, removing the need to model complex semantic priors such as object affordances and scene composition. Instead, we model scenes with basic spatial structures and geometry primitives, offering scalability. Besides, we control data complexity to facilitate training while loosely aligning it with real-world data distribution to benefit real-world generalization. We explore training LRMs with both MegaSynth and available real data. Experiment results show that joint training or pre-training with MegaSynth improves reconstruction quality by 1.2 to 1.8 dB PSNR across diverse image domains. Moreover, models trained solely on MegaSynth perform comparably to those trained on real data, underscoring the low-level nature of 3D reconstruction. Additionally, we provide an in-depth analysis of MegaSynth's properties for enhancing model capability, training stability, and generalization.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
Oct 22, 2024



We propose the Large View Synthesis Model (LVSM), a novel transformer-based approach for scalable and generalizable novel view synthesis from sparse-view inputs. We introduce two architectures: (1) an encoder-decoder LVSM, which encodes input image tokens into a fixed number of 1D latent tokens, functioning as a fully learned scene representation, and decodes novel-view images from them; and (2) a decoder-only LVSM, which directly maps input images to novel-view outputs, completely eliminating intermediate scene representations. Both models bypass the 3D inductive biases used in previous methods -- from 3D representations (e.g., NeRF, 3DGS) to network designs (e.g., epipolar projections, plane sweeps) -- addressing novel view synthesis with a fully data-driven approach. While the encoder-decoder model offers faster inference due to its independent latent representation, the decoder-only LVSM achieves superior quality, scalability, and zero-shot generalization, outperforming previous state-of-the-art methods by 1.5 to 3.5 dB PSNR. Comprehensive evaluations across multiple datasets demonstrate that both LVSM variants achieve state-of-the-art novel view synthesis quality. Notably, our models surpass all previous methods even with reduced computational resources (1-2 GPUs). Please see our website for more details: https://haian-jin.github.io/projects/LVSM/ .
RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
Oct 10, 2024



We propose RelitLRM, a Large Reconstruction Model (LRM) for generating high-quality Gaussian splatting representations of 3D objects under novel illuminations from sparse (4-8) posed images captured under unknown static lighting. Unlike prior inverse rendering methods requiring dense captures and slow optimization, often causing artifacts like incorrect highlights or shadow baking, RelitLRM adopts a feed-forward transformer-based model with a novel combination of a geometry reconstructor and a relightable appearance generator based on diffusion. The model is trained end-to-end on synthetic multi-view renderings of objects under varying known illuminations. This architecture design enables to effectively decompose geometry and appearance, resolve the ambiguity between material and lighting, and capture the multi-modal distribution of shadows and specularity in the relit appearance. We show our sparse-view feed-forward RelitLRM offers competitive relighting results to state-of-the-art dense-view optimization-based baselines while being significantly faster. Our project page is available at: https://relit-lrm.github.io/.
Neural Gaffer: Relighting Any Object via Diffusion
Jun 11, 2024



Single-image relighting is a challenging task that involves reasoning about the complex interplay between geometry, materials, and lighting. Many prior methods either support only specific categories of images, such as portraits, or require special capture conditions, like using a flashlight. Alternatively, some methods explicitly decompose a scene into intrinsic components, such as normals and BRDFs, which can be inaccurate or under-expressive. In this work, we propose a novel end-to-end 2D relighting diffusion model, called Neural Gaffer, that takes a single image of any object and can synthesize an accurate, high-quality relit image under any novel environmental lighting condition, simply by conditioning an image generator on a target environment map, without an explicit scene decomposition. Our method builds on a pre-trained diffusion model, and fine-tunes it on a synthetic relighting dataset, revealing and harnessing the inherent understanding of lighting present in the diffusion model. We evaluate our model on both synthetic and in-the-wild Internet imagery and demonstrate its advantages in terms of generalization and accuracy. Moreover, by combining with other generative methods, our model enables many downstream 2D tasks, such as text-based relighting and object insertion. Our model can also operate as a strong relighting prior for 3D tasks, such as relighting a radiance field.
OpenIllumination: A Multi-Illumination Dataset for Inverse Rendering Evaluation on Real Objects
Sep 14, 2023
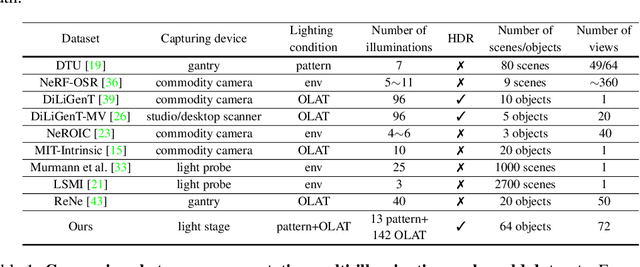

