 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2GQL-Bench: A Text to Graph Query Language Benchmark [Experiment, Analysis & Benchmark]
Feb 12, 2026Graph models are fundamental to data analysis in domains rich with complex relationships. Text-to-Graph-Query-Language (Text-to-GQL) systems act as a translator, converting natural language into executable graph queries. This capability allows Large Language Models (LLMs) to directly analyze and manipulate graph data, posi-tioning them as powerful agent infrastructures for Graph Database Management System (GDBMS). Despite recent progress, existing datasets are often limited in domain coverage, supported graph query languages, or evaluation scope. The advancement of Text-to-GQL systems is hindered by the lack of high-quality benchmark datasets and evaluation methods to systematically compare model capabilities across different graph query languages and domains. In this work, we present Text2GQL-Bench, a unified Text-to-GQL benchmark designed to address these limitations. Text2GQL-Bench couples a multi-GQL dataset that has 178,184 (Question, Query) pairs spanning 13 domains, with a scalable construction framework that generates datasets in different domains, question abstraction levels, and GQLs with heterogeneous resources. To support compre-hensive assessment, we introduce an evaluation method that goes beyond a single end-to-end metric by jointly reporting grammatical validity, similarity, semantic alignment, and execution accuracy. Our evaluation uncovers a stark dialect gap in ISO-GQL generation: even strong LLMs achieve only at most 4% execution accuracy (EX) in zero-shot settings, though a fixed 3-shot prompt raises accuracy to around 50%, the grammatical validity remains lower than 70%. Moreover, a fine-tuned 8B open-weight model reaches 45.1% EX, and 90.8% grammatical validity, demonstrating that most of the performance jump is unlocked by exposure to sufficient ISO-GQL examples.
Understanding and Guiding Layer Placement in Parameter-Efficient Fine-Tuning of Large Language Models
Feb 03, 2026As large language models (LLMs) continue to grow, the cost of full-parameter fine-tuning has made parameter-efficient fine-tuning (PEFT) the default strategy for downstream adaptation. Constraints from inference latency in scalable serving and fine-tuning cost in edge or rapid-deployment settings make the choice of which layers to fine-tune unavoidable. Yet current practice typically applies PEFT uniformly across all layers, with limited understanding or leverage of layer selection. This paper develops a unified projected residual view of PEFT on top of a frozen base model. Under a local quadratic approximation, layerwise adaptation is governed by three quantities: (i) the projected residual norm (resnorm), which measures how much correctable bias a layer can capture; (ii) the activation energy, which determines feature conditioning; and (iii) layer coupling, which quantifies how strongly residuals interact across layers. We show that, for squared loss and linear adapters, the resnorm equals a normalized gradient norm, activation energy controls ill-conditioning and noise amplification, and weak coupling yields approximately additive layerwise contributions. Building on these insights, we introduce the Layer Card, a reusable diagnostic that summarizes residual signal strength, compute cost, and performance for each layer of a given model. With an identical model and LoRA configuration, Layer Card-guided placement refines the choice of adapted layers to flexibly prioritize different objectives, such as maximizing performance or reducing fine-tuning cost. Moreover, on Qwen3-8B, we show that selectively adapting a subset of layers can achieve performance close to full-layer LoRA while substantially reducing fine-tuning cost and the number of adapter-augmented layers during inference, offering a more cost-performance-aware alternative to full-layer insertion.
Micro-Act: Mitigate Knowledge Conflict in Question Answering via Actionable Self-Reasoning
Jun 05, 2025Retrieval-Augmented Generation (RAG) systems commonly suffer from Knowledge Conflicts, where retrieved external knowledge contradicts the inherent, parametric knowledge of large language models (LLMs). It adversely affects performance on downstream tasks such as question answering (QA). Existing approaches often attempt to mitigate conflicts by directly comparing two knowledge sources in a side-by-side manner, but this can overwhelm LLMs with extraneous or lengthy contexts, ultimately hindering their ability to identify and mitigate inconsistencies. To address this issue, we propose Micro-Act a framework with a hierarchical action space that automatically perceives context complexity and adaptively decomposes each knowledge source into a sequence of fine-grained comparisons. These comparisons are represented as actionable steps, enabling reasoning beyond the superficial context. Through extensive experiments on five benchmark datasets, Micro-Act consistently achieves significant increase in QA accuracy over state-of-the-art baselines across all 5 datasets and 3 conflict types, especially in temporal and semantic types where all baselines fail significantly. More importantly, Micro-Act exhibits robust performance on non-conflict questions simultaneously, highlighting its practical value in real-world RAG applications.
