 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractitioners' Challenges and Perceptions of CI Build Failure Predictions at Atlassian
Feb 15, 2024



Continuous Integration (CI) build failures could significantly impact the software development process and teams, such as delaying the release of new features and reducing developers' productivity. In this work, we report on an empirical study that investigates CI build failures throughout product development at Atlassian. Our quantitative analysis found that the repository dimension is the key factor influencing CI build failures. In addition, our qualitative survey revealed that Atlassian developers perceive CI build failures as challenging issues in practice. Furthermore, we found that the CI build prediction can not only provide proactive insight into CI build failures but also facilitate the team's decision-making. Our study sheds light on the challenges and expectations involved in integrating CI build prediction tools into the Bitbucket environment, providing valuable insights for enhancing CI processes.
Rademacher Observations, Private Data, and Boosting
Apr 02, 2015
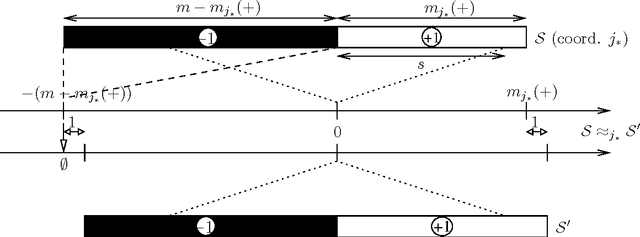

The minimization of the logistic loss is a popular approach to batch supervised learning. Our paper starts from the surprising observation that, when fitting linear (or kernelized) classifiers, the minimization of the logistic loss is \textit{equivalent} to the minimization of an exponential \textit{rado}-loss computed (i) over transformed data that we call Rademacher observations (rados), and (ii) over the \textit{same} classifier as the one of the logistic loss. Thus, a classifier learnt from rados can be \textit{directly} used to classify \textit{observations}. We provide a learning algorithm over rados with boosting-compliant convergence rates on the \textit{logistic loss} (computed over examples). Experiments on domains with up to millions of examples, backed up by theoretical arguments, display that learning over a small set of random rados can challenge the state of the art that learns over the \textit{complete} set of examples. We show that rados comply with various privacy requirements that make them good candidates for machine learning in a privacy framework. We give several algebraic, geometric and computational hardness results on reconstructing examples from rados. We also show how it is possible to craft, and efficiently learn from, rados in a differential privacy framework. Tests reveal that learning from differentially private rados can compete with learning from random rados, and hence with batch learning from examples, achieving non-trivial privacy vs accuracy tradeoffs.