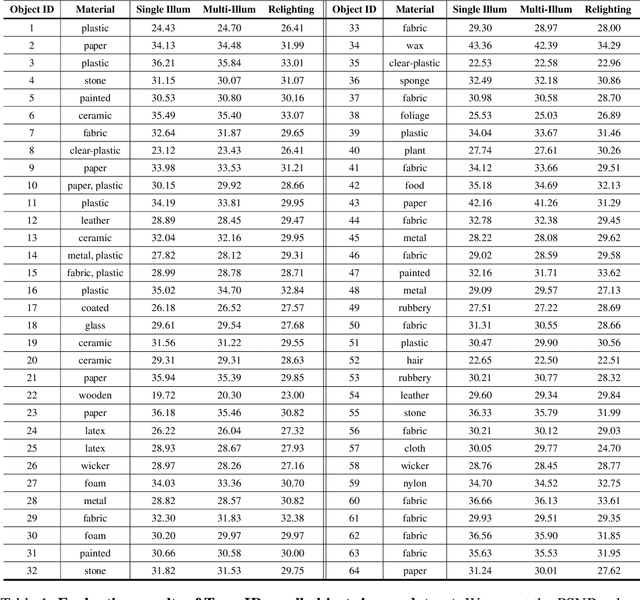
We introduce OpenIllumination, a real-world dataset containing over 108K images of 64 objects with diverse materials, captured under 72 camera views and a large number of different illuminations. For each image in the dataset, we provide accurate camera parameters, illumination ground truth, and foreground segmentation masks. Our dataset enables the quantitative evaluation of most inverse rendering and material decomposition methods for real objects. We examine several state-of-the-art inverse rendering methods on our dataset and compare their performances. The dataset and code can be found on the project page: https://oppo-us-research.github.io/OpenIllumination.
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization
Jun 29, 2023
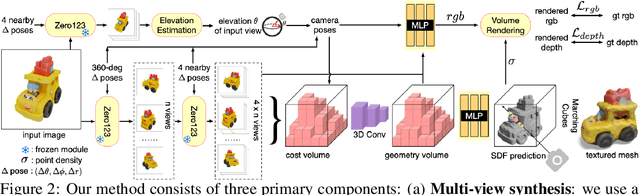
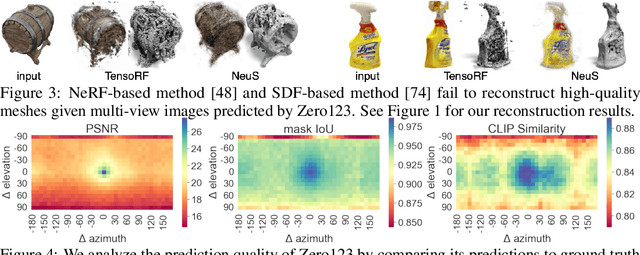

Single image 3D reconstruction is an important but challenging task that requires extensive knowledge of our natural world. Many existing methods solve this problem by optimizing a neural radiance field under the guidance of 2D diffusion models but suffer from lengthy optimization time, 3D inconsistency results, and poor geometry. In this work, we propose a novel method that takes a single image of any object as input and generates a full 360-degree 3D textured mesh in a single feed-forward pass. Given a single image, we first use a view-conditioned 2D diffusion model, Zero123, to generate multi-view images for the input view, and then aim to lift them up to 3D space. Since traditional reconstruction methods struggle with inconsistent multi-view predictions, we build our 3D reconstruction module upon an SDF-based generalizable neural surface reconstruction method and propose several critical training strategies to enable the reconstruction of 360-degree meshes. Without costly optimizations, our method reconstructs 3D shapes in significantly less time than existing methods. Moreover, our method favors better geometry, generates more 3D consistent results, and adheres more closely to the input image. We evaluate our approach on both synthetic data and in-the-wild images and demonstrate its superiority in terms of both mesh quality and runtime. In addition, our approach can seamlessly support the text-to-3D task by integrating with off-the-shelf text-to-image diffusion models.
TensoIR: Tensorial Inverse Rendering
Apr 24, 2023We propose TensoIR, a novel inverse rendering approach based on tensor factorization and neural fields. Unlike previous works that use purely MLP-based neural fields, thus suffering from low capacity and high computation costs, we extend TensoRF, a state-of-the-art approach for radiance field modeling, to estimate scene geometry, surface reflectance, and environment illumination from multi-view images captured under unknown lighting conditions. Our approach jointly achieves radiance field reconstruction and physically-based model estimation, leading to photo-realistic novel view synthesis and relighting results. Benefiting from the efficiency and extensibility of the TensoRF-based representation, our method can accurately model secondary shading effects (like shadows and indirect lighting) and generally support input images captured under single or multiple unknown lighting conditions. The low-rank tensor representation allows us to not only achieve fast and compact reconstruction but also better exploit shared information under an arbitrary number of capturing lighting conditions. We demonstrate the superiority of our method to baseline methods qualitatively and quantitatively on various challenging synthetic and real-world scenes.