TRACE: Intra-visit Clinical Event Nowcasting via Effective Patient Trajectory Encoding
Mar 29, 2025Electronic Health Records (EHR) have become a valuable resource for a wide range of predictive tasks in healthcare. However, existing approaches have largely focused on inter-visit event predictions, overlooking the importance of intra-visit nowcasting, which provides prompt clinical insights during an ongoing patient visit. To address this gap, we introduce the task of laboratory measurement prediction within a hospital visit. We study the laboratory data that, however, remained underexplored in previous work. We propose TRACE, a Transformer-based model designed for clinical event nowcasting by encoding patient trajectories. TRACE effectively handles long sequences and captures temporal dependencies through a novel timestamp embedding that integrates decay properties and periodic patterns of data. Additionally, we introduce a smoothed mask for denoising, improving the robustness of the model. Experiments on two large-scale electronic health record datasets demonstrate that the proposed model significantly outperforms previous methods, highlighting its potential for improving patient care through more accurate laboratory measurement nowcasting. The code is available at https://github.com/Amehi/TRACE.
NVR: Vector Runahead on NPUs for Sparse Memory Access
Feb 19, 2025Deep Neural Networks are increasingly leveraging sparsity to reduce the scaling up of model parameter size. However, reducing wall-clock time through sparsity and pruning remains challenging due to irregular memory access patterns, leading to frequent cache misses. In this paper, we present NPU Vector Runahead (NVR), a prefetching mechanism tailored for NPUs to address cache miss problems in sparse DNN workloads. Rather than optimising memory patterns with high overhead and poor portability, NVR adapts runahead execution to the unique architecture of NPUs. NVR provides a general micro-architectural solution for sparse DNN workloads without requiring compiler or algorithmic support, operating as a decoupled, speculative, lightweight hardware sub-thread alongside the NPU, with minimal hardware overhead (under 5%). NVR achieves an average 90% reduction in cache misses compared to SOTA prefetching in general-purpose processors, delivering 4x average speedup on sparse workloads versus NPUs without prefetching. Moreover, we investigate the advantages of incorporating a small cache (16KB) into the NPU combined with NVR. Our evaluation shows that expanding this modest cache delivers 5x higher performance benefits than increasing the L2 cache size by the same amount.
Towards Effective Top-N Hamming Search via Bipartite Graph Contrastive Hashing
Aug 17, 2024



Searching on bipartite graphs serves as a fundamental task for various real-world applications, such as recommendation systems, database retrieval, and document querying. Conventional approaches rely on similarity matching in continuous Euclidean space of vectorized node embeddings. To handle intensive similarity computation efficiently, hashing techniques for graph-structured data have emerged as a prominent research direction. However, despite the retrieval efficiency in Hamming space, previous studies have encountered catastrophic performance decay. To address this challenge, we investigate the problem of hashing with Graph Convolutional Network for effective Top-N search. Our findings indicate the learning effectiveness of incorporating hashing techniques within the exploration of bipartite graph reception fields, as opposed to simply treating hashing as post-processing to output embeddings. To further enhance the model performance, we advance upon these findings and propose Bipartite Graph Contrastive Hashing (BGCH+). BGCH+ introduces a novel dual augmentation approach to both intermediate information and hash code outputs in the latent feature spaces, thereby producing more expressive and robust hash codes within a dual self-supervised learning paradigm. Comprehensive empirical analyses on six real-world benchmarks validate the effectiveness of our dual feature contrastive learning in boosting the performance of BGCH+ compared to existing approaches.
