 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating LLM-Based Weak Verifiers for Spatial Layout Generation
Jun 03, 2026We present a pipeline for building and aggregating task-specific, LLM-generated weak (imperfect) verifiers into a strong verifier for spatial layout domains. Given a task description, our pipeline asks an LLM to synthesize a collection of verifier programs using a layout verification DSL. Each individual LLM-generated verifier usually provides an imperfect check for a match between the layout and the corresponding task description. We show that by aggregating the responses of many such verifiers we can produce a stronger verifier. Moreover, by applying techniques from weak learning, our pipeline can learn how to aggregate the weak verifiers from a very sparse set of human labeled example layouts (about 10). We find that the strong verifiers produced by our pipeline outperform the status-quo approach of using a set of LLM judges to directly check whether a layout matches a task description, raising F1-scores by up to 7X across a variety of 3D room layout and 2D poster design tasks. We also demonstrate that verifier-guided layout generation using natural language feedback from our strong verifiers improves layout quality of a base layout generator by up to 66.2% according to a human evaluator.
Tree-Structured Shading Decomposition
Sep 13, 2023

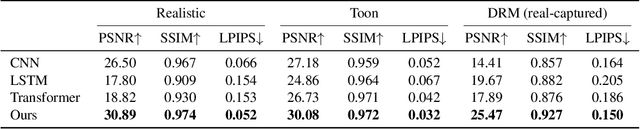
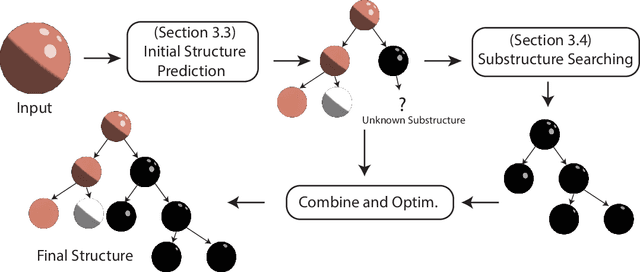
We study inferring a tree-structured representation from a single image for object shading. Prior work typically uses the parametric or measured representation to model shading, which is neither interpretable nor easily editable. We propose using the shade tree representation, which combines basic shading nodes and compositing methods to factorize object surface shading. The shade tree representation enables novice users who are unfamiliar with the physical shading process to edit object shading in an efficient and intuitive manner. A main challenge in inferring the shade tree is that the inference problem involves both the discrete tree structure and the continuous parameters of the tree nodes. We propose a hybrid approach to address this issue. We introduce an auto-regressive inference model to generate a rough estimation of the tree structure and node parameters, and then we fine-tune the inferred shade tree through an optimization algorithm. We show experiments on synthetic images, captured reflectance, real images, and non-realistic vector drawings, allowing downstream applications such as material editing, vectorized shading, and relighting. Project website: https://chen-geng.com/inv-shade-trees
Don't Judge an Object by Its Context: Learning to Overcome Contextual Bias
Apr 28, 2021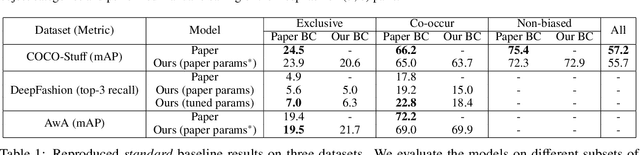

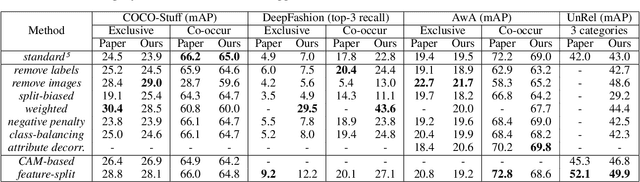
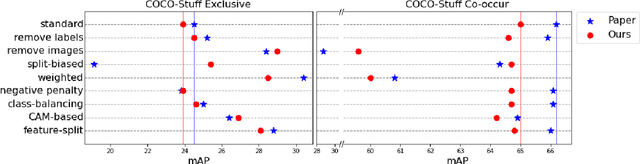
Singh et al. (2020) point out the dangers of contextual bias in visual recognition datasets. They propose two methods, CAM-based and feature-split, that better recognize an object or attribute in the absence of its typical context while maintaining competitive within-context accuracy. To verify their performance, we attempted to reproduce all 12 tables in the original paper, including those in the appendix. We also conducted additional experiments to better understand the proposed methods, including increasing the regularization in CAM-based and removing the weighted loss in feature-split. As the original code was not made available, we implemented the entire pipeline from scratch in PyTorch 1.7.0. Our implementation is based on the paper and email exchanges with the authors. We found that both proposed methods in the original paper help mitigate contextual bias, although for some methods, we could not completely replicate the quantitative results in the paper even after completing an extensive hyperparameter search. For example, on COCO-Stuff, DeepFashion, and UnRel, our feature-split model achieved an increase in accuracy on out-of-context images over the standard baseline, whereas on AwA, we saw a drop in performance. For the proposed CAM-based method, we were able to reproduce the original paper's results to within 0.5$\%$ mAP. Our implementation can be found at https://github.com/princetonvisualai/ContextualBias.
Product Manifold Learning
Oct 19, 2020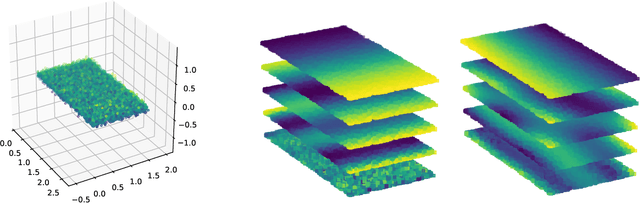

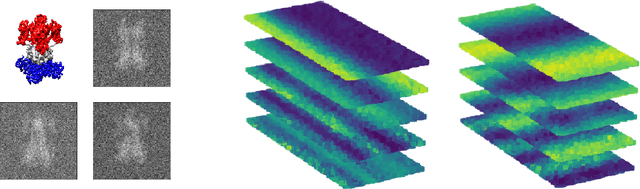
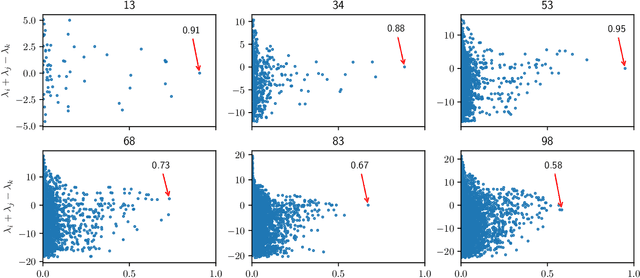
We consider problems of dimensionality reduction and learning data representations for continuous spaces with two or more independent degrees of freedom. Such problems occur, for example, when observing shapes with several components that move independently. Mathematically, if the parameter space of each continuous independent motion is a manifold, then their combination is known as a product manifold. In this paper, we present a new paradigm for non-linear independent component analysis called manifold factorization. Our factorization algorithm is based on spectral graph methods for manifold learning and the separability of the Laplacian operator on product spaces. Recovering the factors of a manifold yields meaningful lower-dimensional representations and provides a new way to focus on particular aspects of the data space while ignoring others. We demonstrate the potential use of our method for an important and challenging problem in structural biology: mapping the motions of proteins and other large molecules using cryo-electron microscopy datasets.