 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRademacher Observations, Private Data, and Boosting
Paper and Code
Apr 02, 2015
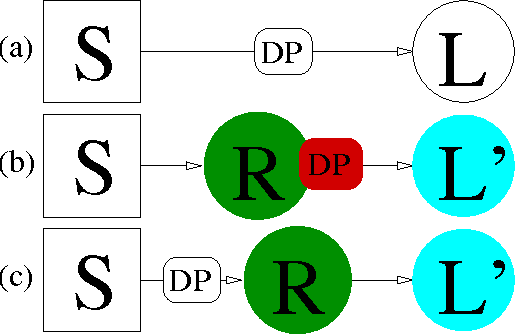
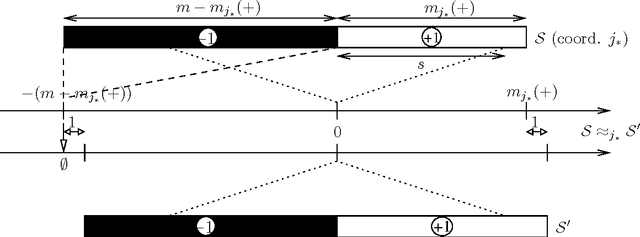

The minimization of the logistic loss is a popular approach to batch supervised learning. Our paper starts from the surprising observation that, when fitting linear (or kernelized) classifiers, the minimization of the logistic loss is \textit{equivalent} to the minimization of an exponential \textit{rado}-loss computed (i) over transformed data that we call Rademacher observations (rados), and (ii) over the \textit{same} classifier as the one of the logistic loss. Thus, a classifier learnt from rados can be \textit{directly} used to classify \textit{observations}. We provide a learning algorithm over rados with boosting-compliant convergence rates on the \textit{logistic loss} (computed over examples). Experiments on domains with up to millions of examples, backed up by theoretical arguments, display that learning over a small set of random rados can challenge the state of the art that learns over the \textit{complete} set of examples. We show that rados comply with various privacy requirements that make them good candidates for machine learning in a privacy framework. We give several algebraic, geometric and computational hardness results on reconstructing examples from rados. We also show how it is possible to craft, and efficiently learn from, rados in a differential privacy framework. Tests reveal that learning from differentially private rados can compete with learning from random rados, and hence with batch learning from examples, achieving non-trivial privacy vs accuracy tradeoffs.