Before Generation, Align it! A Novel and Effective Strategy for Mitigating Hallucinations in Text-to-SQL Generation
May 24, 2024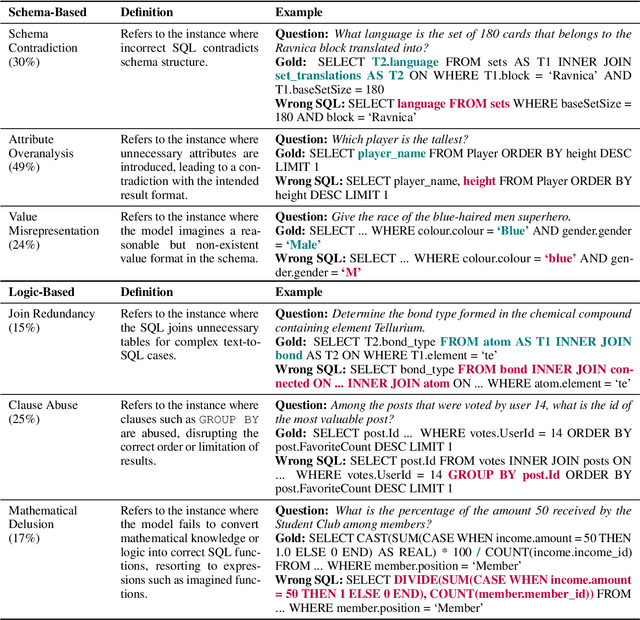
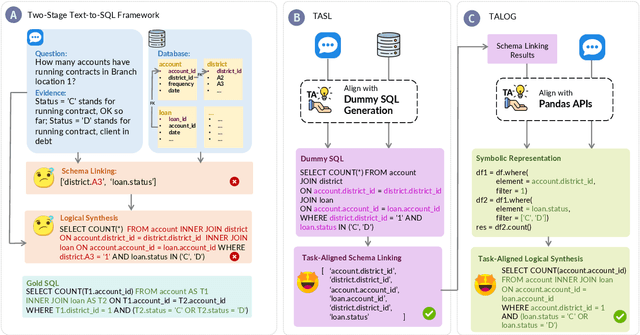
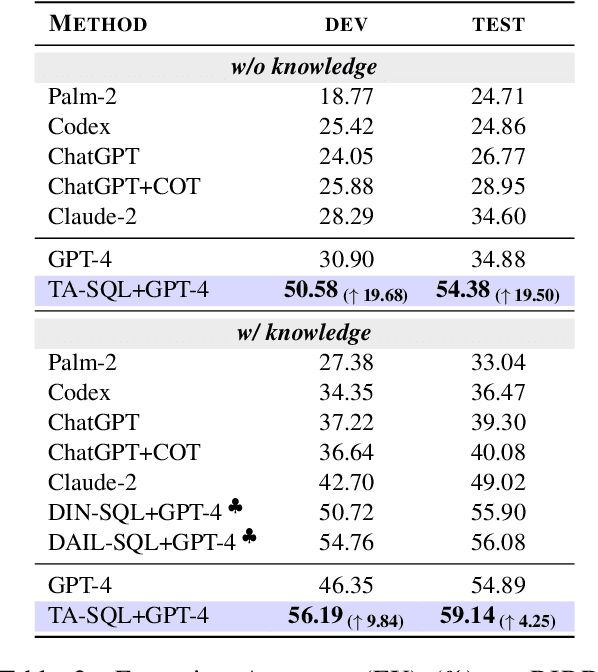
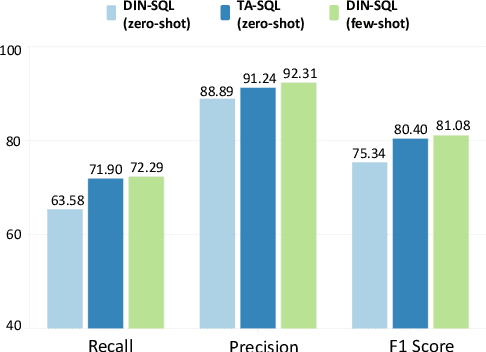
Large Language Models (LLMs) driven by In-Context Learning (ICL) have significantly improved the performance of text-to-SQL. Previous methods generally employ a two-stage reasoning framework, namely 1) schema linking and 2) logical synthesis, making the framework not only effective but also interpretable. Despite these advancements, the inherent bad nature of the generalization of LLMs often results in hallucinations, which limits the full potential of LLMs. In this work, we first identify and categorize the common types of hallucinations at each stage in text-to-SQL. We then introduce a novel strategy, Task Alignment (TA), designed to mitigate hallucinations at each stage. TA encourages LLMs to take advantage of experiences from similar tasks rather than starting the tasks from scratch. This can help LLMs reduce the burden of generalization, thereby mitigating hallucinations effectively. We further propose TA-SQL, a text-to-SQL framework based on this strategy. The experimental results and comprehensive analysis demonstrate the effectiveness and robustness of our framework. Specifically, it enhances the performance of the GPT-4 baseline by 21.23% relatively on BIRD dev and it yields significant improvements across six models and four mainstream, complex text-to-SQL benchmarks.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024



Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.
Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
May 04, 2023



Text-to-SQL parsing, which aims at converting natural language instructions into executable SQLs, has gained increasing attention in recent years. In particular, Codex and ChatGPT have shown impressive results in this task. However, most of the prevalent benchmarks, i.e., Spider, and WikiSQL, focus on database schema with few rows of database contents leaving the gap between academic study and real-world applications. To mitigate this gap, we present Bird, a big benchmark for large-scale database grounded in text-to-SQL tasks, containing 12,751 pairs of text-to-SQL data and 95 databases with a total size of 33.4 GB, spanning 37 professional domains. Our emphasis on database values highlights the new challenges of dirty database contents, external knowledge between NL questions and database contents, and SQL efficiency, particularly in the context of massive databases. To solve these problems, text-to-SQL models must feature database value comprehension in addition to semantic parsing. The experimental results demonstrate the significance of database values in generating accurate text-to-SQLs for big databases. Furthermore, even the most effective text-to-SQL models, i.e. ChatGPT, only achieves 40.08% in execution accuracy, which is still far from the human result of 92.96%, proving that challenges still stand. Besides, we also provide an efficiency analysis to offer insights into generating text-to-efficient-SQLs that are beneficial to industries. We believe that BIRD will contribute to advancing real-world applications of text-to-SQL research. The leaderboard and source code are available: https://bird-bench.github.io/.
Graphix-T5: Mixing Pre-Trained Transformers with Graph-Aware Layers for Text-to-SQL Parsing
Jan 18, 2023



The task of text-to-SQL parsing, which aims at converting natural language questions into executable SQL queries, has garnered increasing attention in recent years, as it can assist end users in efficiently extracting vital information from databases without the need for technical background. One of the major challenges in text-to-SQL parsing is domain generalization, i.e., how to generalize well to unseen databases. Recently, the pre-trained text-to-text transformer model, namely T5, though not specialized for text-to-SQL parsing, has achieved state-of-the-art performance on standard benchmarks targeting domain generalization. In this work, we explore ways to further augment the pre-trained T5 model with specialized components for text-to-SQL parsing. Such components are expected to introduce structural inductive bias into text-to-SQL parsers thus improving model's capacity on (potentially multi-hop) reasoning, which is critical for generating structure-rich SQLs. To this end, we propose a new architecture GRAPHIX-T5, a mixed model with the standard pre-trained transformer model augmented by some specially-designed graph-aware layers. Extensive experiments and analysis demonstrate the effectiveness of GRAPHIX-T5 across four text-to-SQL benchmarks: SPIDER, SYN, REALISTIC and DK. GRAPHIX-T5 surpass all other T5-based parsers with a significant margin, achieving new state-of-the-art performance. Notably, GRAPHIX-T5-large reach performance superior to the original T5-large by 5.7% on exact match (EM) accuracy and 6.6% on execution accuracy (EX). This even outperforms the T5-3B by 1.2% on EM and 1.5% on EX.